jingzhiMo
jingzhiMo

这次阅读的redux的版本是`4.x`的[版本](https://github.com/reduxjs/redux/tree/4.x),为啥不是最新的呢?因为最新的redux使用typescript来重写了,变化不是特别大,而typescript会有很多的函数类型定义;另一方面,对js的熟练度肯定比ts要好,理解起来也会相对容易一点,还有这次阅读源码的目的是为了了解整个redux的工作流程。redux的源码非常精简,很适合源码的阅读与学习。在阅读之前,对redux有一定的使用会带来更好的效果,一边看一边反思平常所写的内容。下面就开始吧: ## 目录 下面的内容是项目的src目录结构 ```plain # src -- utils/ -- actionTypes.js -- isPlainObject.js -- warning.js -- applyMiddleware.js -- bindActionCreators.js -- combineReducers.js -- compose.js -- createStore.js -- index.js ``` 项目的文件非常的少,主要逻辑也是在`src`直接目录下的文件,先做个热身,对简单的`utils`文件夹入手,这是一些通用的工具方法: ###...
前阵子去回顾一下`tree-shaking`的简单原理,然后*顺藤摸瓜*,逐步把之前不清晰或者不明白的打包基础工具梳理了一遍。 ## tree-shaking tree-shaking 就是可以把一些没有用到的代码在打包的过程剔除,进而减少最终的代码体积,例如: ```js // a.js export const foo = () => {} export const bar = () => {} // b.js import { foo } from './a.js'...
最近打算给WEB应用收集一些打开的相关数据,所以需要对`performance`的api进行熟悉。收集完数据之后,后续有什么故障或者优化的手段,就可以使用数据说话,而不是说,“加入了XX的优化,快了很多”,“服务器负载过高,影响了XX的部分的解析时间”。 接下来主要分析`performance.timing`对象所在属性,对于`performance`对象的其他属性不做详细处理。这篇文章的也没什么特别的地方,只是在面向谷歌研究的时候,发现很多关于`performance.timing`的描述都很模棱两可,而且比较简单,对于实际情况应用与影响因素不明确,所以做了部分测试。 ## performance.timing 基础介绍 `performance.timing`对象的数据是什么?该对象下包含页面打开的各种的时间戳,例如:DNS 耗费时间,TCP 连接时间等;这些时间不通过`performance`的api,暂时无法获取这些相对底层的时间。这个包含以下字段: ```plain navigationStart unloadEventStart unloadEventEnd redirectStart redirectEnd fetchStart domainLookupStart domainLookupEnd connectStart connectEnd secureConnectionStart requestStart responseStart responseEnd domLoading domInteractive domContentLoadedEventStart domContentLoadedEventEnd domComplete loadEventStart loadEventEnd...
## 背景 网站的首页和部分介绍页面需要预渲染,为了更好的SEO;而网站的dashboard的相关页面则保持原来的SPA处理。后续生产环境的文件构建需要放到ci统一处理。 ## 使用工具 * [prerender-spa-plugin]() * [puppeteer]() 现在使用`prerender-spa-plugin`的插件用来把部分静态页面预渲染,这个插件是依赖`puppeteer`的工具,`puppeteer`工具是需要下载一个`chromium`的浏览器。如果没有梯子是没办法下载的,下载安装包的大小大概在70M左右。 `puppeteer`从`1.7.0`版本开始就把`puppeteer-core`的包分离出来,如果需要单独测试的话,仅下载这个包就好了。但是`prerender-spa-plugin`插件是依赖`puppeteer`的包,所以需要设置npm的环境变量才能能够跳过下载浏览器,在安装`npm install`之前,需要在项目的根目录新建文件`.npmrc`或者往里面追加内容,内容是: ```bash puppeteer_skip_chromium_download=true ``` ## 使用基础例子 后面所使用的代码,均基于[官方的例子](https://github.com/chrisvfritz/prerender-spa-plugin/tree/master/examples/vue2-webpack-router)进行更改 ### webpack 配置 在webpack的配置当中,生产环境的plugins的数组需要加入下面的实例: ```js // 引入对应的插件 const PrerenderSPAPlugin = require('prerender-spa-plugin') const...
咳咳...2019年叫觉醒之年好像有点夸张,接下来是今年一年的小总结或者概览吧,逻辑比较乱。大家不嫌弃的话,可以当讲故事那样子看一下。 2019年对于我个人来说,注定是一个失败的年份。年前定下的目标,大部分都没有达成,最主线的目标也是在一次又一次的失败当中渐渐错过。或者说因为最主线的目标没有达成,导致其他可能已经实现的小目标也变得暗然。 在工作方面,2019前半年都一直处于一个不断迭代的过程;着手一个新开的项目,这个项目算是我第一个完全主导的项目中,从最开始的技术选型、基础搭建、研发推进、上线部署整一个过程都在努力推动中。也算是在之前的工作中的一个提高吧。 在这个项目的初期,我也是挺有冲劲的,毕竟vue的技术栈在这之前没有做过一个完整的项目,在这个9102年里面,说出去真的惭愧。因为在这个项目之前,我都是使用`ng1.x`的框架,所以已经感觉到已经跟主流的技术栈脱节了。但是因为之前实在太安逸了,导致对自己的思考不足。回头看2018年,这一年基本我都是在为了公司的业务而奋斗,在技术上面的提升真的很少,学习的方向也是十分的不定向。差不多这里学一下,那里学一下,最后真的是没有一个是学得好的。 当然,如果往好的方向想的话,2018年的软能力提高还是不错的,例如一些沟通协作的处理方式。但是好像这种能力并没有得到“人们”的重视。还是这种能力很容易就能学得到呢?或许看起来很虚吧,很难说服别人;又或者这对于程序员来说只是一个小的加分项?好了,这里又感叹了一下2018年的不好;说回来19年;当我推动完这个项目的时候,发现到后期并没有什么特别厉害的东西可以弄;而个人也是在慢慢的在准备去更好的平台的过程,补充一些平常忽略的知识。在这个过程也是通过列一些计划,强有目的性去学习;所以在这里也感受到有计划有目的的学习,大大的增强了效率(为什么之前就没有这样子去做...)。到了某个时间点,我觉得我已经达到一个计划完成90%的时候,这个时候我也有去做一些尝试;而这些尝试,都失败了;尽管这些尝试都是选比较困难的来,这样子对我的打击是非常非常的大;因为有好些机会对于我来说,只是差了毫厘;到成功真的只差一点点,而这一点点让我感到非常的不甘。在这里除了核心竞争力之外,我觉得我缺少的是一个表达自己能力的一个能力;对于有些会的,因为表达的问题,没有表达清楚而导致最后的失败;但是日常对于这些会的问题,简直就是易如反掌;或许这种表达自己所拥有的能力(当然不是通过吹牛)也是一种需要不断提升的能力。对于这些失败,也是在不断的反思;这个反思促成了今年比较靠后的时间不断去完善自己的学习计划与学习能力;而且最重要的是,通过这些失败,知道自己要的是什么,懂得如何去分解这个问题,然后寻找破解方法。一扫之前的迷茫感觉;并且对于身边的抗压能力也懂得如何去化解。对于自己的短期内的职业生涯规划,还有生活规划也有一定的计划。所以对今年称之为觉醒之年,哈哈,感觉自己有点中二了。 今年也参加过前端的conf,从这个conf可以说是受益匪浅;因为conf的内容基本都是一些别人沉淀过,得到不错的成果才用来展现,而通过参加聆听,可以站在他们的肩膀上面获取知识,对于工作中的启发非常明显。并且对业界的一些发展方向也有一定的了解,希望今后可以尽量参加部分质量高的conf,对于眼界的提高十分有帮助。对了,今年还有做的还不错的是,开始慢慢对外输出一些技术文章还有开源的工具,尽管文章质量可能不算非常高,但是对于日常的总结能力和调研能力提高都不错的;对于开源的工具来说,或许现在解决的情景还不算非常多,不过更多接触的话,会慢慢发现,以前不知道写什么工具的想法是因为做的太少,只要写的越多,发掘的东西也越多。毕竟`talk is cheap. show me the code.` 当然,生活上不止只有工作,也有多方面发展。今年年初定的其中一个目标就是:保持身体健康。但是实际上今年身体状况反而变得不好了,各种小毛病都找上门来,尽管每周都保持一定的运动量。或许因为今年在很长一段时间内,整个人都处于一个高压的状态,每天对于自己的压力都很大,所以个人精神方面经常都是比较低迷,之前一直都保持不错的午觉,现在一周能够两天睡着就不错了;头发掉的速度也相应的增快了。。。好惨。现在慢慢逐渐沉浸在紧凑的学习计划,焦虑感也有一点降低。想起今天去一趟医院检查一下,因为最近发现血压好像不太正常。然后医生说了一些东西,查过血压和心电图;得出的结论是:不适与疲劳。内心看了真是一个苦笑。或许真的是这样子,也是一件好事吧,后面好好休息一下。除了这些不好的,也有一个还不错的,就是学会了游泳;这个总体来说还是挺满意的;解决了20多年来的一个难题,算是今年在生活上一个为数不多的闪光点吧。 展望,还记得上一年发了朋友圈说希望2019能够变得好一点。那是因为上一年是真的没有底气,所以变得那么的卑微。通过2019年觉醒,我觉得今年不是“2020年,请对我好一点”。而是“2020年,我会对你好一点。”。经过长时间的积累,相信也必须今年能够得到想要结果;工作与生活都需要运行在期望的轨道上。工作中找到一个比较top的平台,维持自己的写blog与开源的习惯;持续提升技术,主要提升深度,成为“砖家”。体重希望可以突破并维持55kg。保持运动状态,保持健康的体魄。学习一定理财计划。 简简单单写了一下,也不算是什么总结吧,只是把最近的感受写一下。给自己立个flag。 完。明年的目标终将实现。
最近在开发的过程中,发现部署的过程非常非常的慢,可能一个跑完完整的任务理想情况下都需要10分钟左右,如果同时任务多一点,甚至到20分钟,非常影响工作效率;尽管可以在部署任务的时候摸鱼,当然这个时候可以切换去做其他任~但是长此下去不行鸭。 ## 分析 ci/cd中有很多job,得分析这些job的过程,卡在哪一步,才能针对过程进行优化。通常来说,一个job的“主任务”,也就是任务的核心过程,例如通过webpack构建网站资源,连接到服务器,发送文件等;这部分处理本身“主任务”之外,可能还跟对应服务器硬件资源较大关联,暂时这些就不列在这次的优化方向。 那么除了这些主任务之外,还涉及一些通用的,例如`cache`与`artifacts`,这些也是比较影响job的速度,所以这次处理方向也是这个。 ## 优化结果 提前说一下优化的结果: 优化前,job数量2-3个的时候,大概10-20分钟;job数量在5-6的时候,需要25分钟左右; 优化后,job数量2-3个的时候,大概2-3分钟;job数量在5-6个的时候,大概5分钟左右; 可以对比,大概下降的达到**70%到90%**左右,极大提高开发效率。 ## 优化手段 ### 更改`cache`影响范围 这个其中一个原因是原有的`cache`策略设置不好,设置了全局的`cache`策略: ```yml # .gitlab-ci.yml cache: key: xx path: - node_modules # job1 job1: # job2...
这篇文章主要梳理一下现在http缓存相关的header,还有http2的特点与简单原理分析。 ## http缓存 先讲一下缓存,用于协商缓存的请求头有很多个,其中比较常用是以下几个: 1. cache-control (通用首部) 2. expired (响应首部) 3. pragma (通用首部) 4. etag (响应首部) && if-none-match (请求首部) 5. last-modified (响应首部) && if-modified-since (请求首部) *通用首部指既能够在请求首部出现,也可以在响应首部出现* 这里先说以下浏览器缓存判断逻辑 ```js function mockCache...
这篇文章主要来聊一下事件循环;什么是事件循环?通常情况下,js是单线程处理主要任务,而除了同步逻辑之外,还有大部分异步逻辑;事件循环的规则就用于协调同步与异步任务的调用。js的事件循环在浏览器与nodejs不太一样,后面会展开说一下。 异步任务分类比较多,在浏览器端,有DOM事件,也有定时器,`Promise`等。在nodejs,也有`process.nextTick`与`setImmediate`等。下面会逐步介绍一下 ## 浏览器 先从一个比较简单的例子入手,该例子运行于浏览器端: ```js setTimeout(() => { console.log('timeout') }, 0) new Promise((resolve) => { console.log('before resolve') resolve() }) .then(() => { console.log('after resolve') }) const now = Date.now()...
下面从源码简单分析一下vuex的启动与使用过程,适合对`vuex`有使用经验看一下;适当回顾,也是对提高很有帮助。 先看一下简略初始化的流程,后面看完再回头过一遍: 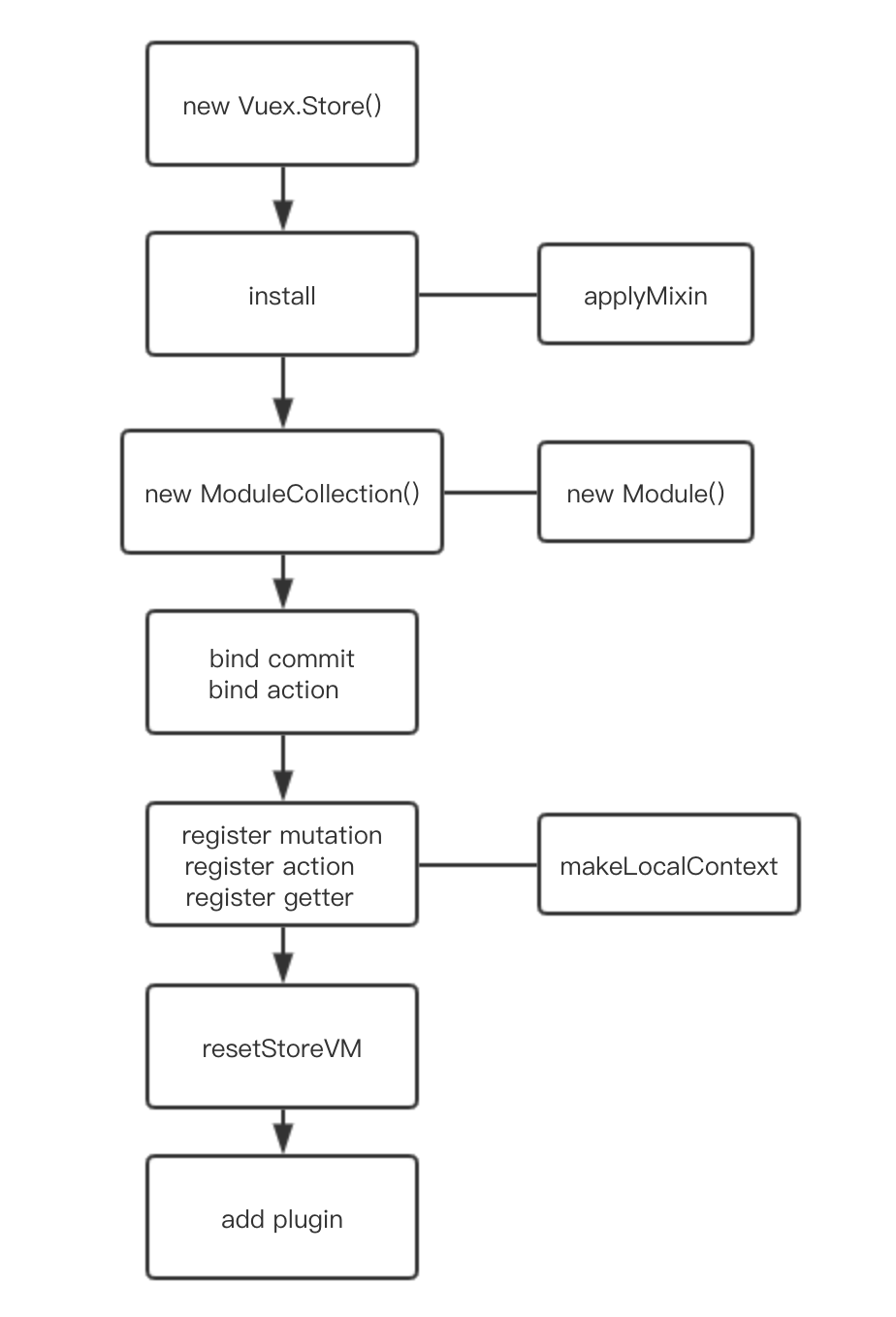 *图中左边是主要的流程,右边是对某个流程的重要关联,也属于主流程* 在`src`目录下的`index.js`文件主要内容是: ```js export default { Store, install, version: '__VERSION__', mapState, mapMutations, mapGetters, mapActions, createNamespacedHelpers } ``` 其中`mapXxx`这些是工具函数,暂不展开说明;`vuex`的主要内容是在`Store`中,就从这个文件为入口进行分析: ## 安装挂载store ```js // store.js export class Store {...
`msn-cache`是最近弄的一个小工具,用于处理`memory`,`storage`,`netword`数据,`msn`也就是这三个单词的首字母。获取缓存数据处理过程的优先级是`memory` => `storage` => `network`。至于怎样降级获取数据的详细处理,可以往下看一下 ## msn-cache 处理过程 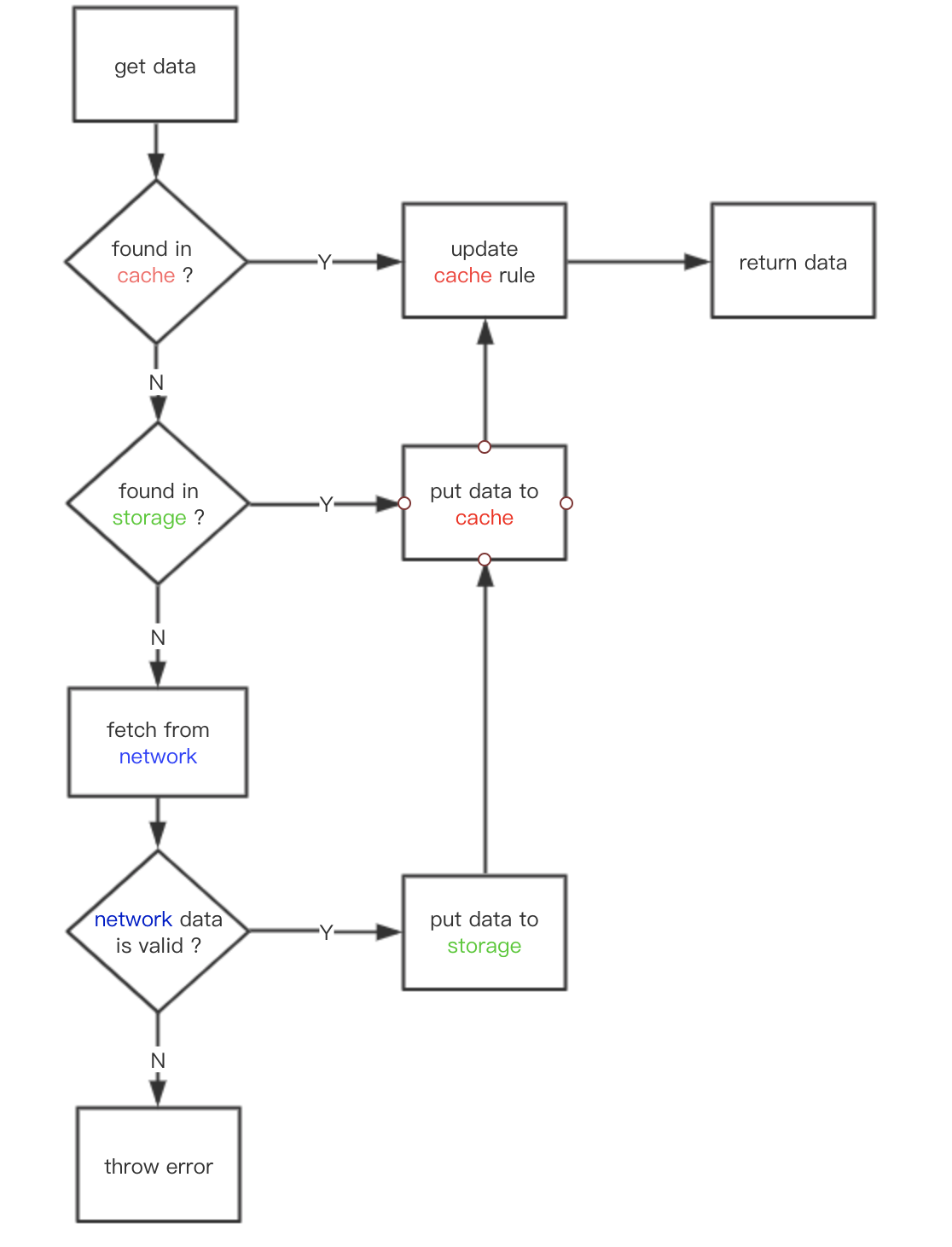 在降级处理过程,主要有两个难点: 1. cache 的算法处理 2. storage数据处理 ### cache 的算法处理 目前支持的算法有`LRU`与`FIFO`那么怎么验证这个算法是正确的?`LRU`算法相对比较复杂,这边是通过在leetcode提交验证,若通过leetcode的验证,则表明通过。leetcode [题目地址](https://leetcode.com/problems/lru-cache/),但是leetcode暂时不支持ts语法,因此要把ts转换为js,再粘贴到leetcode运行。`LRU`的运行效率对比同语言还算不错。`FIFO`算法在leetcode没有找到相关题目,暂时只能手工测试,后续考虑加上单元测试。  简单使用例子: ```js import MCache from 'msn-cache' const mc =...