jingzhiMo.github.io
 jingzhiMo.github.io copied to clipboard
jingzhiMo.github.io copied to clipboard
http缓存与http2特性浅析
这篇文章主要梳理一下现在http缓存相关的header,还有http2的特点与简单原理分析。
http缓存
先讲一下缓存,用于协商缓存的请求头有很多个,其中比较常用是以下几个:
- cache-control (通用首部)
- expired (响应首部)
- pragma (通用首部)
- etag (响应首部) && if-none-match (请求首部)
- last-modified (响应首部) && if-modified-since (请求首部)
通用首部指既能够在请求首部出现,也可以在响应首部出现
这里先说以下浏览器缓存判断逻辑
function mockCache () {
// 浏览器本地缓存命中
if (cacheHit) {
return cache
}
// 缓存没命中,去检测新鲜度
if (checkFreshness) {
// 缓存仍然有效
return cache
}
return newResponse
}
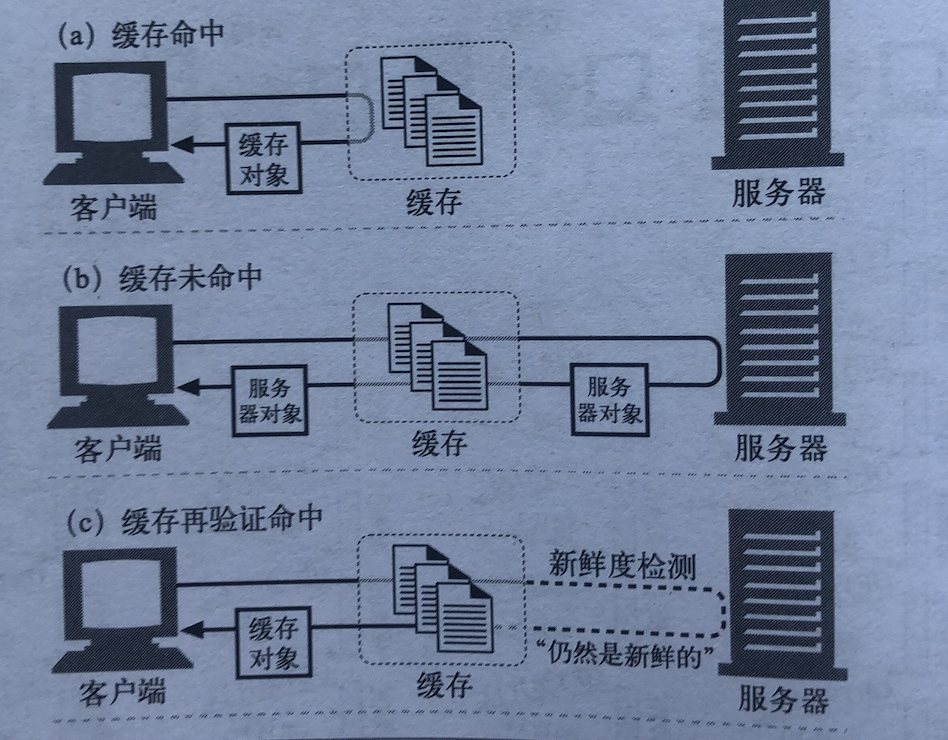
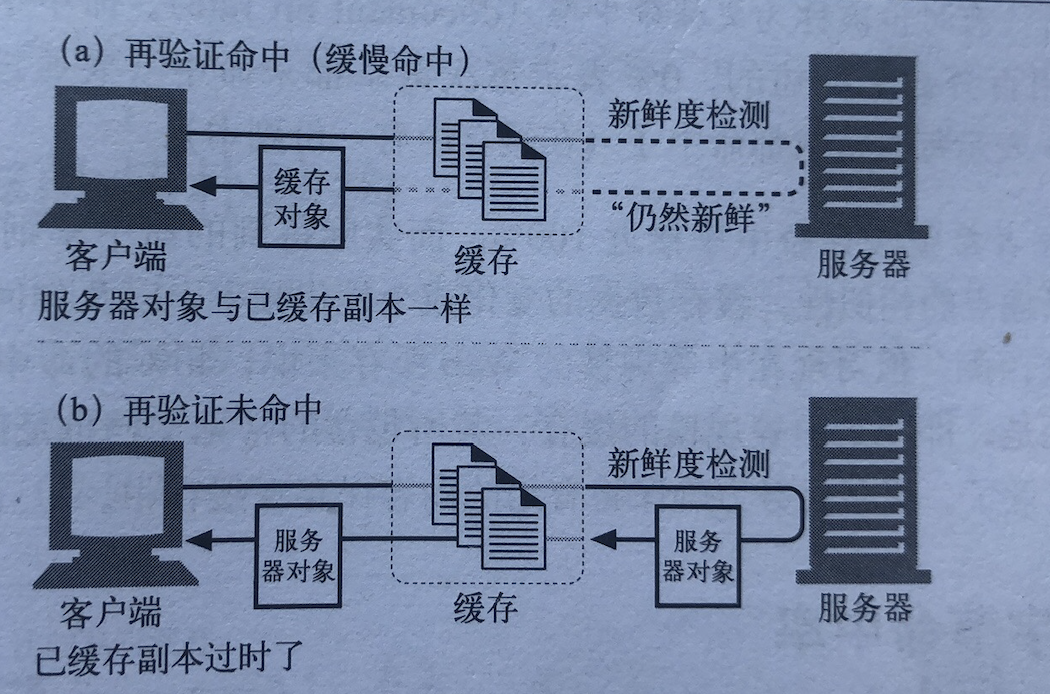 图片来源:http权威指南
图片来源:http权威指南
浏览器会先查看请求是否命中本地缓存,若命中,则直接使用本地缓存,这个请求返回的http状态码是200,而响应的内容与该请求上一次有效返回一致,常见的有:from memory cached,from disk cached
若缓存在本地没有命中,则会去检测新鲜度,也叫协商缓存,通常是etag && if-none-match与last-modify && if-modified-since这两对组合去判断,前者优先级更高;如果缓存仍然有效,则响应的http状态码是304;如果缓存已经失效,那么响应的http状态码是200,服务器返回最新的内容。
用于判断缓存是否命中的优先级为:
pragma > cache-control > expired
2019.11.03更新cache-control字段
这里需要特别说一下cache-control的值,no-cache,no-store,must-revalidate;当服务器响应的中的header包含no-cahce的时候,表示,下次该请求再次发出的时候,需要再次校验本地保存的缓存是否正确才能够使用,这里所说的校验,通常是通过etag, last-modified等的协商缓存进行协商;
当服务器返回的响应中header中包含:cache-control: no-store,则表示浏览器不会存储该请求响应的内容,所以下次浏览器再次发出请求的时候,则不会带上etag的内容,相当于是一个新的请求
当服务器返回的响应中header中包含:cache-control: must-revalidate,则表示当缓存过期(max-age: 0)的时候,需要需要重新进行校验,当返回must-revalidate, max-age=0的效果,相当于cache-control: no-cache.
用于判断新鲜度的优先级为:
etag > last-modified
options请求的缓存
这里需要特别说明一下options请求的缓存:Access-Control-Max-Age: seconds;主要用来缓存预检(Preflight)请求options。
什么情况下会出现预检options请求?在设置跨域cors的时候,对于“复杂”请求,则会先发出预检;若对于“简单”请求,则不会发出。
Access-Control-Max-Age表示对该options预检请求进行缓存,在指定时间内,同一个请求则不再发出预检;该时间单位为秒;若返回-1,则表示,该请求不需要缓存,每次请求都需要预检。但是这个时间的最大值可能不一定受用于影响,据谷歌得到结果所知,chromium浏览器的最大缓存时间是10分钟(10 * 60s),而firefox则是最大缓存时间是24小时(24 * 60 * 60s)。
http2
接下来说一下http2的相关特点,主要有以下三点:
- 二进制分帧与多路复用
- server push
- header压缩
二进制分帧与多路复用
http1.1的请求头与内容等是已字符串的形式传输,以空行为分隔符;而http2是以二进制的方式传输,把请求头与请求内容都封装成帧;
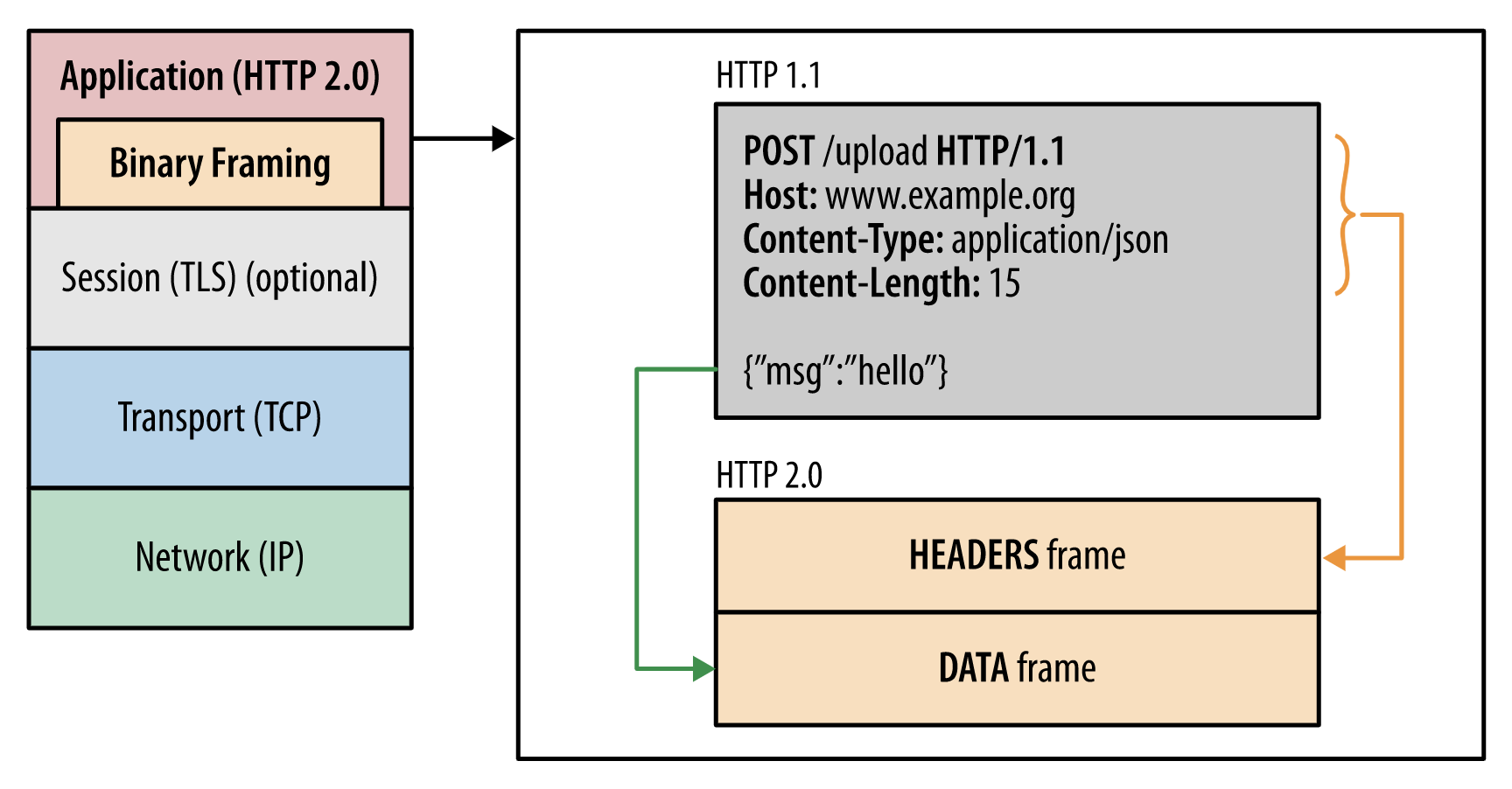
对与新的二进制分帧的数据传输模式,需要熟悉几个概念:
- 帧(frame):http2的最小通信单位,每个帧都包含帧头,至少也会标识出当前帧所属的数据流。通常有header与body对应的frame。
- 消息(message):与逻辑请求或响应消息对应的完整的一系列帧。通常一个请求或者一个响应,会包含一个或多个帧;对于这些组合起来的帧,就是称为消息。
- 流(stream):已建立的连接内的双向字节流,可以承载一条或多条消息。通常是包含多条消息,例如"一个请求+一个响应"组成一个流;而一个TCP连接中,会有很多的流。
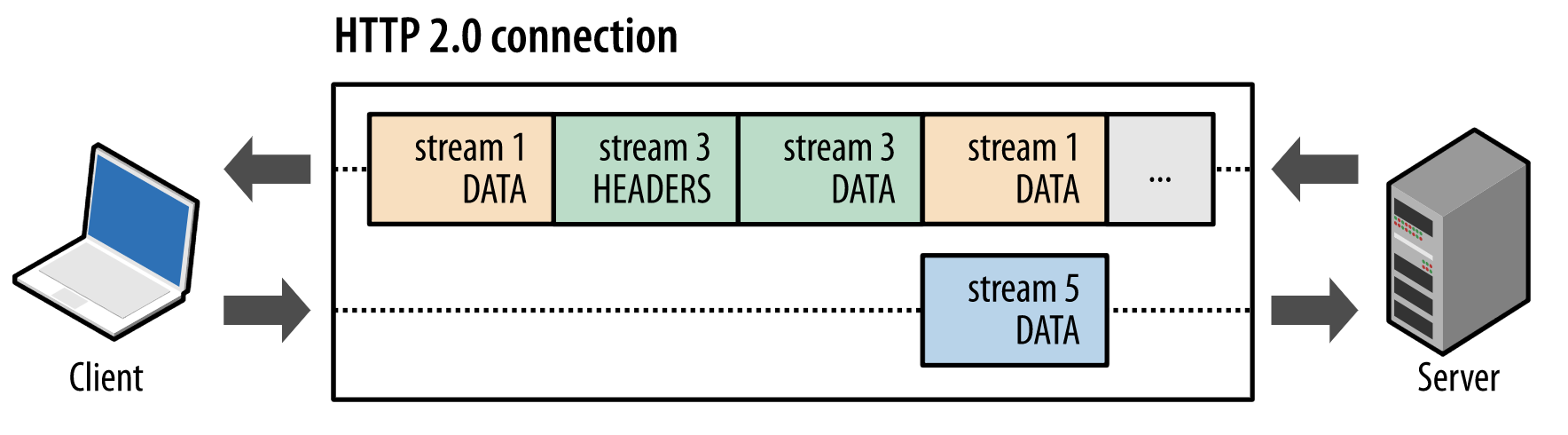
从图上我们可以看出,发送的时候,很多时候都是并非按顺序的传输,帧与帧之间不需要等待,这样子可以达到快速的传输目的。
Q&A
- 乱序传输会影响结果否?
不会,因为每一个帧都带有头部信息,这些头部信息能够给到接收的一端重新组装。
- 都是并发的发送,能否设置优先级优先处理?
能,数据流与帧都能够设置优先级,优先级使用1到256之间的整数表示,数字越大,处理的优先级越高。
- 对于一些有依赖的资源,例如: A资源需要等到B资源拿到完成后才能发起的情况怎么处理?
对于有依赖关系的数据流来说,会优先把依赖的资源优先获得分配,然后再对原有资源进行整理。
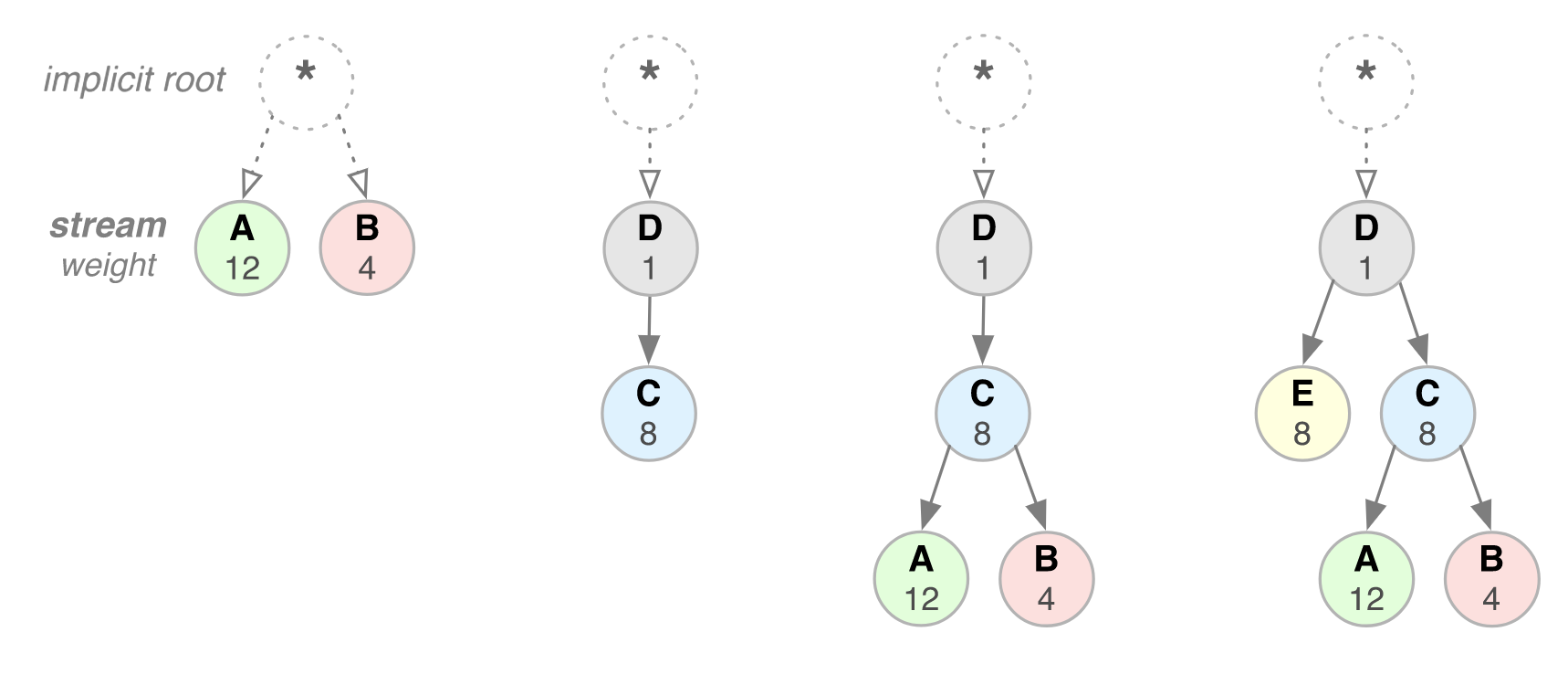
例如左一情况,数据流A的优先级比数据流B优先级高,从weight数值知道,数据流 B 获得的资源是 A 所获资源的三分之一。
例如左而情况,数据流C依赖与数据流D,尽管C比D优先级高,但是还是数据流D优先获取完整数据,再到C获取。
多路复用
从上面的二进制分帧的处理可以看出,多个http请求可以利用一个tcp进行数据传输,形成多路复用;而http1.1,只能够一个tcp对应一个http,而浏览器对同时建立的tcp连接数通常限制为6;尽管在keep-alive的加持下,能够复用已存在的tcp链接,但是总体并发请求的效率不如http2。
server push
http1.1都是基于“请求-响应”来处理数据,而http2,服务器可以主动发送资源到客户端,客户端下次需要数据的时候,就可以直接使用,不需要重新发起请求。例如请求index.html,index.html包含style.css与app.js文件;当允许server push的时候,浏览器请求index.html的同时,也返回了style.css与app.js,等到浏览器解析html文件的时候,需要对应的资源文件,就可以快速获取。
header压缩
很多情况下,当我们连续发出多个http请求的时候,请求的header信息会重复,例如cookie,http method,scheme等。如果请求的body内容越少,那么相当于header的内容大小在这次请求的占比越高,利用率就变得更低了。
而http2,可以把重复相同的请求头不发送,只发送与之前曾经发过不同的请求头,具体例子如图
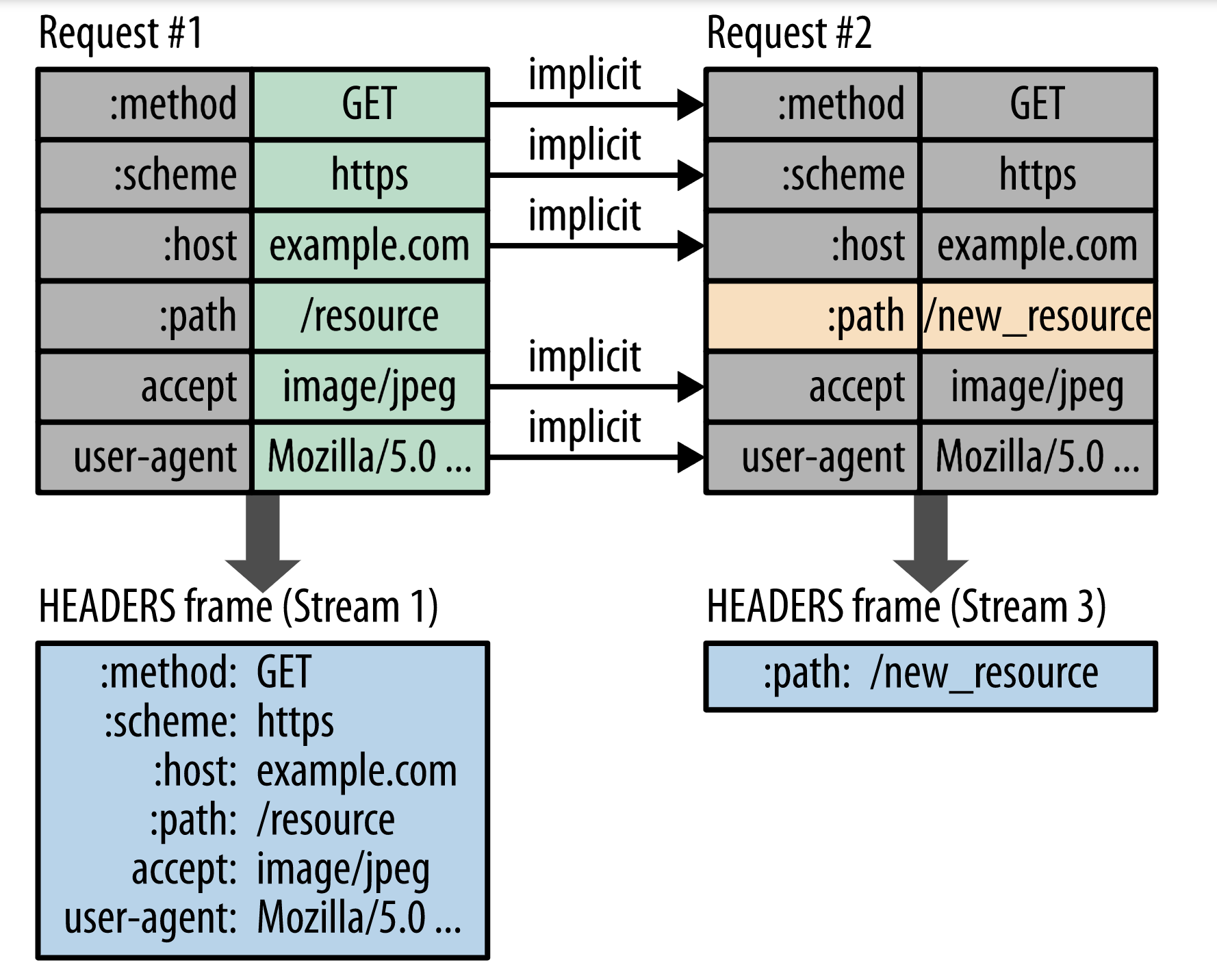 图片来源
图片来源
第二次请求与第一次请求相比,只是:path的值发生了改变,那么第二次请求的时候,只需要发出:path: /new_resource的请求头;通常的情况也适用于响应头。http2使用hpack的算法来实现这种"diff header",下面会简单说一下实现的过程:
客户端只传不同的header,那么服务器是怎么拿到完整的header?
客户端与服务器都需要会维护一个静态字典(static table)与一个动态字典(dynamic table);静态字典是包含常见的头部名称与值的组合,例如:scheme: http,:method: GET,:status: 200,更多静态字典可见这里。而动态字典是由双方来协定添加。字典的内容,是通过哈夫曼编码(Huffman Coding)处理后,再添加到字典中。我们看一个例子:
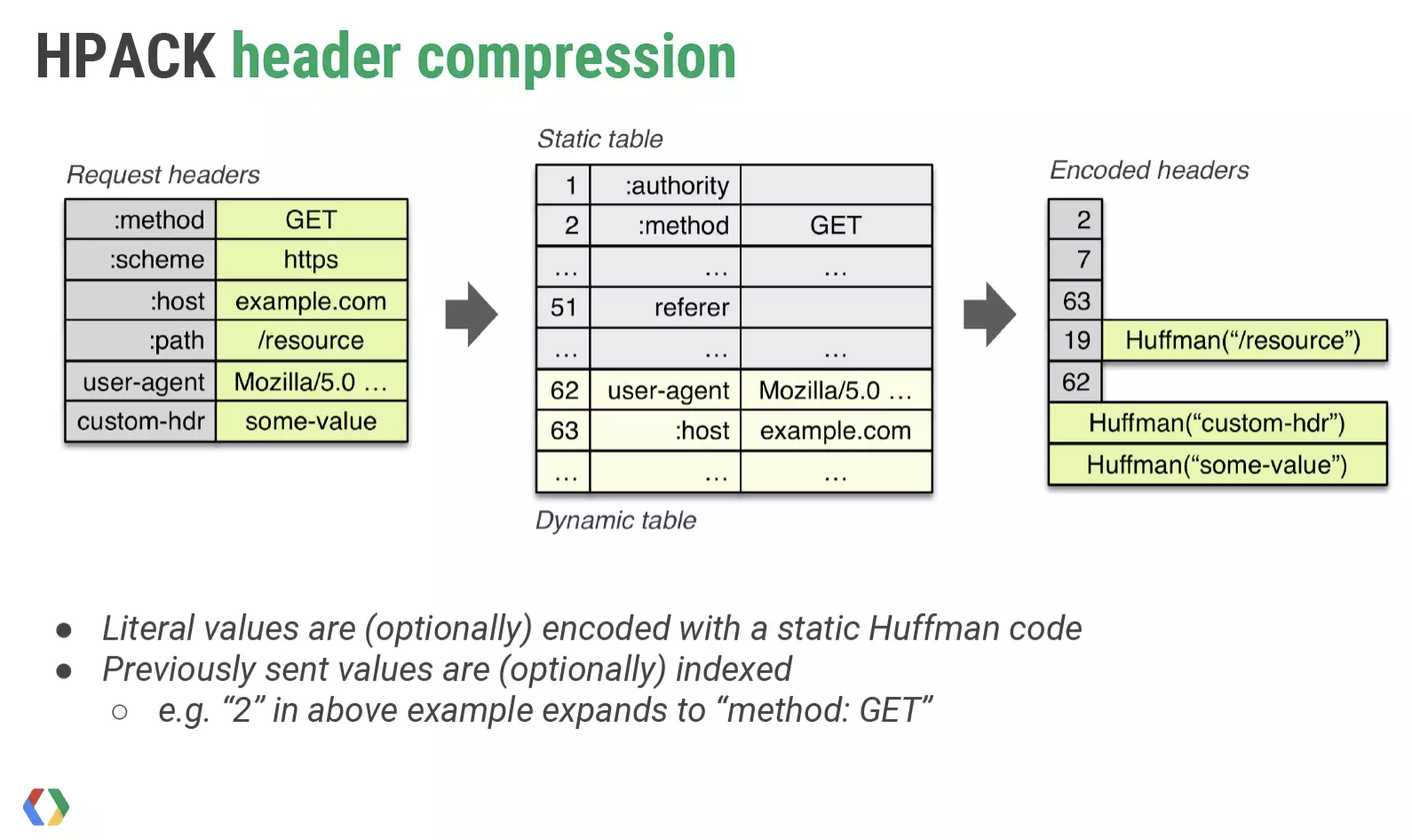
在请求发送前的请求头为:
:method: GET
:scheme: https
:host: example.com
:path: /resource
user-agent: Mozilla/5.0 ...
custom-hdr: some-value
经过静态字典的编码之后:
:method: GET => 2
:sheme: https => 7
...
:path: /resouce => 19: Huffman("/resource")
这里的2和7是静态字典中的索引值,通过索引值的发送,可以大大降低header内容的大小;而对于:path,因为:path也在静态字典中,所以key值就是索引值,而/resource因为不在静态字典用,使用哈夫曼编码处理:Huffman("/resource");对于自定义的custom-hdr,key与value值都是用哈夫曼编码。这次使用哈夫曼编码处理的值,会加入到对应的动态字典里面中,当下一个请求发出的时候,就可以利用动态字典中的索引来表示,也大大减少了header的内容大小。
参考链接:
- https://developers.google.com/web/fundamentals/performance/http2/
- https://imququ.com/post/header-compression-in-http2.html