How is the pretrained PointRCNN model supposed to be used? + Training Issues PointRCNN
Checklist
- [X] I have searched for similar issues.
- [X] I have tested with the latest development wheel.
- [X] I have checked the release documentation and the latest documentation (for
masterbranch).
My Question
Hi,
I am using the following versions:
- tensorflow: 2.5.3
- open3d: 0.15.2 (from pip), as well as a local git clone of the current master branch
I am currently trying to get PointRCNN Object Detection (TF) to work. For that I downloaded the pretrained weights and trying to validate the model using the following command:
python scripts/run_pipeline.py tf -c ml3d/configs/pointrcnn_kitti.yml --dataset.dataset_path <dataset_path> --model.ckpt_path <pretrained_path/ckpt-1> --split test --mode RCNN/RPN
I tried both modes. When in RPN mode, cls loss is at around 1.1 and reg loss at around 7.7. However, validation_MAPs are always 0.0 in all cases. In RCNN mode, the validation losses are around 0.0 and the validation_map's are again 0.0 in all cases.
So what mode has the pretrained PointRCNN been trained on? How should it be used?
Also, when I try to train PointRCNN by myself (RPN), the same issue with always zero validation_MAPs exists. Even after 50+ epochs, they stay at 0.0 in all cases. See the plots of the training and validation of the RPN below. Remember, this is with default settings.
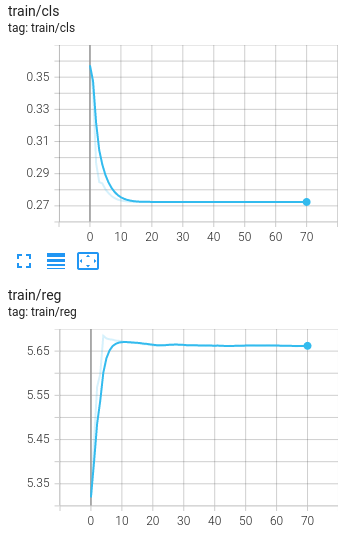
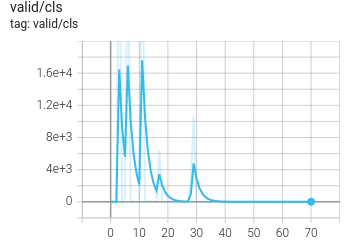
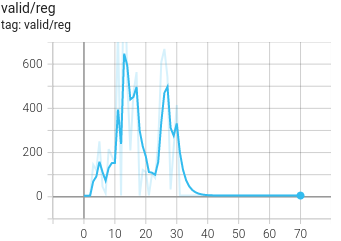
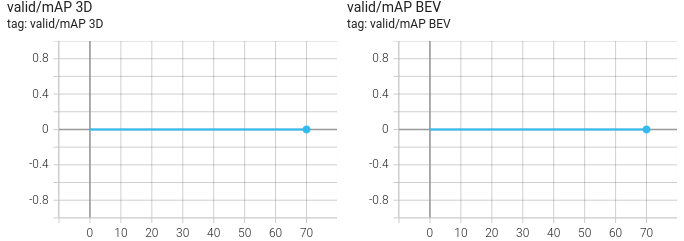
So i checked the pretrained weights of PointRCNN (for tensorflow) using self.ckpt.restore(ckpt_path).assert_existing_objects_matched() and i get lots of warnings that the weights were not loaded properly. Was the default config or the model of PointRCNN changed after uploading the weights? That would probably be the easiest explanation (since using saved checkpoints from my own training worked and the pointpillar weights work too).
This means that the currently linked weights are not up to date. Would you be able to update these?
@Jeremy26, did you find a solution? I'm exactly the same issue. Training results always in 0.