Christian Lorentzen
Christian Lorentzen
The point is to encourage people, in their daily work, to _think about what they want to predict and the purpose of the prediction_. Depending on that, the use of...
On one hand, it's great if this PR gets appreciated. On the other hand, 2.5 years after opening it, I might rewrite some parts of it. In particular, today I...
I'm not so sure about the example with the apple blossoms. It's more an example to emphasize probabilistic predictions instead of showing how to select a good scoring function.
TBH, now that I have published https://arxiv.org/abs/2202.12780, I don't know if its worth finishing this PR. The paper really nails down what I intended to convey with this PR. As...
@agramfort @mathurinm @TomDLT Your help would be highly appreciated to figure out the right dual gap for the elastic net. Above, I gave references and also did the computation myself....
@mathurinm Thanks for the prompt reply! That's a great trick that I would have never guessed (even though I used it myself in the quantile regression). I will open a...
That's a great code snippet! - `n_samples=500`, `n_features=2000`, `alpha = alpha_max / 30`, `beta = 0.1 * alpha` 1583 zero coefficients `np.sum(w == 0)` 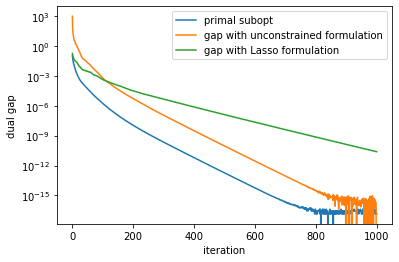 - `n_samples=500`, `n_features=2000`, `alpha =...
> Also I'd feel safer if the code I wrote was proofread. I did and checked results with `ElasticNet` and `enet_coordinate_descent`. Looks good.
It seems that when the unrestricted formulation is bad, the "L2" term dominates, i.e. `sum_j (|X_j'nu| - alpha)_+^2`. This is particular true at the first iterations when most coefficients are...
Having a huber loss available as metric makes sense for models fitted with huber loss. Be aware that the huber loss elicits something in between the median and the expectation,...