Lenan22
Lenan22
> Hi I've met the error below during converting from onnx model to int8 trt engine on Xavier > > I just followed the step in instructions and exec: python3...
> 我检查了ppq.parser.tensorRT.py 196行处的代码input_shapes已经被设置为[32,3,640,640],并且在247行for循环后添加了下面的代码,设置了proile,min.opt,max的尺寸都是[32,3,640,640]。 min, opt, max = input_shapes[inp.name] profile.set_shape_input(inp.name, min, opt, max) > > ``` > config.add_optimization_profile(profile) > trt_engine = builder.build_engine(network, config) > ``` > > 但是还是会出现上面这个问题。 > > 后来我修改了04_Benchmark.py中的代码,将batch_size设置成了1,将inputshape设置成了[32,3,640,640],代码也可以运行,相对于fp32的也实现了快10倍的加速(基于3090显卡)。...
> 请问一下我这边有个模型,量化分析的时候误差比较大,这个怎么优化处理?选的TargetPlatform.PPL_CUDA_INT8 默认设置。 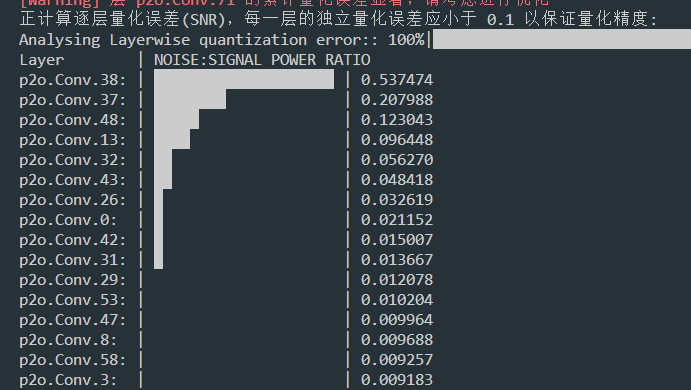 如果使用了优化算法,网络的中间某一层出现的误差较大,是正常的情况(无标签训练有时会出现这种情况),具体要看最后一层的模拟误差以及在硬件上跑的效果
Please refer to our open source quantization tool ppq, the quantization result is better than the quantization tool that comes with tensorrt, almost the same as the float32 model. https://github.com/openppl-public/ppq/blob/master/md_doc/deploy_trt_by_OnnxParser.md
> ## Env > ## Env > * GPU,RTX1080Ti. > * Ubuntu18.04 > * Cuda 10.2 > * TensorRT 7.0.0 > > ## About this repo > yolov5l/yolov5m/yolov5s > >...
> 你好,请问你的问题解决了吗,我这边也是发现int8推理结果明显不对,conf也下降了好多 tensorrt自带的量化算法比较简陋,难以解决一些模型的精度下降问题, 请参考我们的开源量化工具ppq,可以协助解决tensorrt的量化问题,有量化的精度推理问题欢迎在我们的社区提问,我们可协助帮你解决。 https://github.com/openppl-public/ppq/blob/master/md_doc/deploy_trt_by_api.md
> 你好,请问你的问题解决了吗,我这边也是发现int8推理结果明显不对,conf也下降了好多 tensorrt自带的量化算法比较简陋,难以解决一些模型的精度下降问题, 请参考我们的开源量化工具ppq,可以协助解决tensorrt的量化问题,有量化的精度推理问题欢迎在我们的社区提问,我们可协助帮你解决。 https://github.com/openppl-public/ppq/blob/master/md_doc/deploy_trt_by_api.md
> INT8 has lower accuracy, this is normal, maybe you can try other calib data or more calid data, or try INT8 QAT method. > > The inference speed depends...
> Hi, highly appreciate for your work. > > Device: AGX Xavier OS: Ubuntu 18.04.6 LTS Jetpack 4.6, CUDA 10.2, CUDNN 8.2.1, TensorRT 8.0.1.6 > > We have tried FP32...
> yolov5s trt float16可以准确的预测框,但是int8预测效果很差,该怎么解决呢 @enazoe Please refer to our open source quantization tool ppq, the quantization effect is better than the calibration of tensorrt, if you encounter issues, we can...