1nlplearner
1nlplearner
fine-tune的话大概需要多少数据才能使音色比较相似
您好,请问hifi-gan的电音问题可以通过微调解决吗 预置的vocoder是在预测mels上训练的吗 我看代码应该是在ground truth mels指导下生成的mels上训练的,而不是纯预测的mels上训练的 --------------------------------------------------------------------------------------------- 我用目标语音微调自己的synthesizer后,hifigan的电音竟然也消失了
您好,请问训练的时候有遇到过训练过一段时间后,train loss跑飞了的情况吗
I want to use trained multi-speaker model to inference with exacted x-vector, how to use exacted x-vector Thanks
> See example notebook. https://colab.research.google.com/github/espnet/notebook/blob/master/espnet2_tts_realtime_demo.ipynb#scrollTo=3TTAygALqY6T thanks for your reply
> See example notebook. https://colab.research.google.com/github/espnet/notebook/blob/master/espnet2_tts_realtime_demo.ipynb#scrollTo=3TTAygALqY6T 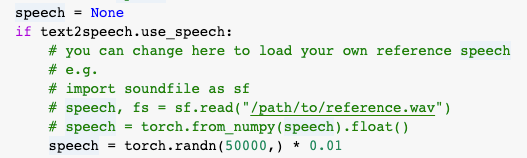 I use the recording file under the corresponding speaker folder as speech,but it perform worse than initialing speech with torch.randn, any tips?
> Could you provide more details of the training (e.g., configs etc.)? It is not possible for us to give feedback with limited information. thanks for your reply,the information is...
> @Kristopher-Chen how many domains in you discriminator and how many discriminators
> @skol101 I don't believe so, if it's not for any-to-any, you only need to have a lot of input speakers. You do not need cycle loss in this case,...
> @1nlplearner At the first execution, onnxruntime takes a longer time for inference. So please skip the first execution. i think this is the reason, [Some nodes were not assigned...