ilcpm
ilcpm
I tried it on pandoc 2.17, find 2 bugs and updated to the newest pandoc 2.18, one is fixed, the other one is this ``` pandoc.exe 2.18 Compiled with pandoc-types...
@mjfs 我们(非pandoc官方)想尝试做一个专门为md转换docx设计的pandoc插件,你的这个问题我们在我们的项目中用一些方法解决了。不过毕竟只是两个非计科的本科生,所以项目进度比较慢,而且出现了比较严重的项目管理问题,目前仓库比较混乱(有几个私有仓库),初稿应该是6月底或者7月会整理好后对外发布,可以关注一下https://github.com/ilcpm/pandoc_markdown2docx_instuction
In our project, we find a way to deal with this problem. for pandoc ,it will copy the first `w:sectPr` tag from "reference.docx" to the end of the output docx...
> I love it: defining LaTeX macros that return Word XML! Twisted. Your filter must also change the format on these RawBlocks from "latex" to "openxml", right? yeah, that was...
说一个问题,jpg并不适合存储计算机图像,尤其是图片内容含有文字时, 以下图片是相同内容截图后在jpg和png格式下无插值缩放算法的情况下放大4倍的对比 jpg图像26KB,文字的周围一堆噪点  png图像48KB,文字清晰,周围无噪点 
try press `~` key to use the script, if not, all the keys will be recognized as the keyboard inputs like your typing through the physical keyboard
> OCR处理之后,保存文件时,abbyy会对图像进行处理,导致保存的PDF文件膨胀的很厉害 深表赞同,有的灰度打印的书籍不能用黑白存储,会丢失信息或者导致图片不能看,用CEP的话可以处理成4级或者16级灰度得到不错的效果 --- > 即使不勾选任何图像预处理选项、保存时使用的是最佳质量 正因为你选用的是最佳质量才会这样,最佳质量的情况下如果是彩色的图像ABBYY会把图片存为24位无损压缩的png格式,基本上就凉了…… 你如果选“允许质量损失”进行有损压缩,ABBYY会使用jp2格式来存储彩色图像,然后把质量拉到30%左右(具体记不清了,可以自己多试几次),就可以在保证清晰的情况下把彩色的图像得到较好的体积,因为jp2的压缩比非常高,可以在极低体积的情况下获得很好的效果,对于文字类型的图像还不会像jpg一样把周围压糊;但是jp2压缩会导致PDF滚动变得非常卡顿,因为jp2的解码需要大量的CPU运算,很难进行流畅的滚动,一页一页慢慢看或者通过目录进行快速跳转还是没有问题的 所以目前最佳的方案就是回避ABBYY的彩色图像,用老马的CEP软件把PDF的正文页面处理成纯黑白的图像(这个对技术要求比较高,我自己摸索了两年到现在才能比较流畅的完成整个过程),我自己是处理成600DPI的纯黑白tiff格式(CCITT g4无损压缩),封面存为300DPI的jpg格式,然后在ABBYY中如图选择,存储之后黑白图像还是原来的无损压缩,封面可能会被处理成jp2格式,这样一本几百页的教材只有40M左右 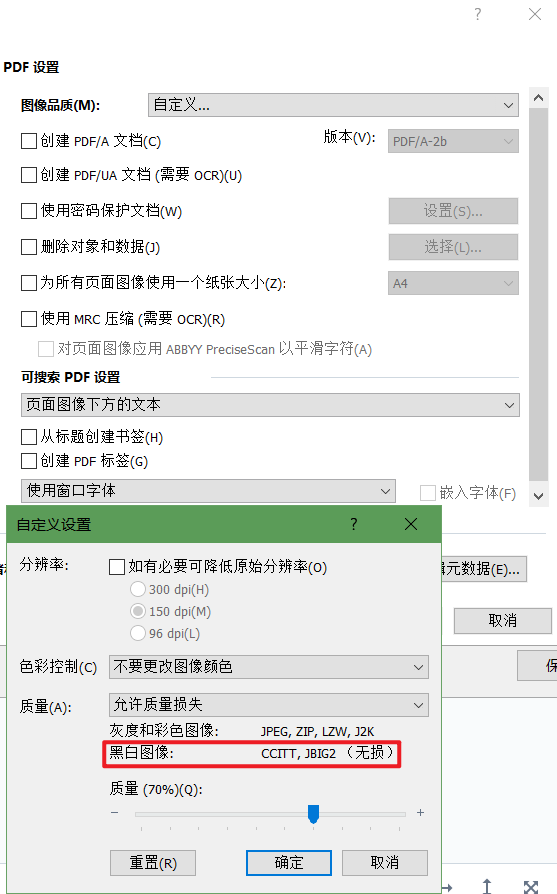
```json "[markdown]": { "editor.quickSuggestions": true, }, ``` by default, markdown won't provide any suggestion untill this setting is turned up. hope this can help you.
also, remember to add `[]` outside of the bib file like `bibliography: [1.bib]` this is the problem I meet...
赞同,希望可以自定义工具条,添加自定义的命令上去,这样OCR就可以直接做成一个按钮然后需要的时候调用外部程序来实现了