heliqi
![]()
heliqi
> > 2. 需要在Model(比如yolov5)里处理下: 如果用户设置了RuntimeOption的device_id却没有设置预处理,这个时候预处理默认与runtime保持一致 。 有些用户只知道runtime的设置,不知道预处理也要设置,所以不特殊设置预处理就默认与runtime保持一致 > > @heliqi 这个逻辑不好实现呢, 因为PaddleClasPreprocessor::UseGpu(int gpu_id=0)函数来设置device id的,Preprocessor默认是不用GPU的。 只能通过传入的gpu id来设置。 或者不给这个gpu id设置默认值,让用户显式指定。 这个逻辑不要写在预处理里,预处理只管设置和处理,相关逻辑在我们Model那一层判断。 比如不要写在PaddleClasPreprocessor中, 而是写在PaddleClasModel的构造函数。 点错了,不小心关了..
非常感谢你的反馈,我们下个版本的计划具体还没出,部署这块正在排期中。我会反馈并讨论你提的这些问题,最终可能需要下周才能答复你这些问题。
paddlex导出的模型,model_type需要填 paddlex
paddlepaddle-1.8.5装的是gpu版本么? gpu版本一般为paddlepaddle-gpu==xxx,比如: python3 -m pip install paddlepaddle-gpu==1.8.5.post107 -f https://paddlepaddle.org.cn/whl/stable.html 安装文档: https://www.paddlepaddle.org.cn/documentation/docs/zh/1.8/install/index_cn.html
官网已发布2.1.1预测库,你试试最新的
https://paddle-inference.readthedocs.io/en/latest/user_guides/download_lib.html
编译时把tensorrt选项打开,并填写好地址即可。最新代码的分别是: 1. WITH_GPU 启用GPU编译, vs的cmake界面勾选上 或 CMakeSettings.json 里的False改为True 2. WITH_PADDLE_TENSORRT paddle inference推理引擎 是否启用trt。 勾选 或 改为 True 3. TENSORRT_DIR tensorrt的解压路径, 需要填写上 下图就是vs的cmake配置界面, 如何打开可以看你上面链接中的文档。 CMakeSettings.json 在deploy/cpp目录下 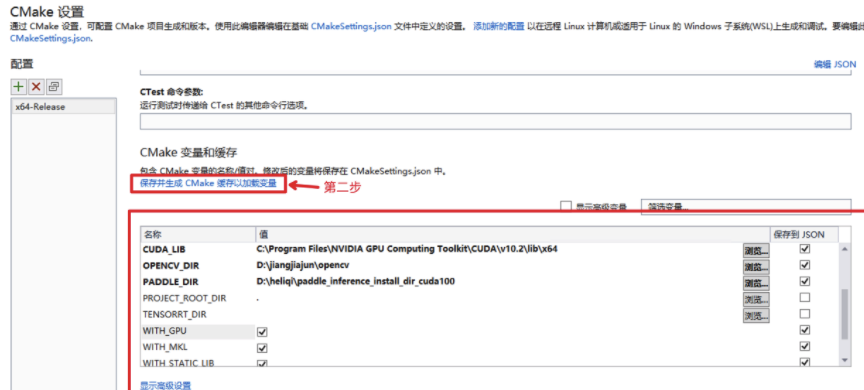
1. CUDA_LIBA 路径是否设置正确 ,以及是否配置cuda到环境变量 。 可以用 nvcc --version 指令 和 nvidia-smi 指令 检验下环境变量的设置 2. 直接双击 model_infer.exe 看看有没有提示缺少什么dll 以上解决完,基本OK。如果还不行: 3. 你使用的是CMAKE GUI吧,完全按文档用VS自带的cmake重新编译试试
1. 你是不是安装了多版本cuda ?nvidia-smi 的打印有点点问题, 检查下你的环境变量是否设置对,改成你的 cuda11.0的路径 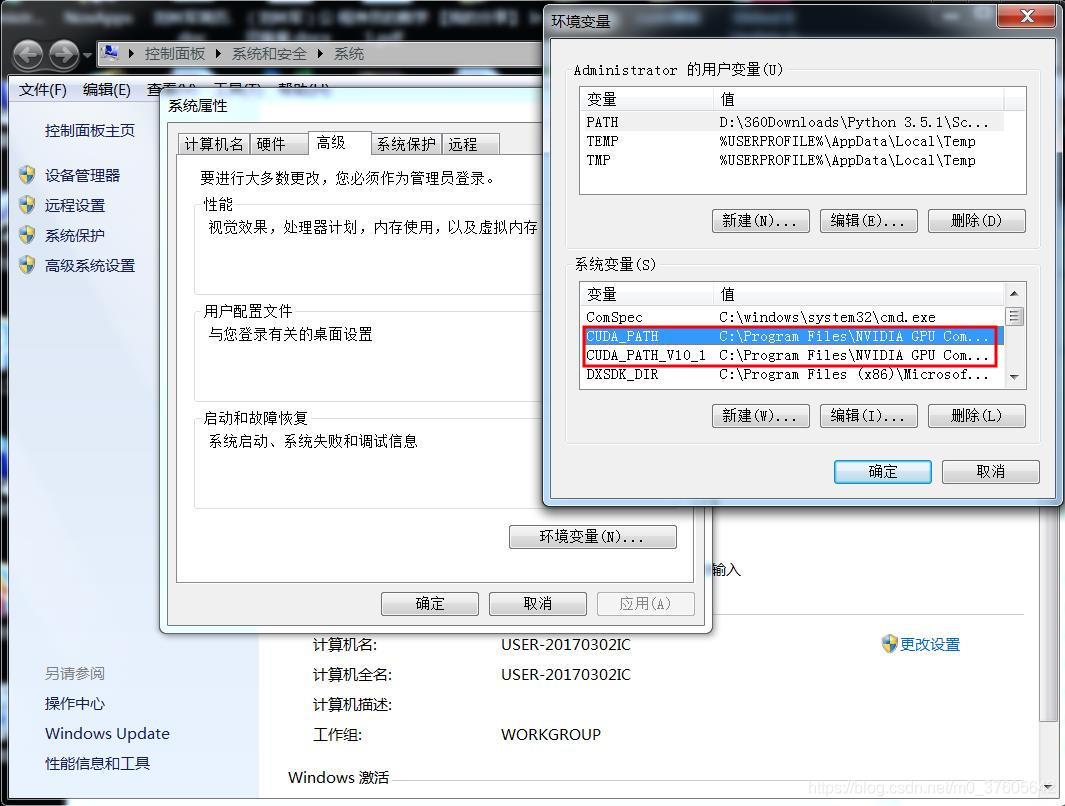 同时在Path下加入CUDA11.0 目录里的 bin等目录, 具体你可以搜索cuda 、 cudnn环境配置。 2. 检查下 model_infer.exe所在目录是否有 nvinfer.dll 等 trt需要的dll库 如果没问题的话,你把双击运行报错的截图给我看看
对了,如果你一开始没勾选 WITH_TENSORRT, 后面才勾选。 需要先清空缓存(比如把vs的输出目录out删掉), 然后重新编译一下。 还有一个非常关键的点: 你下载的paddle inference预测库版本,一定要跟CUDA、CUDNN、TensorRT版本对上。 比如: 下载 [cuda11.0_cudnn8.0_avx_mkl_trt7](https://paddle-wheel.bj.bcebos.com/2.1.1/win-infer/mkl/post110/paddle_inference.zip) 预测库 , 那你的cuda一定要是11.0, cuDNN = 8.0、 TensorRT应该是7.2(这个具体看预测库解压后目录中的version.txt文件)