PaddleX
 PaddleX copied to clipboard
PaddleX copied to clipboard
Gpu版如何链接Tensorrt
https://github.com/PaddlePaddle/PaddleX/blob/develop/deploy/cpp/docs/compile/paddle/windows.md
按照此地址的操作,要编译成Gpu版的话,如何链接Tenssort

部署平台:Windows
部署语言:C#
编译时把tensorrt选项打开,并填写好地址即可。最新代码的分别是:
- WITH_GPU 启用GPU编译, vs的cmake界面勾选上 或 CMakeSettings.json 里的False改为True
- WITH_PADDLE_TENSORRT paddle inference推理引擎 是否启用trt。 勾选 或 改为 True
- TENSORRT_DIR tensorrt的解压路径, 需要填写上
下图就是vs的cmake配置界面, 如何打开可以看你上面链接中的文档。 CMakeSettings.json 在deploy/cpp目录下
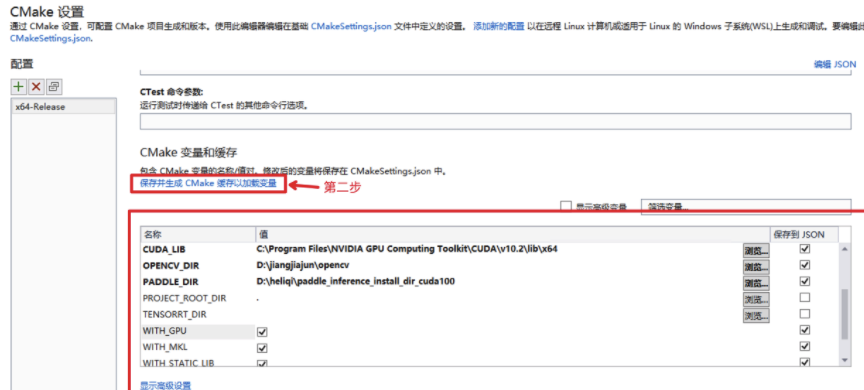
编译时把tensorrt选项打开,并填写好地址即可。最新代码的分别是:
- WITH_GPU 启用GPU编译, vs的cmake界面勾选上 或 CMakeSettings.json 里的False改为True
- WITH_PADDLE_TENSORRT paddle inference推理引擎 是否启用trt。 勾选 或 改为 True
- TENSORRT_DIR tensorrt的解压路径, 需要填写上
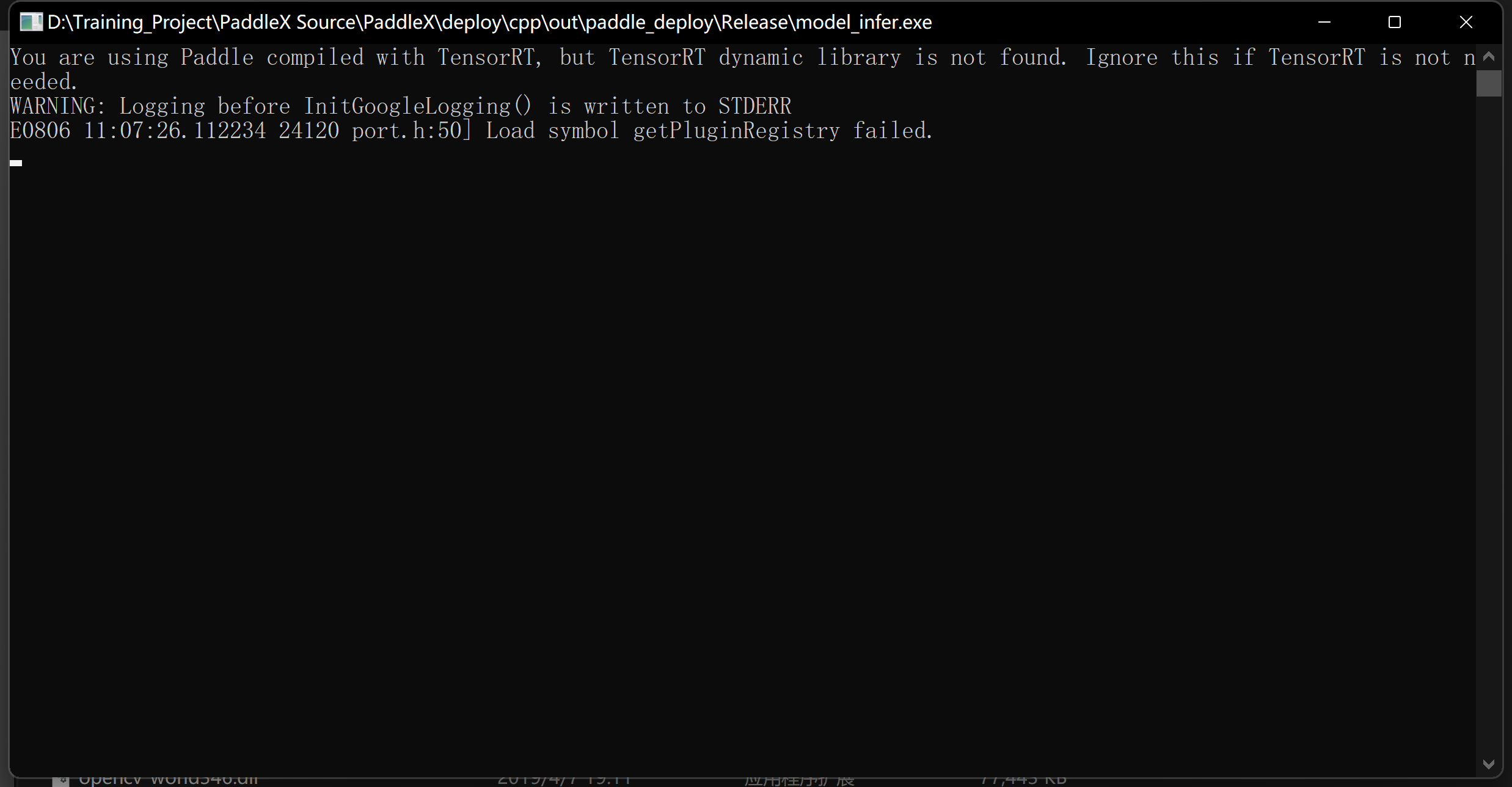
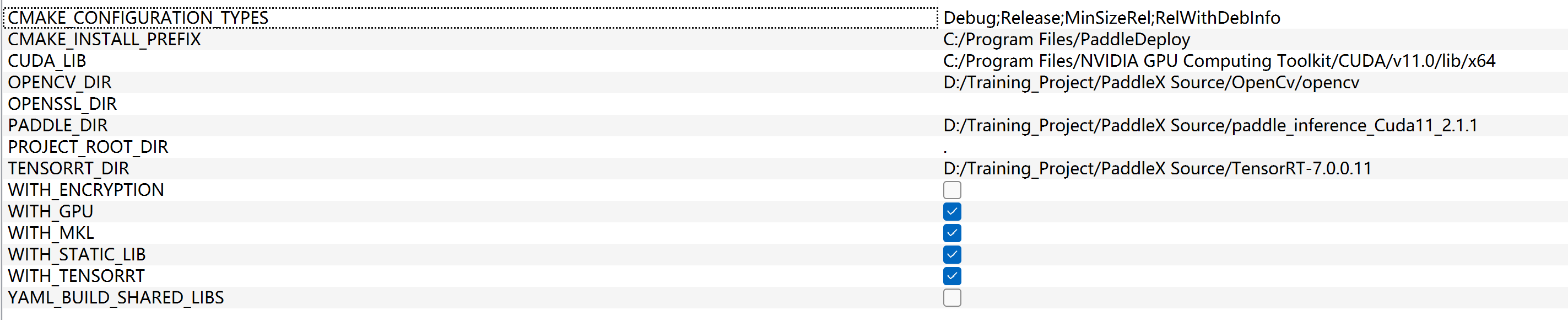 我这个应该没错吧,但是我Vs编译出来运行不了啊,如下图:
我这个应该没错吧,但是我Vs编译出来运行不了啊,如下图:
@heliqi
- CUDA_LIBA 路径是否设置正确 ,以及是否配置cuda到环境变量 。 可以用 nvcc --version 指令 和 nvidia-smi 指令 检验下环境变量的设置
- 直接双击 model_infer.exe 看看有没有提示缺少什么dll
以上解决完,基本OK。如果还不行: 3. 你使用的是CMAKE GUI吧,完全按文档用VS自带的cmake重新编译试试
- CUDA_LIBA 路径是否设置正确 ,以及是否配置cuda到环境变量 。 可以用 nvcc --version 指令 和 nvidia-smi 指令 检验下环境变量的设置
- 直接双击 model_infer.exe 看看有没有提示缺少什么dll
以上解决完,基本OK。如果还不行: 3. 你使用的是CMAKE GUI吧,完全按文档用VS自带的cmake重新编译试试

 直接双击 model_infer.exe的话就是报那个tensorrt的问题
直接双击 model_infer.exe的话就是报那个tensorrt的问题
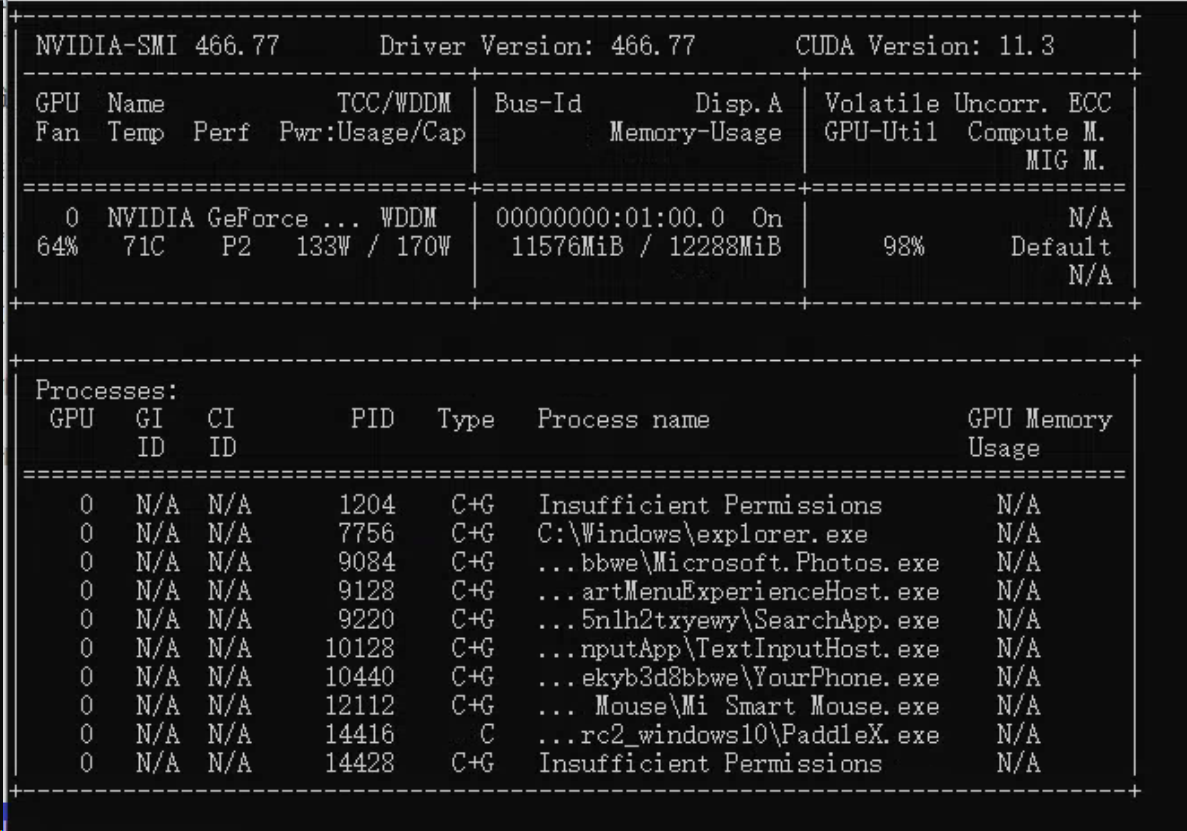
- 你是不是安装了多版本cuda ?nvidia-smi 的打印有点点问题, 检查下你的环境变量是否设置对,改成你的 cuda11.0的路径
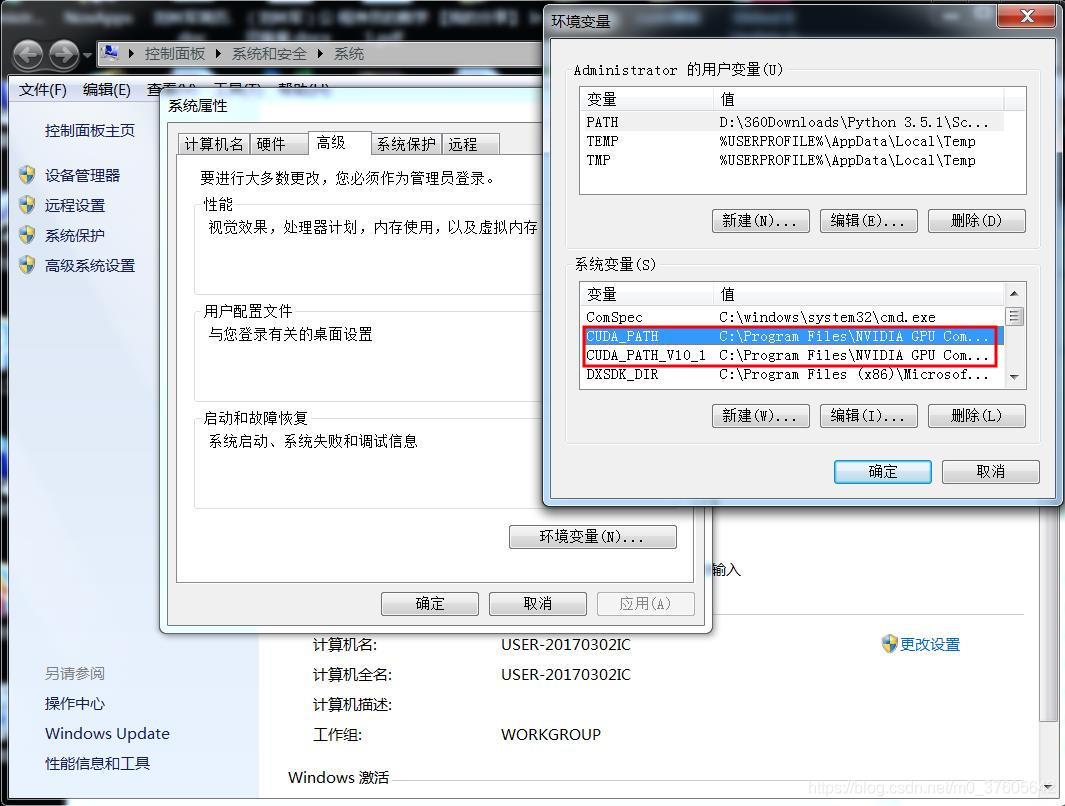 同时在Path下加入CUDA11.0 目录里的 bin等目录, 具体你可以搜索cuda 、 cudnn环境配置。
同时在Path下加入CUDA11.0 目录里的 bin等目录, 具体你可以搜索cuda 、 cudnn环境配置。 - 检查下 model_infer.exe所在目录是否有 nvinfer.dll 等 trt需要的dll库
如果没问题的话,你把双击运行报错的截图给我看看
对了,如果你一开始没勾选 WITH_TENSORRT, 后面才勾选。 需要先清空缓存(比如把vs的输出目录out删掉), 然后重新编译一下。
还有一个非常关键的点: 你下载的paddle inference预测库版本,一定要跟CUDA、CUDNN、TensorRT版本对上。 比如: 下载 cuda11.0_cudnn8.0_avx_mkl_trt7 预测库 , 那你的cuda一定要是11.0, cuDNN = 8.0、 TensorRT应该是7.2(这个具体看预测库解压后目录中的version.txt文件)
对了,如果你一开始没勾选 WITH_TENSORRT, 后面才勾选。 需要先清空缓存(比如把vs的输出目录out删掉), 然后重新编译一下。
还有一个非常关键的点: 你下载的paddle inference预测库版本,一定要跟CUDA、CUDNN、TensorRT版本对上。 比如: 下载 cuda11.0_cudnn8.0_avx_mkl_trt7 预测库 , 那你的cuda一定要是11.0, cuDNN = 8.0、 TensorRT应该是7.2(这个具体看预测库解压后目录中的version.txt文件)
客户端上面需要配置什么环境?跟开发环境一样? @heliqi
客户端环境:Windows10,显卡RTX3060,Cuda11.4,没有配置过环境 ,直接运行“model_infer.exe”报错,在开发环境(电脑没有Gpu,用的Cpu)可以正常运行
 @heliqi
@heliqi
不明白的你客户端是啥意思。
以上我说的所有情况都是针对: 你用vs编译C++预测代码,并运行编译后的二进制文件 model_infer.exe 。 编译运行的cuda trt环境一定要跟下载的预测库对应上
不明白的你客户端是啥意思。
以上我说的所有情况都是针对: 你用vs编译C++预测代码,并运行编译后的二进制文件 model_infer.exe 。 编译运行的cuda trt环境一定要跟下载的预测库对应上
不是,我的意思是,我在这台电脑上编译嘛,然后可以正常运行 model_infer.exe 了,那么我把这些文件拷贝到别的电脑上去,要不要再配置环境,就跟当前可以运行 model_infer.exe 的电脑一样配置一堆环境;但是Tensorrt在正常运行的那台电脑上没有配置环境变量啊,那怎么把程序在别的电脑上运行呢,目前测试下来是会报错的。
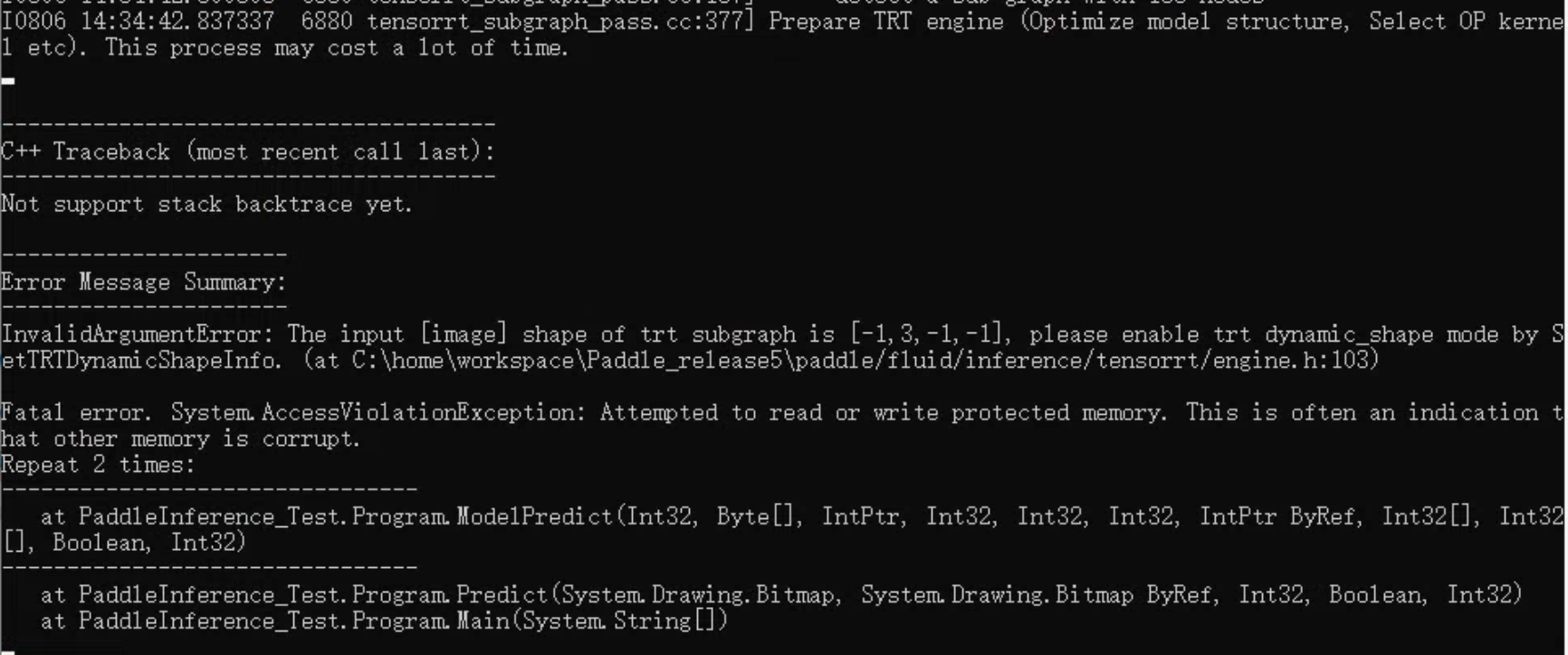 @heliqi
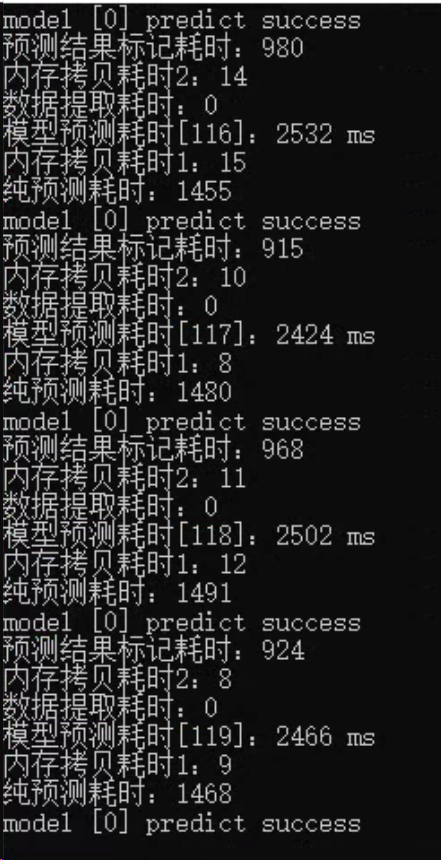
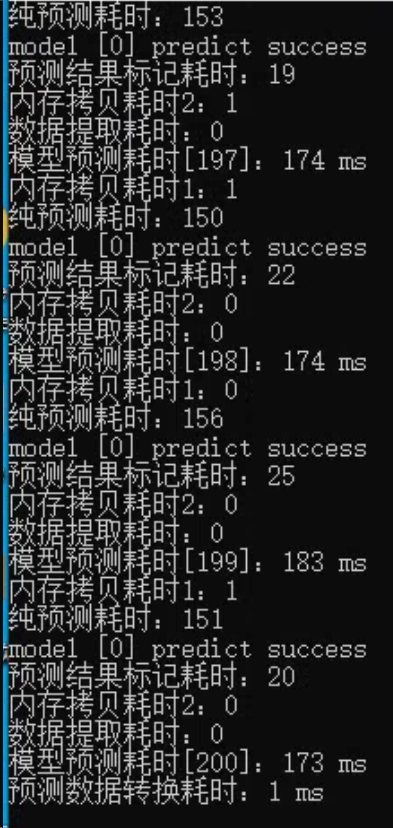
@heliqi 可以运行了,但是好慢啊,tensorrt也用上了
@heliqi
可以运行了,但是好慢啊,tensorrt也用上了
@heliqi
给看这个issues的其它人解答下: 在A机器上编译去B机器上运行,需要以下操作:
- 把编译生成的model_infer.exe所在目录的所有文件( nvinfer.dll 等文件)从A 拷贝到B。 不仅仅拷贝执行文件model_infer.exe,拷贝整个目录
- 需要在A机器上安装跟B机器一样的cuda环境, 一样版本的 cuda 和 cudnn
关于运行速度慢:
- 看起来在GPU这么慢确实不太正常
- 有没有先运行50~100 predict,再打印推理时间?
- 分别打印下预处理、推理、后处理的时间, 确认下看看真正耗时的地方在哪里
- 什么模型? 用的是什么型号的GPU? 我这边可以测下benchmark
给看这个issues的其它人解答下: 在A机器上编译去B机器上运行,需要以下操作:
- 把编译生成的model_infer.exe所在目录的所有文件( nvinfer.dll 等文件)从A 拷贝到B。 不仅仅拷贝执行文件model_infer.exe,拷贝整个目录
- 需要在A机器上安装跟B机器一样的cuda环境, 一样版本的 cuda 和 cudnn
关于运行速度慢:
- 看起来在GPU这么慢确实不太正常
- 有没有先运行50~100 predict,再打印推理时间?
- 分别打印下预处理、推理、后处理的时间, 确认下看看真正耗时的地方在哪里
- 什么模型? 用的是什么型号的GPU? 我这边可以测下benchmark
@heliqi
模型文件及预测用的图片我上传到百度云了,显卡是RTX3060,图片是 5472*3648 分辨率
链接:https://pan.baidu.com/s/1GORqrL9nycYHxoAbL4hWjQ 提取码:27y3 --来自百度网盘超级会员V5的分享
上面的链接可能失效了,这是模型文件的新百度云链接
链接:https://pan.baidu.com/s/1tkqXuu5fG84UGwB6sXDcgw 提取码:l4qy --来自百度网盘超级会员V5的分享