Jian

Hello, use your matlab script `generate_train.m` generate h5 file, pytorch load error. Can you guide me? thanks. ``` Namespace(batchSize=128, clip=0.4, cuda=True, lr=0.1, momentum=0.9, nEpochs=50, pretrained='', resume='', seed=0, start_epoch=1, step=10, threads=8,...
为什么我的浏览器打开,网页显示很奇怪  ?
``` ====================================================================== ERROR: test_ctc_loss_op (unittest.loader._FailedTest) ---------------------------------------------------------------------- ImportError: Failed to import test module: test_ctc_loss_op Traceback (most recent call last): File "/root/anaconda3/lib/python3.5/unittest/loader.py", line 428, in _find_test_path module = self._get_module_from_name(name) File "/root/anaconda3/lib/python3.5/unittest/loader.py", line...
### Instructions  ### System information - **Win11**: - **FiftyOne installed from pip**: - **FiftyOne v0.16.6, Voxel51, Inc.**: - **Python 3.9.12**: ### Commands to reproduce ``` session = fo.launch_app(dataset) ```
### Instructions 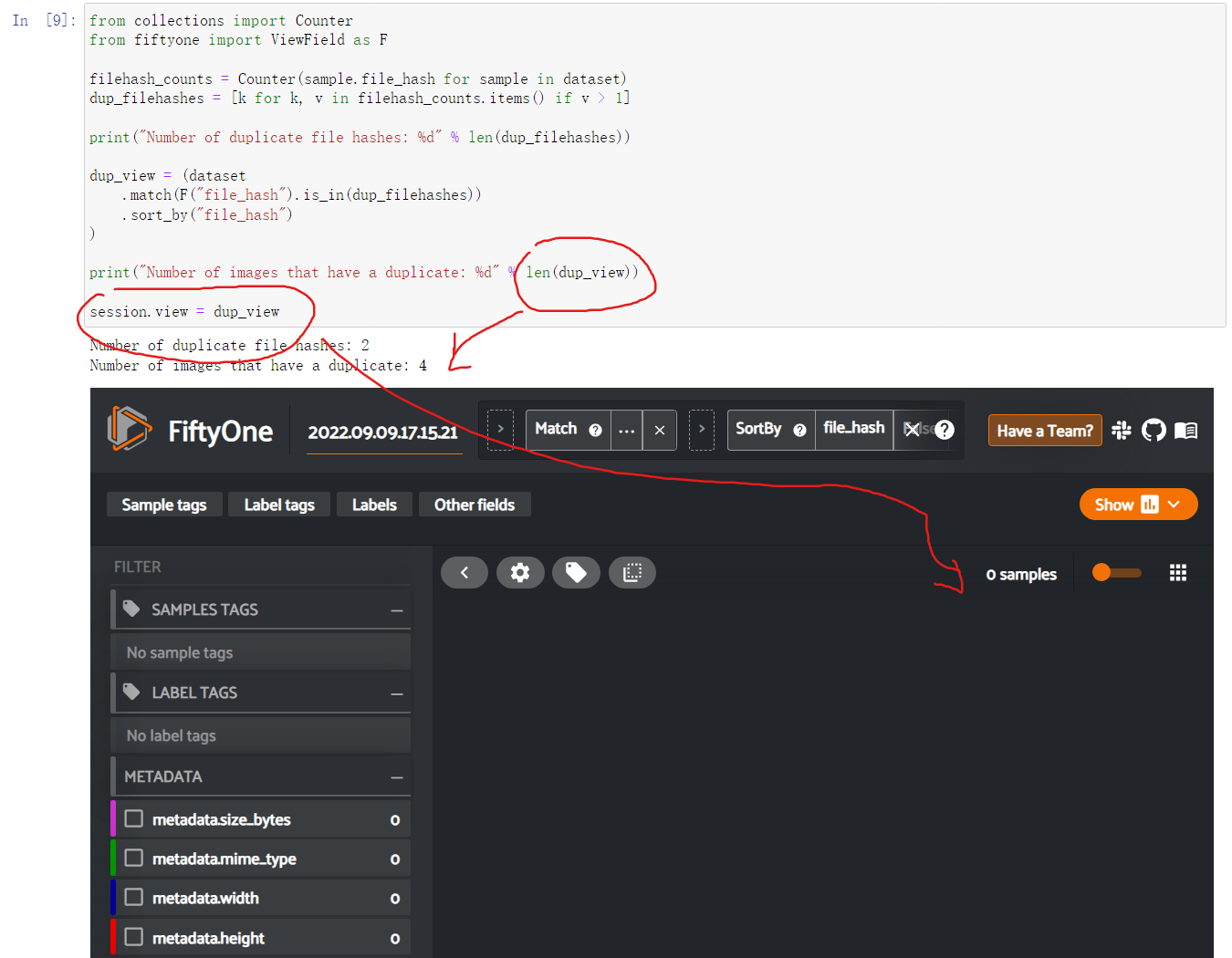 ### System information - **Linux Ubuntu 20.04** - **FiftyOne installed from pip** - **FiftyOne v0.16.5, Voxel51, Inc.** - **Python 3.9.7** ### Describe the problem dataset size is...
自然场景文字识别效果目前还不及Tesseract,为什么不考虑用深度网络检测文字呢?
你好,我想请教一下[200行Python代码实现感知机词性标注器](http://www.hankcs.com/nlp/averaged-perceptron-tagger.html)中【搜索】哪一节中`train`函数的一个问题: 文中前端说的是,当`guess != true_tag`时就更新权重(犯错时),第一个`train`出现的时候。可是【搜索】这一段中却总是在更新,是遗漏了吗? ``` guess = self.tagdict.get(word) if not guess: feats = self._get_features( i, word, context, prev, prev2) guess = self.model.predict(feats) self.model.update(tags[i], guess, feats) # Set the history features...
AveragedPerceptron.py的96~97行,model.predict(features)中返回的是guess_tag,而不是每个tag对应的评分: ``` scores = model.predict(features) guess, score = max(scores.items(), key=lambda i: i[1]) if guess != class_: model.update(class_, guess, features) ``` 是不是应该这样: ``` guess = model.predict(features) if guess != class_: model.update(class_,...
yes?
代码: ```py filename = f"chattts-rand-speaker-{i:03d}.se.wav" wav, sample_rate = torchaudio.load(filename) wav = wav[0] speaker = chat.sample_audio_speaker(wav) params_infer_code = ChatTTS.Chat.InferCodeParams( # spk_emb=speaker, # add sampled speaker temperature=0.3, # using custom temperature top_P=0.7,...