UER-py
 UER-py copied to clipboard
UER-py copied to clipboard
Open Source Pre-training Model Framework in PyTorch & Pre-trained Model Zoo
请问多任务微调时,预训练使用训练数据性能变差了怎么办(大概100M数据)。此外如果想在预训练时利用cls,预料应该如何组织?在源代码preprocess.py中,target参数没有了cls选项?请问target='mt'表示什么?
在hugging face下载的模型:https://cdn.huggingface.co/bert-base-chinese-pytorch_model.bin ,使用scripts中convert_bert_from_huggingface_to_uer.py,报错: Traceback (most recent call last): File "convert_bert_from_huggingface_to_uer.py", line 22, in output_model["embedding.layer_norm.gamma"] = input_model["bert.embeddings.LayerNorm.weight"] KeyError: 'bert.embeddings.LayerNorm.weight' 脚本: python convert_bert_from_huggingface_to_uer.py \ --input_model_path ../models/bert-base-chinese-pytorch_model.bin \ --output_model_path ../models/google_zh_model.bin
Could you please provide more optimizers since quite a few encoders (not limited to BERT) are included in the project.
您好!非常棒的工作,我想把他应用于英文文本分类工作 我更改了预训练模型路径,词表,还有tokenizer的配置 !CUDA_VISIBLE_DEVICES=0 python3 run_classifier.py --**pretrained_model_path models/google_model_en_uncased_base.bin** \ --vocab_path **models/google_uncased_en_vocab.txt** \ --train_path datasets/train_en.tsv --dev_path datasets/dev_en.tsv \ --test_path datasets/test_en.tsv \ **--tokenizer space \** --epochs_num 3 --batch_size 32 --encoder bert 在英文二分类的实验上报了如下错误: 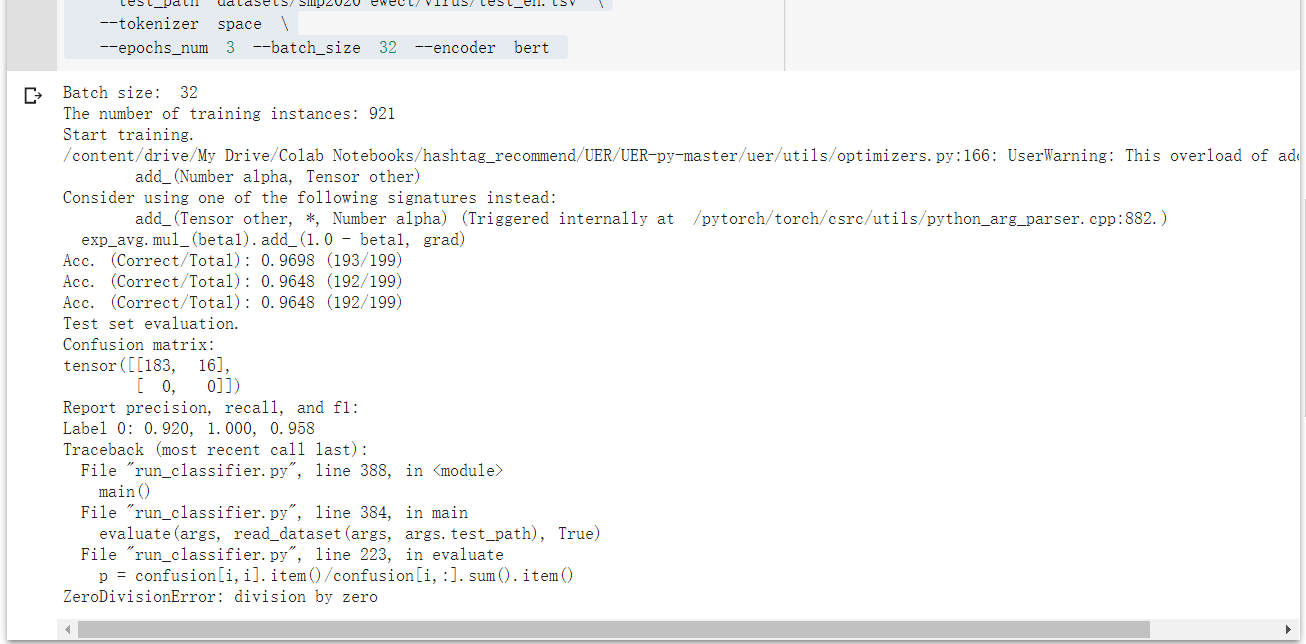...
运行run_classifier.py,默认使用所有显卡,使用nvidia-smi查看Volatile GPU-Util四块Tesla T4显卡均是100%,但是代码卡在transformer部分,指定单张卡速度却恢复正常!
添加额外专业词汇

我有一些专业词汇想添加进词典。 google_zh_vocab.txt 里面有100个空位,但是这个数量远远达不到需求。不知道我如果想添加成千上万的专业词汇该怎么办? 在这个回答中看到,在词典中加新词是可以的 [https://github.com/google-research/bert/issues/9](https://github.com/google-research/bert/issues/9) > (b) Append it to the end of the vocab, and write a script which generates a new checkpoint that is identical to the pre-trained...
你好, 十分欣賞閣下的model及對中文NLP的深入理解。 當中尤其是, word-based bert 這個model...因為坊間所有bert乃character-based ,使其無法做到對詞搜詞的操作。 可否一問, 我是住香港的nlper. 我使用的是繁體字, 如何可finetune bert_wiki_word_model.bin? 我想過先把近三十萬句繁體字句子先進行分詞, 然後使用閣下build_vocab.py 再把繁體字vocab 加入google的vocab.txt之中。 但在閣下的word-based bert vocab.txt 之內, 詞語旁是有weighting的, 這使我大為不解? 可否請教, 如我使用繁體字, 可如何pretrain bert_wiki_word_model.bin? 然後使用topn_words_dep.py ? 謝謝 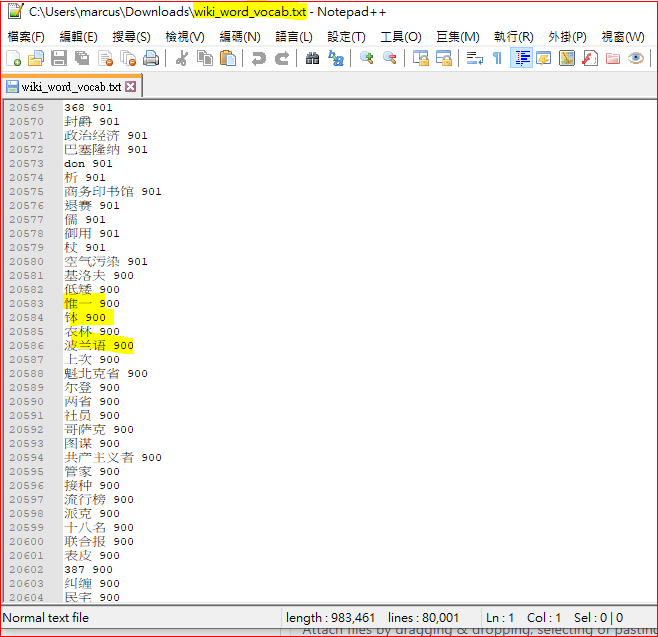
多节点训练问题
请问多个节点多GPU训练的具体操作是怎样的? ReadME中的例子: ``` Node-0 : python3 pretrain.py --dataset_path dataset.pt --vocab_path models/google_zh_vocab.txt \ --pretrained_model_path models/google_model.bin --output_model_path models/output_model.bin \ --encoder bert --target bert --world_size 16 --gpu_ranks 0 1 2 3 4 5...