colcon-core
 colcon-core copied to clipboard
colcon-core copied to clipboard
Improve startup time
In a workspace with ~650 packages, I have a significant delay on startup— about 5-6 seconds when cold, and still almost 4 seconds on an immediate re-invocation. Here's a flamegraph of what colcon list looks like when run on a warm workspace (this is on a SAN-backed VM):
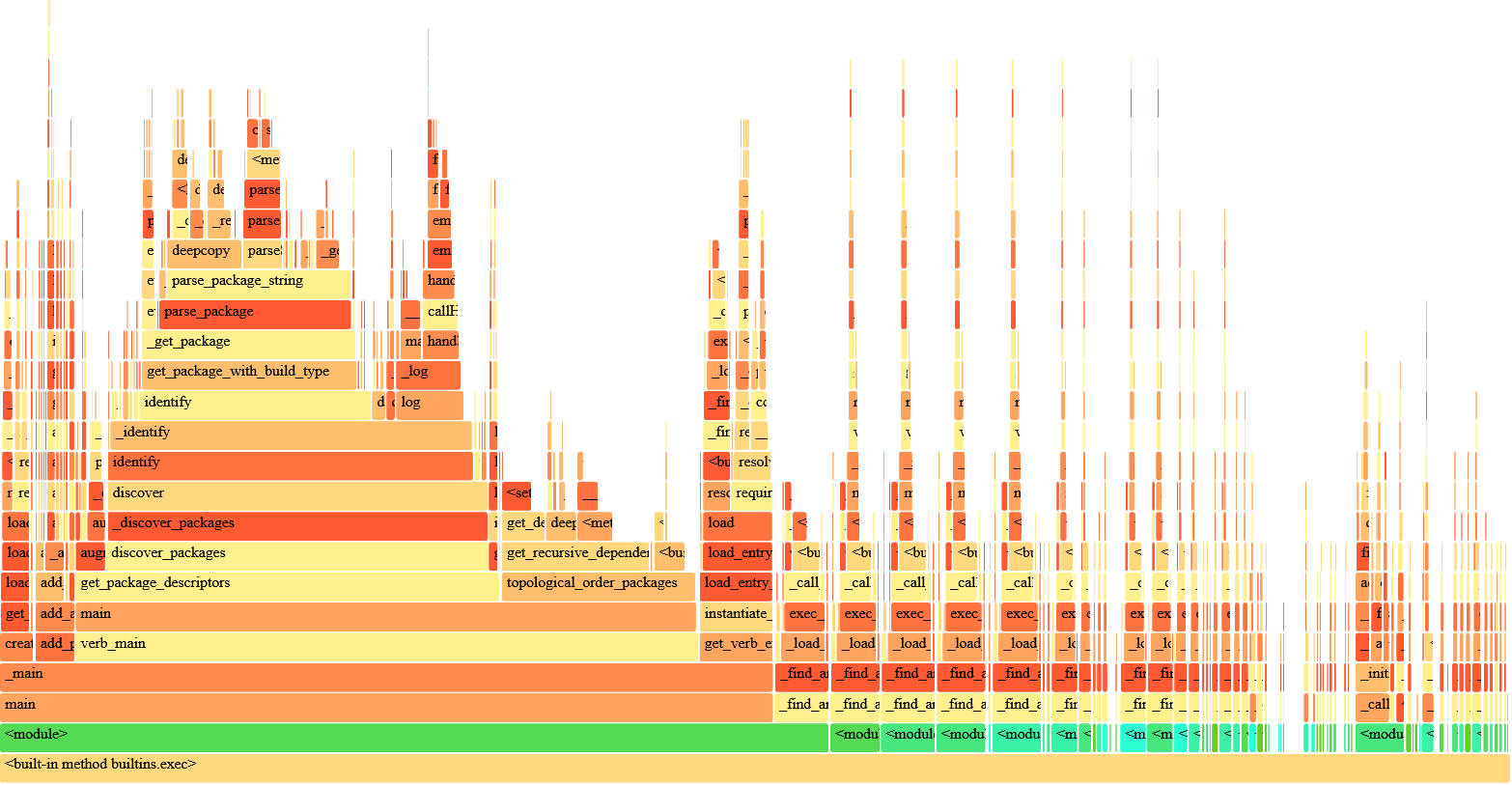
Of the 4 seconds, about half is package discovery/identification, and a third is plugin loading. I'm wondering about some possible strategies for improving this— normal asyncio isn't going to help here, since the parsing is CPU bound and native filesystem IO isn't async anyway. But plugin discovery could use a cache for the 99% case where there is nothing new to discover, and package discovery should be possible to heavily parallelize by walking the workspace breadth-first and pushing work onto other threads/processes, perhaps using ProcessPoolExecutor? Recursive gathering of the subdirectories might work for this?
package discovery should be possible to heavily parallelize by walking the workspace breadth-first and pushing work onto other threads/processes
I have tried that in the past with no significant benefit.
Interesting; I shall experiment a bit with it on my end and see if I find anything new.
It's also interesting to note from the flamegraph that topological ordering seems to be relatively quite expensive; perhaps there is an opportunity there to do some caching, especially now that the Dependency is an object to which metadata may be attached, rather than just a string.
If nothing else, if we find that some degree of delay on startup is unavoidable, it may be worth providing the user some indicator of what is going on, like an application splash screen does. This could even be time-triggered, so it doesn't begin outputting until the overall startup has already been >500ms.
topological ordering seems to be relatively quite expensive
I think performance improvements to similar code in catkin_pkg have been merge recently. Maybe something similar can be applied here.
I don't think the approach from https://github.com/ros-infrastructure/catkin_pkg/pull/280 would work exactly here as the bulk of colcon-core logic for this lives inside the PackageDescriptor object. However, an easy way to do it if we didn't want to directly annotate the DependencyDescriptors themselves might be to pass some kind of cache dict/object into the PackageDescriptor.get_recursive_dependencies function, then the persistence would only be one layer up, and it could be thrown away immediately after, avoiding any mutation or long-term memory implications.
Here's a first stab at a process pool package crawler:
https://github.com/mikepurvis/colcon-multiprocess-recursive-crawl/blob/0cfd01dd28f88181569bb2d77435ee00a6426284/colcon_multiprocess_recursive_crawl/package_discovery/recursive_crawl.py#L59-L81
All of the scandir recursion still takes place in coroutines on the main thread; only the identification portion is run on the executors. A potential other angle to try here would be feeding the subdirectory scanning jobs into some kind of a work-queue, though that would be potentially a lot more complexity for modest gains.
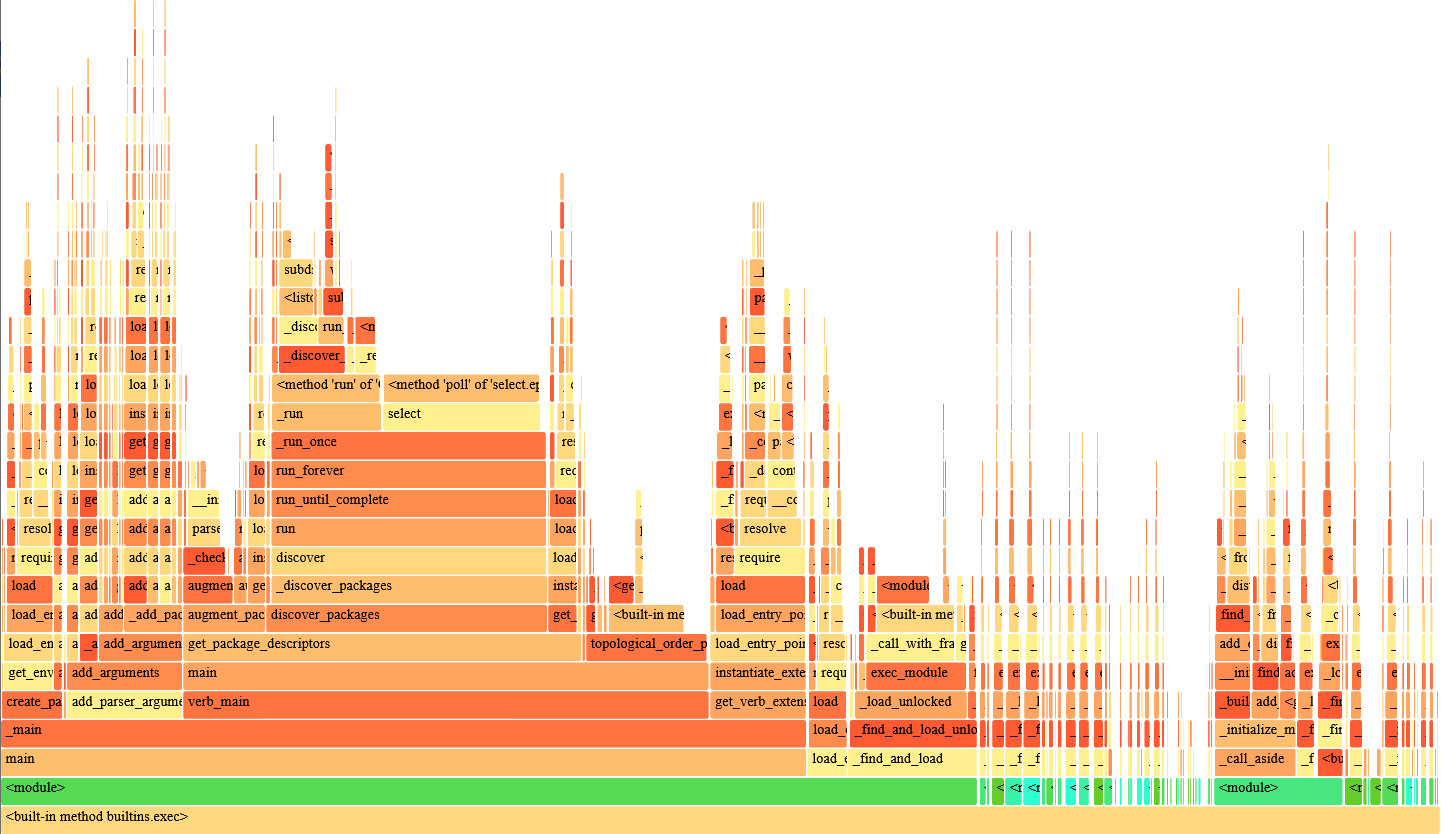
In any case, I haven't tried to profile just how much it's actually fanning out and taking advantage of the concurrency, nor have I looked at the fixed impact on small workspaces. But at least in my 650 package workspace, it cuts the scanning time approximately in half— relative to the baseline given in the initial post, we're now clearly being dominated by topological ordering and the entry_point/exec calls associated with plugin loading:

Edit to add, here's a version which avoids the recursion and moves the scandir call for subdirectories into the other processes— interestingly it seems to be either about the same or slightly worse than the version which only does identification on the other processes.
The implementation is a little janky, but here's a go at a simple dep caching scheme: https://github.com/colcon/colcon-core/compare/master...mikepurvis:package-deps. If you think there are legs here, I can open a PR and we can discuss further how to better structure it (another source of speedup was dropping all the deepcopy calls, which has meant there is no longer depth metadata being tracked, and obviously it is now recursive rather than iterative; both of these may be sticking points for you).
Also, I cleaned up two other sources of delay from the previous flamegraph:
- There were a handful of duplicate checkouts in my workspace, which is why those
realpathcalls were happening duringget_recursive_dependencies. - Several of the items on the right hand side of the chart were in fact heavyweight dependencies that were being pulled in at the module level in some of my experimental plugins. I've now restructured those to instead use lazy imports.
With these changes, I can colcon list my 650 packages in ~2.0s. The new flamegraph is:

This is what the startup time looks like running colcon --help in an empty directory.
PYTHONPROFILEIMPORTTIME=1 && python3 -m colcon --help 2> import.log
python3 -m tuna import.log
I was running this on wsl2:
$ uname -a
Linux midnight 5.15.90.1-microsoft-standard-WSL2 #1 SMP Fri Jan 27 02:56:13 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
I am using the default colcon installed by following ros2 tutorials. I would guess common-extensions is pulling in other extensions.
python3-colcon-common-extensions/jammy,now 0.3.0-1 all [installed,automatic]
Why does the powershell extension take so long? Then, everything else is still pretty slow just to get to the help message.
Not trying to gold-plate anything (and improvements here would definitely be useful), but since you mention running WSL2: it could be this is the file system performance of Linux-in-WSL2 bottlenecking Colcon startup times.
Colcon does a bunch of entry-point detection and other work which needs to access the file system. That makes it mostly IO bound in my experience, at least until it gets to actually starting a build. Performance under Windows (with or without WSL) has never been comparable to any Linux.
Thanks for the follow up here, @alecGraves! I think I ended up getting a bit discouraged that in a large workspace, the startup time was about evenly split between package crawling and plugin discovery— both of these could be cached in various ways, but it came to feel like entry-point caching is more of a Python ecosystem problem, potentially to be solved that way: https://github.com/takluyver/entrypoints/issues/16
And it wasn't clear that startup time for large workspaces even matters much, to anyone other than me haha.
Ultimately, if we really care about colcon having a snappy CLI experience, it probably needs to go the way of Bazel— fork off a tiny "server" process that hangs out with the plugins already loaded, and can avoid re-crawling packages by monitoring the source directory with inotify watchers. But that's a lot of potential complexity and it's not clear to me how cleanly it could be done without a major upheaval in the design of colcon.
Idk, what IO-bound operations would be needed running colcon --help in an empty directory? It should just be (and is, based on the import graph I made) only time wasted importing python libraries. Some of the problem could probably be alleviated if colcon knew what keywords different extensions operated on and only loaded extensions if necessary (thus, --help would import nothing).
Agreed, the large directory structure and module/estension structure make colcon very difficult to modify in a way that would improve the startup time. It could be time for a large refactor of the python code (which necessarily includes all of the extensions as well), a specialized C program, or a nice old-fashioned Makefile for ros2 projects.
Idk, what IO-bound operations would be needed running colcon --help in an empty directory?
at the very least it needs to figure out what verbs are installed/available. Plugins can contribute to the --help output as well.
All the operations that do anything meaningful have to discover and load the plugins anyway, so I don't see a ton of value in special-casing --help in that regard just to make it super fast.
The fix has got to be either making plugin loading dramatically faster with some kind of caching scheme, or else finding a way to do it ahead of time—whether that's a full client-server model for colcon, or perhaps something more minimal like just forking off warm instances of itself, as described here: http://www.draketo.de/book/export/html/498
This latter solution could probably be mostly implemented outside of colcon itself, so long as the startup code has a clear separation and checkpoint position between "imported all dependencies/plugins" and "ready to start doing the actual work requested by the user".