cartographer
 cartographer copied to clipboard
cartographer copied to clipboard
Merging of multiple pbstreams
Hi.
I use the Cartographer for pure localization mode. For my use case it is necessary to update certain areas of the map regularly. However, I want to avoid having to re-record the entire map each time. Therefore I would like to compose an overall map from several individual maps. Since not all areas of the map are relevant for localization, it is not a problem if the individual maps do not overlap. The following pictures should clarify the situation.
Overall Map:
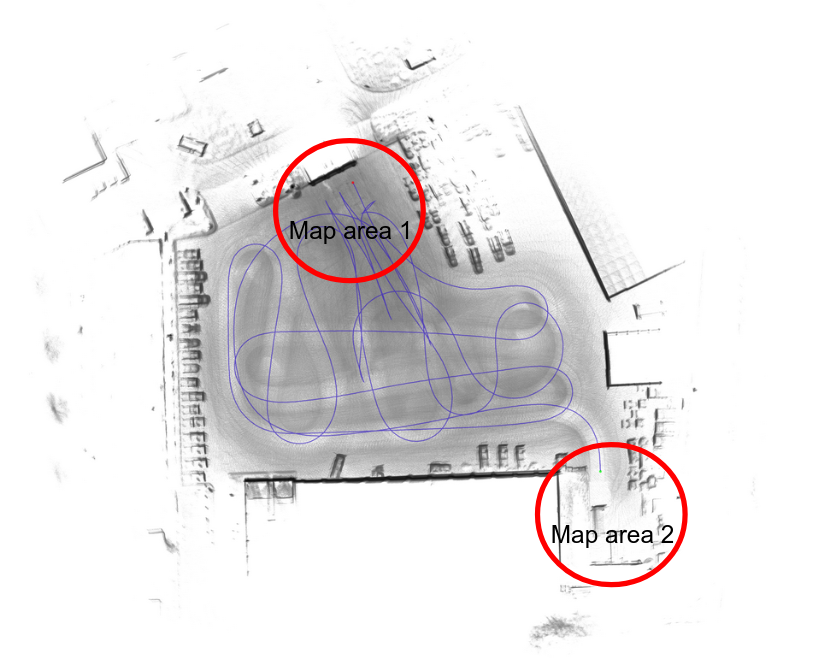
Individual map 1:

Individual map 2:
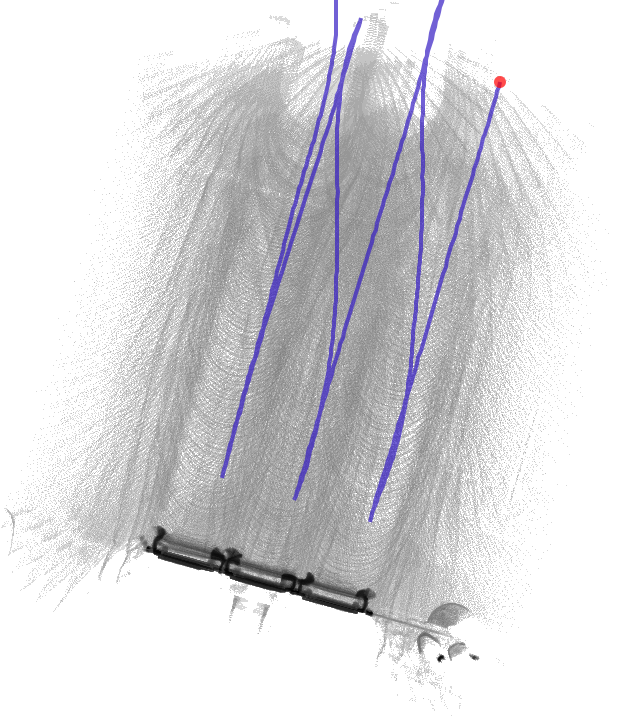
Merged Map:

My questions:
- Is it possible to merge multiple pbstreams into one map/pbstream that i can use for pure localization mode? I already figured out how to read pbstreams in python and get the stored information. For this I use the code below. However, I don't know how to merge multiple pbstreams and save them as a new pbstream. Can anyone help me with this?
import struct
from gzip import GzipFile
import io
import sys
sys.path.append("/cartographer_py")
import cartographer.mapping
import cartographer.mapping.proto.pose_graph_pb2
import cartographer.mapping.proto.serialization_pb2
def read_size(pose_graph_file):
buf = pose_graph_file.read(8)
if len(buf) < 8:
return 0
return struct.unpack_from("<Q", buf)[0]
def decompress(data):
with GzipFile(fileobj=io.BytesIO(data)) as f:
return f.read()
def read_serialized_data(pose_graph_file, ser_data):
sz = read_size(pose_graph_file)
if sz == 0:
return False
buf = pose_graph_file.read(sz)
buf = decompress(buf)
sd = cartographer.mapping.proto.serialization_pb2.SerializedData()
sd.ParseFromString(buf)
ser_data.append(sd)
return True
#Read pbstream information
ser_data = []
pose_graph_file = open(pbstream, 'rb')
while True:
try:
read_data = read_serialized_data("file.pbstream", ser_data)
if not read_data:
break
except:
read_data = read_serialized_data(pose_graph_file, ser_data)
if not read_data:
break
#Save information in variables:
pose_graph = [ s.pose_graph for s in ser_data if s.WhichOneof("data") == "pose_graph" ]
nodes = [ s.node for s in ser_data if s.WhichOneof("data") == "node" ]
trajectory_data = [ s.trajectory_data for s in ser_data if s.WhichOneof("data") == "trajectory_data" ]
submaps = [ s.submap for s in ser_data if s.WhichOneof("data") == "submap" ]
all_trajectory_builder_options = [ s.all_trajectory_builder_options for s in ser_data if s.WhichOneof("data") == "all_trajectory_builder_options" ]
imu_data = [ s.imu_data for s in ser_data if s.WhichOneof("data") == "imu_data"]
odometry_data = [ s.imu_data for s in ser_data if s.WhichOneof("data") == "odometry_data"]
fixed_frame_pose_data = [ s.imu_data for s in ser_data if s.WhichOneof("data") == "fixed_frame_pose_data"]
landmark_data = [ s.imu_data for s in ser_data if s.WhichOneof("data") == "landmark_data"]
- Before I can merge the pbstreams, I have to arrange them correctly. Otherwise, they would simply overlap, since the origin of each frame is at the beginning of the trajectory. To do this, I need to apply a translation and a rotation to the pbstream content. Is it possible to simply "move" the submap origin or do I need to consider other things?
I hope someone can help me, as I am currently stuck. I would be very grateful for any help!
Many thanks in advance, Lukas
What you want to achieve is merging 2 pose graphs. In cartographer's map builder this would be possible by using LoadState two times for each of your files. But there's no direct way to add an offset to one of these loaded states (at least none that I know from top of my head atm).
Given that loading a pose graph state requires a bit more than just loading the proto data (see https://github.com/cartographer-project/cartographer/blob/105c034577220268cd28a304a185adbec46b729f/cartographer/mapping/map_builder.cc#L216), I'm not sure if this would be a trivial thing to do in a Python script. Theoretically, it should be possible though.