blog
 blog copied to clipboard
blog copied to clipboard
02_SYS_RUST_文件IO
声明:本文知识树和Linux的知识点来源于《Beginning Linux Programming 4th Edition, Neil Matthew/Richard Stones》。只是替换了其中C语言部分,对应到RUST上。RUST的知识点来源于RUST官方文档手册、《Programming Rust: Fast, Safe Systems Development》等。本文的目的是让Linux的C语言选手快速转向Linux的Rust语言。
- Linux文件结构:
- 目录
- 文件和设备
- 系统调用和驱动
- 库函数
- 底层文件访问
- write系统调用
- read系统调用
- open系统调用
- 访问权限和初始值
- 其他与文件管理有关的系统调用
- 格式化输入输出
- 文件和目录维护
- 错误处理
- fcntl和mmap
底层文件访问
Rust标准库针对输入输出的特性是通过3个特型,即Read、BufRead和Write。
Write特型
在Linux C中,使用系统调用write把缓冲buf的前nbytes字节写入文件描述符所关联的文件中。write调用成功之后返回实际写入的字节数。如果文件描述符在写入过程中有错误或者设备驱动对于写入长度敏感,那么返回值可能小于请求写入的长度nbytes。如果函数返回0则没有写入任何数据;如果长度返回是-1,就表示调用write的时候出现了错误。
在Rust中,是通过Write特型进行写入。实现Write的值既支持字节输出也支持UTF-8的文本输出,这些值叫做Wrtiter(写入器)。
Write在std::fs::Write中进行了实现。可以参考 https://doc.rust-lang.org/std/fs/struct.File.html 。
Linux C中提供了标准输入输出的fwrite函数及系统调用write函数。在标准输入输出中,Linux会自动分配缓存。Rust中的Write方法更和Linux C的fwrite标准IO函数对标。
根据fwrite的官方文档, https://man7.org/linux/man-pages/man3/fwrite.3p.html 。fwrite的接口表示为:
#include <stdio.h>
size_t fwrite(const void *restrict _ptr_,
size_t _size_,
size_t _nitems_,
FILE *restrict _stream_);
Rust中的文件处理远比Linux C的丰富,可以参考 https://doc.rust-lang.org/std/io/trait.Write.html#provided-methods 。我这里只整理几个常用的例子:
在开发的时候经常用到(UTF-8)ASCII的写入。Rust提供 write 方法可以实现ASCII的写入。
use std::io::prelude::*;
use std::fs::File;
pub fn write_file_ascii(file_name:&str, content:String) -> Result<(), io::Error> {
let mut f = File::create(str);
let rc = match f.write(content.as_bytes()) {
Ok(_) => Ok(()),
Err(error) => return Err(error),
};
return rc;
}
Rust也提供了write!的宏,也可以达到和上面一样的效果。以下例子展示多种write写入字符串的方法,可以根据自己的实际需求使用。
use std::io::prelude::*;
use std::fs::File;
pub fn write_file_ascii() -> Result<(), io::Error> {
let mut buffer = File::create(str)?;
write!(buffer, "hello")?;
write!(buffer, "{:.*}", 2, 1.234567)?;
buffer.write_fmt(format_args!("{:.*}", 2, 1.234567))?;
return rc;
}
以上是访问ASCII的例子,下面展示一些写入二进制的方法:
pub fn write_file_bin(file_name:&str, buf:&Vec<u8>) -> Result<usize, io::Error> {
let mut ctx = File::create(str)?;
let buf_slice:&[u8] = &buf;
ctx.write_all(buf_slice)?;
ctx.write_all(b"some bytes")?;
return Ok(());
}
也可以写入多个buffer:
#![feature(write_all_vectored)]
use std::io::IoSlice;
use std::io::prelude::*;
use std::fs::File;
use std::io::{Write, IoSlice};
let mut writer = Vec::new();
let bufs = &mut [
IoSlice::new(&[1]),
IoSlice::new(&[2, 3]),
IoSlice::new(&[4, 5, 6]),
];
writer.write_all_vectored(bufs)?;
// Note: the contents of `bufs` is now undefined, see the Notes section.
assert_eq!(writer, &[1, 2, 3, 4, 5, 6]);
写入器
Rust的println!本质就是一个写入器,只不过这个写入器被包装成了向stdio进行写入。Rust提供writeln!的宏可以写入数据。
writeln!(io:stderr(), "error: world not helloable")?;
writeln!(&mut byte_vec, "The greatest common divisor of {:?} is {}",
numbers, d)?;
writeln相比于println多了一个错误处理,一定要处理Result的结果。
给writer加缓冲器
可以给Writer加入缓冲器
let file = File::create("tmp.txt")?;
let writer = BufWriter::new(file);
要设定缓冲区大小BufWriter::with_capacity(size, writer)
Read特型
在Linux C中,https://man7.org/linux/man-pages/man3/fread.3.html 表述了fread函数的作用。
#include <stdio.h>
size_t fread(void *restrict ptr, size_t size, size_t nmemb,
FILE *restrict stream);
从文件描述符关联的文件中读取nbytes个字节的数据,并把他们放在buffer中,返回读入的字节数。
下面是读取ASCII字符的方法:
pub fn read_file_ascii(file_name:&str) -> Result<String, io::Error>
{
let rc:Result<String, io::Error>;
let mut ctx = match File::open(file_name)?;
let mut read_str:String = String::new();
ctx.read_to_string(&mut read_str).unwrap();
rc = Ok(read_str);
return rc;
}
下面是读取二进制的方法:
全部读取:
pub fn read_file_binary(file_name:&str) -> Result<Vec<u8>, io::Error>
{
let rc:Result<Vec<u8>, io::Error>;
let mut ctx = match File::open(file_name)?;
let mut ret_vec:Vec<u8> = vec![];
ctx.read_to_end(&mut ret_vec).unwrap();
rc = Ok(ret_vec);
return rc;
}
读取指定字节数,例如读取128字节的数字,定义一个128的元组:
let mut buffer:[u8;128] = [0; 128];
ctx.read(&mut buffer)?;
和Linux C同样,返回的数据长度可能小于请求长度。
除了这些特型之外,还有4个迭代器的方法:
-
reader.bytes()返回输入流字节的迭代器。迭代器的类型是io::Result<u8>,因此每个字节都需要错误检查。另外,这个方法对每个字节都会调用一次reader.read(),这就导致了迭代器的效率非常低; -
reader.chars()和上面一样,只不过返回的类型是UTF-8。无效的UTF-8导致错误,效率也非常低; -
reader.chain(reader2)返回新的读取器,产生reader的所有输入和reader2的所有输入。 -
reader.take(n)返回新的读取器,与reader的读取器读入源是一样的只不过读取n个字节。
缓冲读取器
为了提高效率,reader和writer可以缓冲起来。所谓buffer,简单的说就是分配一块内存,以空间来换速度。有了缓冲器的好处就是减少系统调用。要知道read和write的系统调用机制非常复杂,需要透过用户空间进入内核空间,这一系列的切换都是有开销的。如果我们实现一个函数,包装read和write的操作,把数据积累到一定的程度之后,再一起发起系统调用,这样就减少了开销。但同时,如果一些write和read特型下层抽象了一些时间敏感的驱动,这就在时序上发生了问题。
在Linux C中,我们会发现,read和write系统调用和,stdio.h中的fread和fwrite都可以对文件进行操作。实际上在标准输入输出流中的函数在系统调用的基础上增加了缓冲区。所以在写完之后,需要进行fflush操作,把缓冲区的数据发起系统调用写入内核中,如果是内核写入到磁盘中还需要fsync。增加缓冲区的设计随处可见,例如Linux系统的U盘,写完之后还需要sync一样的道理。
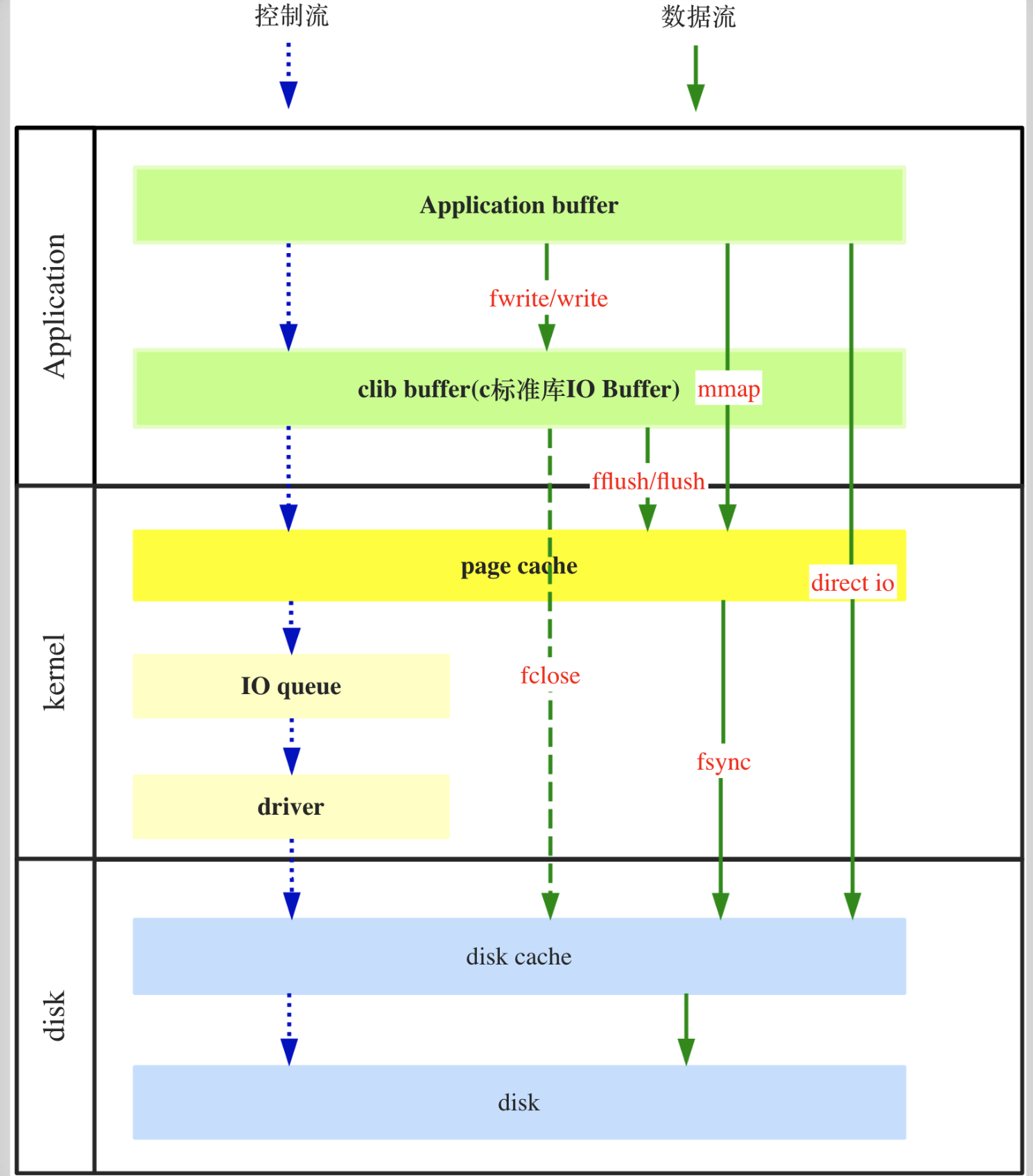
在一般情况下,几乎所有设备都可以使用缓冲区进行读写操作,包括文件、磁盘、网络套接字等。缓冲区的使用可以提高读写操作的效率,减少系统调用的次数。
然而,某些特殊设备可能不支持使用缓冲区。这些设备通常是以字符为单位进行读写,并且要求实时性非常高,不能进行延迟或缓冲。一些例子包括串口设备(Serial Port)、某些类型的传感器、实时采集设备等。
对于这些特殊设备,通常需要使用系统调用函数(如write和read)直接进行数据的逐字节读写,而不使用缓冲区。这样可以确保数据的即时传输和实时性要求的满足。
受Linux系统设计的影响,在Rust中也是一样的有非缓冲和缓冲读操作。上面的reader实现的特型read()就是直接进行系统调用。而使用缓冲的方法就是Rust比较推荐的BufRead。Rust特型之间的继承使之BufRead继承Read。
// 使用BufReader包装原始Reader
let mut buf_reader = BufReader::new(reader);
// 现在,它具有了BufRead Trait中的所有功能
for line in buf_reader.lines() {
// xxx
}
BufRead提供以下几种特型:
-
reader.read_line(&mut line)读取一行文本并追加到line,line是一种String。行位的换行符\n也会在line中。如果是Windows那么\r\n也会在line中; -
reader.lines()返回输入行的迭代器。迭代类型是io::Result<String>。换行符不会被包含在String中。 -
reader.read_until(stop_byte, &mut byte_vec)与read_line相似; -
reader.split(stop_byte)与lines相似,产生的只不过以字节为单位。
BufRead还提供了比较low-level的方法,.fill_buf和.consume(n)用于直接访问读取器内部的缓冲。
我们来介绍几个使用BufRead的例子
读取文本行
grep命令在Linux中是比较常用的命令,可以配合管道对管道内的数据进行搜索,以下是管道内的数据进行搜索的例程:
use std::io;
use std::io::prelude::*;
fn grep(target: &str) -> io::Result<()>
{
let stdin = io::stdin();
for line_result in stdin.lock().lines() {
let line = line_result?;
if line.contains(target) {
println!("{}", line);
}
}
return Ok(());
}
非常简单。但是我们考虑一下,以上是管道内的数据搜索,管道内的数据是缓冲区内的数据,因此使用lines()是没有问题的。那如果是磁盘上的数据呢?
磁盘上的数据需要被kernel进行加载再通过系统调用进入用户空间。那么我们这么读取:
pub fn grep_in_disk<R>(target: &str, reader: R) -> io::Result<()>
where R : BufRead
{
for line_result in reader.lines() {
let line = line_result?;
if line.contains(target) {
println!("{}", line);
}
}
return Ok(());
}
或者不需要使用 for 循环一个一个对?进行处理:
pub fn grep_in_disk<R>(target: &str, reader: R) -> io::Result<()>
where R : BufRead
{
let lines = reader.lines().collect::<io::Result<Vec<String>>>()?;
return Ok(());
}
RUST很贴心,对于这种wrapping的格式可以使用迭代器直接转换成相应的类型。FromIterator
impl <T, E, C> FromIterator<Result<T, E>> for Result<C, E>
where C: FromIterator<T>
{
// ...
}
我们可以这样调用:
use std::io::BufReader;
use std::fs::File;
#[test]
fn tool_test_grep() {
let stdin = io::stdin();
tools::grep_in_disk("hello", stdin.lock());
let f = File::open("hello.txt");
tools::grep_in_disk("hello", BufReader::new(f));
}
注意,File不会自动的创建缓冲器,因为实现是Read而不是ReadBuf。不过我们可以直接使用BufReader::new方法直接为文件句柄创建缓冲器。配置缓冲大小可以使用BufReader.with_capacity(size, reader)完成。