Sparkle
Sparkle
1. Show more detail error information 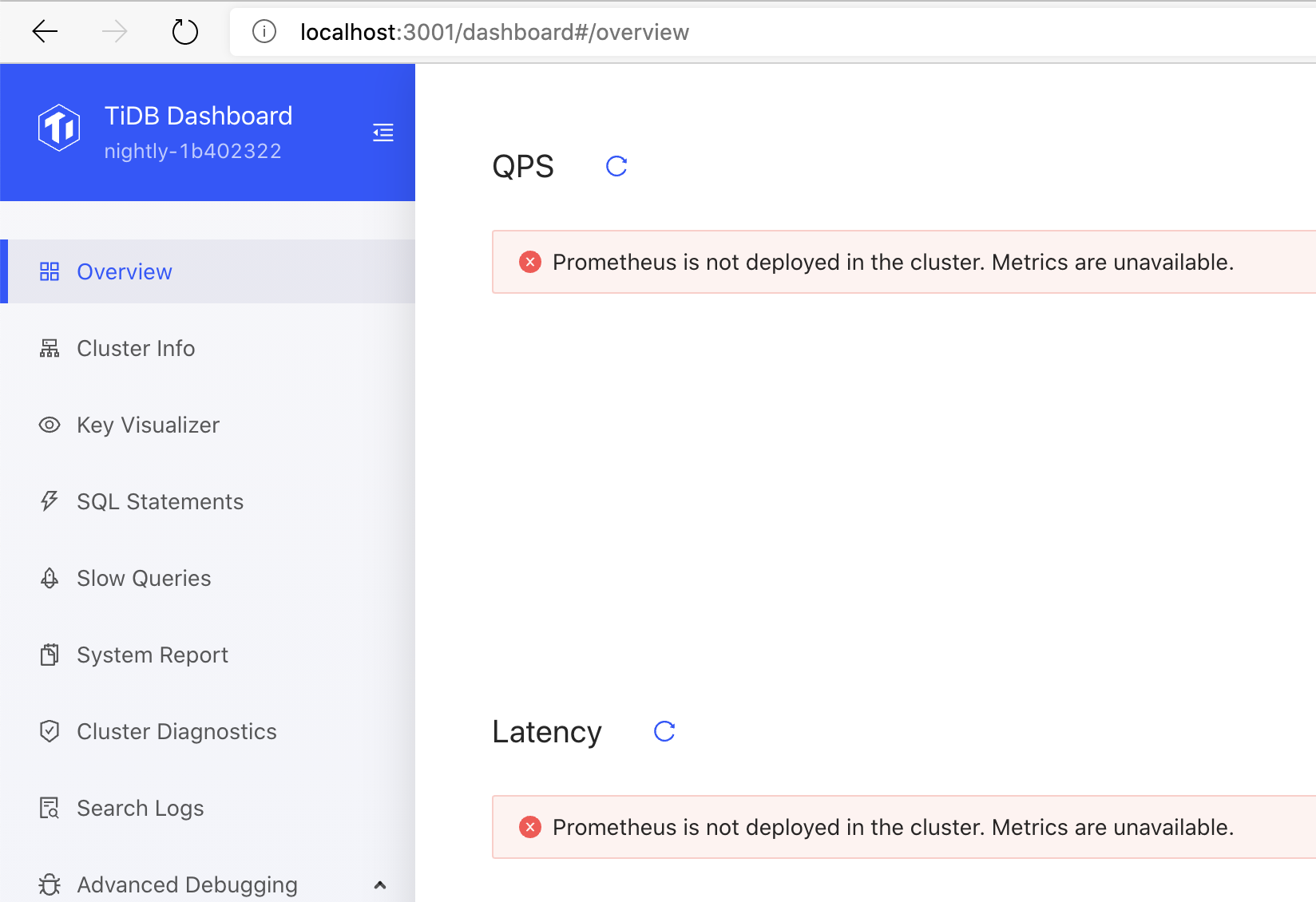 1. show one error is enough 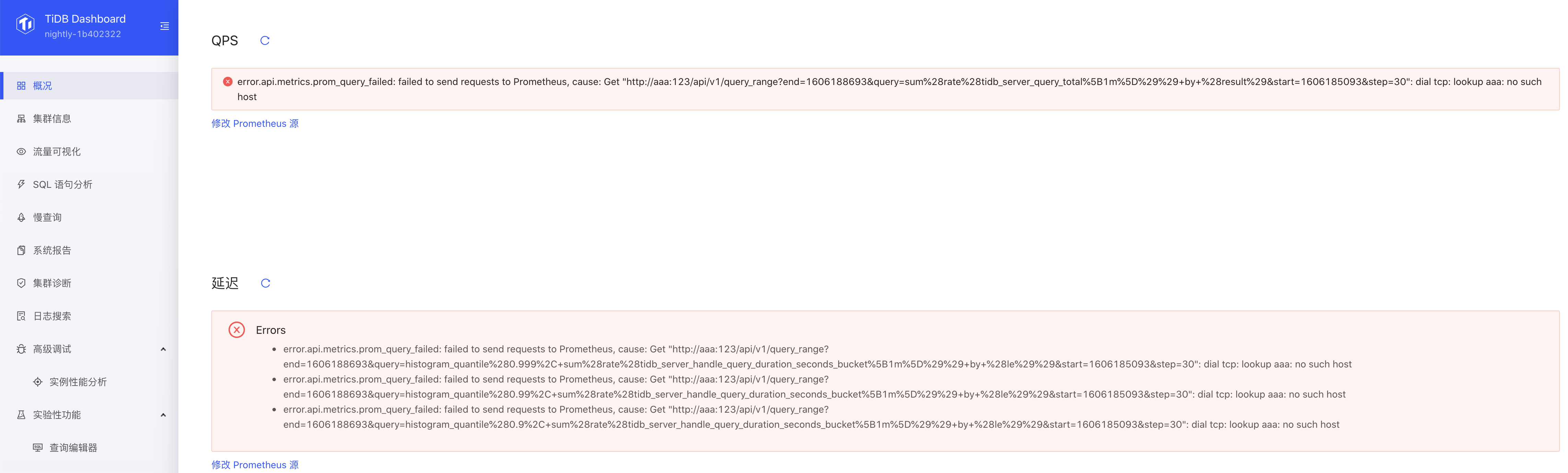 1. too long error message overflow 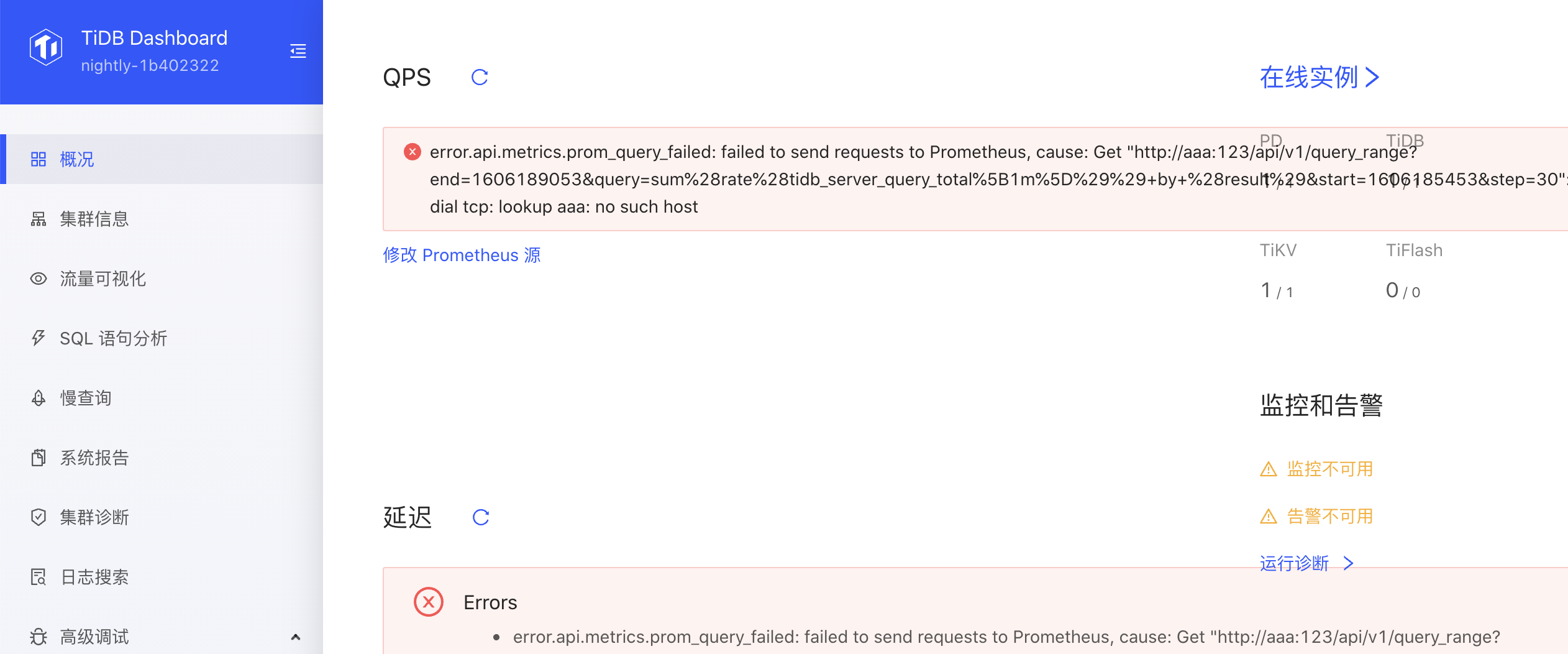
> @baurine We also have other kind of timeouts, like proxy timeout. Could you confirm this behaviour? (e.g. whether increasing the proxy timeout is necessary). ok, I will check it.
Some features have broken, still fixing them.
support show audit list in the web UI: 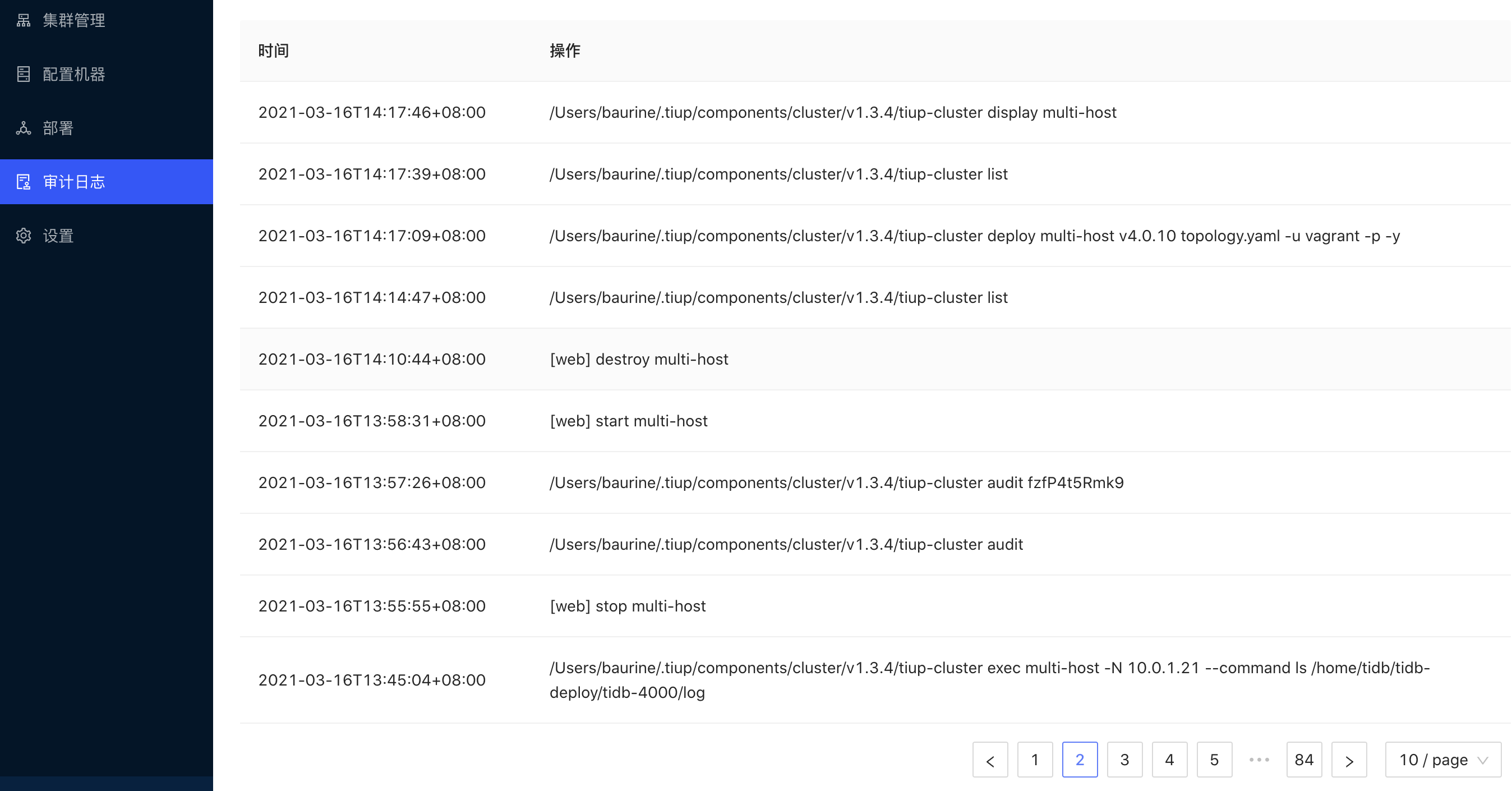
current support backup the cluster periodically:
support downgrade a cluster: 
- The link about how to use [pd-ctl](https://docs.pingcap.com/zh/tidb/stable/pd-control#pd-control-%E4%BD%BF%E7%94%A8%E8%AF%B4%E6%98%8E) - The link about [how PD works](https://docs.pingcap.com/zh/tidb/stable/tidb-scheduling)
sorry for just seeing this issue, let me have a look.
hi @dveeden sorry for the late reply, recently I am handling a similar issue. For this case, according to the console information and code logic, it is because there is...
> @baurine I see the same error message. I deployed a minimum cluster following this: https://docs.pingcap.com/tidb-in-kubernetes/stable/get-started. > > hi @xpepermint , yep, I found the root cause, it is because...