Complextext2animation
 Complextext2animation copied to clipboard
Complextext2animation copied to clipboard
About usage of text description
Hi, thanks for your great work on ICCV. I have a question about the usage of text description. As we know, there could be multiple description for each motion animation. However, the proposed method is one-to-one mapping deterministic method. Do we also use mutiple descriptions for each motion during training, or we just keep using one specific description?
Hi, thanks for your interest in our work. The method is trained with multiple text descriptions for a motion. You'll find the dataset has multiple annotations for the same kind of action so it's more of a many -to-one mapping. We also used a pose discriminator to train the model so it's not deterministic.
Thanks for your reply. I have two further questions if you don't mind. During training, how do you deal with the variable length of training motions? During inference, does the proposed method use the ground truth initial pose, and motion length (Number of frames)?
Hi, we downsample the training data to a fixed length. Yes, during inference the method uses the ground truth initial pose and we can mention the number of frames we want to generate (we have trained with 32 frames).
Hi,
When you are evaluating your method against the ground truth motion, which text sequence do you use? (if there are several available for a particular sequence)
As your output has a fixed size, how do you compare with previous work for the evaluation?
Thanks for your help
Hi, in the data preprocessing, we create a one-to-one mapping with the text description and pose sequence and use that as our ground truth data. Previous work like language2pose also has fixed output size. We calculate the mean position and variance metrics so evaluation can be done for a fixed sequence length for previous methods as well.
Ok thanks, to be sure I get it, given a motion M1 with the annotations A1/B1/C1, M2 with the annotations A2/B2, you will create (M1/A1), (M1/B1), (M1/C1), (M2/A2) and (M2/B2)?
About the metric computation, I still did not understand. For example with the APE:
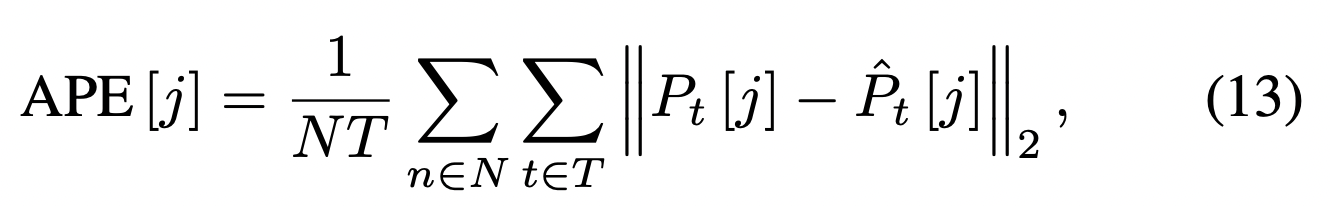
Let say hypothetically that:
- the ground truth P^hat has 40 frames, so t varies between 0 -> 39.
- your generation P^ghosh have 32 frames, so t varies between 0 -> 31.
- language2pose P^jl2p have 35 frames, so t varies between 0 -> 34.
How do you compute "P^ghosh_t - P^hat_t"? What will we the "t"?
Ok thanks, to be sure I get it, given a motion M1 with the annotations A1/B1/C1, M2 with the annotations A2/B2, you will create (M1/A1), (M1/B1), (M1/C1), (M2/A2) and (M2/B2)?
- Yes, we create such pairs during data preprocessing.
How do you compute "P^ghosh_t - P^hat_t"? What will we the "t"?
- During evaluation you can take fixed number of timesteps (for us t=32). We have downsampled the dataset and taken first 32 frames to train and evaluate. We have done the same with jl2p for comparison.
Thanks it is much clear now.
I have another question about the number of data for the test set. When I sample the sequences with the command:
python sample_wordConditioned.py -load save/ghosh/exp_124_cpk_2stream_h_model_nocurriculum_time_32_weights.p
I noticed that in the folder save/ghosh/exp_124_cpk_2stream_h_model_nocurriculum_time_32/test/ there is only 520 sequences. Whereas, in language2pose, I got 587 sequences for the test set. The 520 sequences are a subset of the 587.
Are you removing some sequences at some point?