blog
 blog copied to clipboard
blog copied to clipboard
个人博客,记录个人总结(见issues)

本文主要讲解一下阿里巴巴开源的消息队列中间件RocketMQ的producer客户端的发送流程,并简单与Kafka的实现方式做一些对比,希望能够对如何实现一个高性能网络客户端有个大致的了解。 # 正文 首先我们看一下Producer的继承结构:  MQAdmin主要包含一些管理性的接口,比如创建topic、查询某个特定消息以方便排查问题,ClientConfig主要定义了一些基本的配置,比如持久化consumer端消费offset的间隔时间(offset就是consumer端当前消费到的位置,offset的持久化机制也决定了是exactly once 还是根据时间戳等消费),然后再来看DefaultMQProducer,我们发现它将具体的实现都代理给了DefaultMQProducerImpl去做,这个类主要包含了不同的send方法,同步、异步、oneway(发出去就不管了,比如可以用于日志同步)。 ```java SendResult send(final Message msg) throws MQClientException, RemotingException, MQBrokerException, InterruptedException; SendResult send(final Message msg, final long timeout) throws MQClientException, RemotingException, MQBrokerException, InterruptedException;...
## 前言 最近一段时间,各大厂商故障频发,就在上个月Cloudflare就出现了一次持续六个多小时的故障,接口的成功率下降至75%左右,并且管理后台已经几乎不可用,比平常慢了80多倍。Cloudflare也给出了一份详细的故障报告,[ A Byzantine failure in the real world](https://blog.cloudflare.com/a-byzantine-failure-in-the-real-world/), 简单来讲就是由于交换机异常,导致出现了网络丢包,etcd集群无法正常通讯导致无法正常对外提供服务,而上游业务强依赖etcd,导致服务出现异常。 ## 故障原因 >在一些需要强一致的场景下,Cloudflare大量使用了etcd来作为底层的存储层,这样即使其中少数节点挂掉,集群仍然能够正常对外提供服务,避免了单点问题。 首先在某一时间点,交换机出现异常(并且触发了内部的告警,无法通过ping连接到交换机),此时并没有完全挂掉,而只是出现部分节点网络丢包,因此没有触发自动切换机制(交换机有2个节点互备,非单点)。六分钟后,交换机在没有人为干预的情况下自动恢复了,但这几分钟的网络异常却导致了更严重的问题。异常交换机所在的机架上部署了etcd集群其中一个节点。而在交换机出现异常一分钟后,etcd集群节点之间通讯异常,导致无法选举出一个稳定的leader,集群无法正常对外提供读写服务:  - 节点1(部署在受影响机架上的节点)和节点3(当前leader)发生网络丢包 - 节点1和节点2之前的网络通讯正常 - 节点2和节点3之间的网络正常 由于节点1无法与当前leader节点3正常进行通讯,因此当选举超时后,在节点1的视角下,当前leader已经挂掉,因此会转到candidate,增加自己的term并尝试发起选举,节点2收到投票后,会更新自己的term,然后告诉节点3你已经不是leader了。但由于节点3无法和节点1进行正常通讯,因此超时后节点3会重复刚刚的动作,增加自己的term并尝试发起选举。整个集群选举无法出一个稳定的leader,导致无法正常对外提供读写服务。 > 这里只是举例其中一种可能发生的情况,也有可能节点1的日志落后于其他两个节点,因此节点2会拒绝节点1的选举请求,会投票给节点3,因此节点3仍然当选为leader,但是由于节点1无法与节点3(leader)正常通讯,因此超时后又会重复发起投票,而选举期间写入会阻塞,进而影响对外服务。 我们记得在Raft原始的论文中提到过: > [Consensus algorithms] are...
## 前言 假设你正在开发一个电商网站,那么这里会涉及到很多后端的微服务,比如会员、商品、推荐服务等等。  那么这里就会遇到一个问题,APP/Browser怎么去访问这些后端的服务? 如果业务比较简单的话,可以给每个业务都分配一个独立的域名(`https://service.api.company.com`),但这种方式会有几个问题: - 每个业务都会需要鉴权、限流、权限校验等逻辑,如果每个业务都各自为战,自己造轮子实现一遍,会很蛋疼,完全可以抽出来,放到一个统一的地方去做。 - 如果业务量比较简单的话,这种方式前期不会有什么问题,但随着业务越来越复杂,比如淘宝、亚马逊打开一个页面可能会涉及到数百个微服务协同工作,如果每一个微服务都分配一个域名的话,一方面客户端代码会很难维护,涉及到数百个域名,另一方面是连接数的瓶颈,想象一下你打开一个APP,通过抓包发现涉及到了数百个远程调用,这在移动端下会显得非常低效。 - 每上线一个新的服务,都需要运维参与,申请域名、配置Nginx等,当上线、下线服务器时,同样也需要运维参与,另外采用域名这种方式,对于环境的隔离也不太友好,调用者需要自己根据域名自己进行判断。 - 另外还有一个问题,后端每个微服务可能是由不同语言编写的、采用了不同的协议,比如HTTP、Dubbo、GRPC等,但是你不可能要求客户端去适配这么多种协议,这是一项非常有挑战的工作,项目会变的非常复杂且很难维护。 - 后期如果需要对微服务进行重构的话,也会变的非常麻烦,需要客户端配合你一起进行改造,比如商品服务,随着业务变的越来越复杂,后期需要进行拆分成多个微服务,这个时候对外提供的服务也需要拆分成多个,同时需要客户端配合你进行改造,非常蛋疼。 ## API Gateway 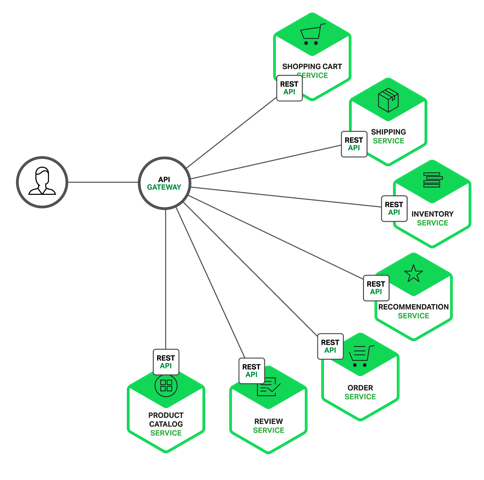 更好的方式是采用API网关,实现一个API网关接管所有的入口流量,类似Nginx的作用,将所有用户的请求转发给后端的服务器,但网关做的不仅仅只是简单的转发,也会针对流量做一些扩展,比如鉴权、限流、权限、熔断、协议转换、错误码统一、缓存、日志、监控、告警等,这样将通用的逻辑抽出来,由网关统一去做,业务方也能够更专注于业务逻辑,提升迭代的效率。 通过引入API网关,客户端只需要与API网关交互,而不用与各个业务方的接口分别通讯,但多引入一个组件就多引入了一个潜在的故障点,因此要实现一个高性能、稳定的网关,也会涉及到很多点。  #### API注册 业务方如何接入网关?一般来说有几种方式。 - 第一种采用插件扫描业务方的API,比如`Spring MVC`的注解,并结合`Swagger`的注解,从而实现参数校验、文档&&SDK生成等功能,扫描完成之后,需要上报到网关的存储服务。 -...
> 前段时间也写过几篇关于消息队列的博客, [分布式消息队列实现概要](https://github.com/aCoder2013/blog/issues/21) 这篇博客大致讲了一下实现一个分布式消息队列所需要考虑到的种种因素,本文就详细讲一下如何实现Partitioned topic,即分区消息队列 # 前言 说道message queue相信大家都不陌生,对于业务方来说很简单就是几个简单的API, 通常也不用关心其内部实现,但如果想要用好消息队列、出了问题能够cover的住,那就必须要能够了解其实现原理,知其然知其所以然。 首先Message queue有一个topic的概念,可以将其理解为日志,发消息的过程说白了其实就是打日志,而消息队列就是存储日志记录的持久层,类似java中的log4j、logback等日志系统,打了日志之后我们就会有一些分析需求,比如说用户过来一个请求,我们将参数、耗时、响应内容等打到日志中,然后会在本机部署一个agent用于抓取日志发送到jstorm集群中用于分析等。那这里我们的应用系统就对应消息队列中的生产者producer,jstorm集群就对应消费者consumer。 所以说白了其实消息队列和log4j这些组件都是日志系统,那么回到message queue的模型中去,如果我们的topic都是单分区的,那么也就是说所有的producer都是往这一个"文件"中打日志,那么这样的话性能必然会有很大的问题,类似日志系统,我们希望每台机器都能够有自己的日志文件,那么自然而然的我们就需要将单分区的topic扩展到多分区的topic。 # 生产者 生产者这边的实现相对来说比较简单,对于应用层来说我们提供一个统一的topic,比如说`hello-world`, 那么创建topic的时候,我们对内表示的时候会加一层映射`hello-world-> [hello-world-1,hello-world-2...]`,也就是说producer实际上是往对应的子topic发送消息的,但具体往哪个发送就需要一个路由策略,一般不要求顺序的话就直接轮训发送,如果需要顺序的话就用hash即可,这个信息直接存储到zookeeper即可,说到zookeeper这里简单提一下,zk并不能给客户单提供全局一致的视图,就是说对于两个不同的客户端,zk并不能保证他们能够在任一时间都能够读到完全相同的数据,这可能是由于网络延迟等原因造成,但如果客户端需要的话可以主动调用`sync()`先强制同步一把数据。 启动流程: 1. 和broker建立连接 2. 获取所有的topic列表 3. 根据指定的路由策略发送消息 # 消费者 消费者这边的话会比较麻烦一些,根据消息队列要提供的消费语义有不同的实现方案,如果要实现顺序性的话相对会复杂一些。 流程:...
> 声明:代码不是我写的=_= ## 现象 前两天碰到一个ribbon相关的问题,觉得值得简单记录一下。表象是对外的接口返回内部异常,这个是封装的统一错误信息,Spring的异常处理器catch到未捕获异常统一返回的信息。因此到日志平台查看实际的异常: ```java org.springframework.web.client.HttpClientErrorException: 404 null ``` 这里介绍一下背景,出现问题的开放网关,做点事情说白了就是转发对应的请求给后端的服务。这里用到了ribbon去做服务负载均衡、eureka负责服务发现。 这里出现404,首先看了下请求的url以及对应的参数,都没有发现问题,对应的后端服务也没有收到请求。这就比较诡异了,开始怀疑是ribbon或者Eureka的缓存导致请求到了错误的ip或端口,但由于日志中打印的是Eureka的serviceId而不是实际的ip:port,因此先加了个日志: ```java @Slf4j public class CustomHttpRequestInterceptor implements ClientHttpRequestInterceptor { @Override public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws...
# 前言 今天小伙伴遇到个小问题,线程池提交的任务如果没有catch异常,那么会抛到哪里去,之前倒是没研究过,本着实事求是的原则,看了一下代码。 # 正文 ### 小问题 考虑下面这段代码,有什么区别呢?你可以猜猜会不会有异常打出呢?如果打出来的话是在哪里?: ```java ExecutorService threadPool = Executors.newFixedThreadPool(1); threadPool.submit(() -> { Object obj = null; System.out.println(obj.toString()); }); threadPool.execute(() -> { Object obj = null; System.out.println(obj.toString());...
## Gossip协议是什么? 简单来说就是一种去中心化、点对点的数据广播协议,你可以把它理解为病毒的传播。A传染给B,B继续传染给C,如此下去。 协议本身只有一些简单的限制,状态更新的时间随着参与主机数的增长以对数的速率增长,即使是一些节点挂掉或者消息丢失也没关系。很多的分布式系统都用gossip 协议来解决自己遇到的一些难题。比如说服务发现框架`consul`就用了gossip协议( [Serf](https://www.serf.io/))来做管理主机的关系以及集群之间的消息广播,Cassandra也用到了这个协议,用来实现一些节点发现、健康检查等。 ## 通信流程 ### 概述 首先系统需要配置几个种子节点,比如说A、B, 每个参与的节点都会维护所有节点的状态,node->(Key,Value,Version),版本号较大的说明其数据较新,节点P只能直接更新它自己的状态,节点P只能间接的通过gossip协议来更新本机维护的其他节点的数据。 大致的过程如下, ① SYN:节点A向随机选择一些节点,这里可以只选择发送摘要,即不发送valus,避免消息过大 ② ACK:节点B接收到消息后,会将其与本地的合并,这里合并采用的是对比版本,版本较大的说明数据较新. 比如节点A向节点B发送数据C(key,value,2),而节点B本机存储的是C(key,value1,3),那么因为B的版本比较新,合并之后的数据就是B本机存储的数据,然后会发回A节点。 ③ ACK2:节点A接收到ACK消息,将其应用到本机的数据中 ```java A发GossipDigestSyn => B执行GossipDigestSynVerbHandler B发GossipDigestAck...
## 背景 当我们讨论分布式系统时,通常会说到CAP理论,而这里的C一致性一般来说指的就是线性一致性(Linearizability),而对于开发者来说,可能更多的会去关注自己平常使用的一些中间件、类库,比如Etcd、Zookeeper等能够提供怎么的一致性,这两个类库我们知道是在Raft、Paxos(ZAB)的基础之上实现的,因此这篇文章我们就来看一下如果线性一致性实际是如何实现的。 ## 实现 可能大多数人都有个误解,一个分布式系统,比如ZK、etcd等,如果正确的实现了共识算法(Raft/Paxos),那么它就能够提供强一致,这个理解其实是不正确的,Raft只能够保证不同节点对于raft日志达成一致,但对于库的使用者来说,实际上对外提供服务的是底层的状态机,比如说一个KV存储,每个raft日志记录的是实际的操作,比如`set a 1 set a 2`等,而如果只有日志的话,我们怎么查询呢?轮训一遍日志?显然不现实,因此必须将这个状态存起来,比如RocksDB,那么底层raft日志的一致性由raft本身去保证,而上层业务方状态机的一致性该如何去保证呢? Raft是由leader驱动的共识算法,所有的写入请求都由leader来处理,并将日志同步到follower,然后再将日志依次应用的自身的状态机,比如RocksDB,但由于网络延迟、机器负载等原因,每个节点不可能同时将日志应用到RocksDB,因此对于不同的节点来说,RocksDB的数据快照肯定不是实时一致的,并且这里会涉及到很多的corner case,比如leader切换,也就是说leader的数据也不一定是最新的,因此实际实现的时候需要考虑好这些case。 这里暂不考虑异常情况,对于raft来说,写请求都是由leader处理并同步到follower,因此leader的数据通常是最新的,但如果用户发来一个读取请求,我们直接从状态机读取的话,这里其实是会读到过期数据的,因此这里分为两步,已提交的日志 -> 已经应用到状态机的日志,因此如果不做特殊处理的话,由于还有部分日志没有应用到状态机,直接处理的话必然会造成不一致。优化的方法大致有几种: - 读取也走raft log - Read Index - Lease Read ### 读取也走raft log 我们很容易想到,让读取的请求也走一遍raft流程,由于raft日志是全局严格有序的,读写也必然是有序的,因此当处理到读取的日志的时候,能够保证之前的写入请求都已经处理完成并落到状态机,因此这个时候处理读取请求是安全的,不会造成过期读的问题,也能够满足我们说的线性一致性,但这个方法有个很明显的缺点: 性能非常低,每次读取都走一遍raft流程,涉及到网络、磁盘IO等资源,而对于大部分场景来说,都是写少读多,因此如果不对读取进行优化的话,整个类库的性能会非常低效。...
`java.util.concurrency.atomic.LongAdder`是Java8新增的一个类,提供了原子累计值的方法。根据文档的描述其性能要优于`AtomicLong`,下图是一个简单的测试对比(平台:MBP):  这里测试时基于JDK1.8进行的,AtomicLong 从Java8开始针对x86平台进行了优化,使用XADD替换了CAS操作,我们知道JUC下面提供的原子类都是基于Unsafe类实现的,并由Unsafe来提供CAS的能力。CAS (compare-and-swap)本质上是由现代CPU在硬件级实现的原子指令,允许进行无阻塞,多线程的数据操作同时兼顾了安全性以及效率。大部分情况下,CAS都能够提供不错的性能,但是在高竞争的情况下开销可能会成倍增长,具体的研究可以参考这篇[文章](https://arxiv.org/abs/1305.5800), 我们直接看下代码: ```java public class AtomicLong { public final long incrementAndGet() { return unsafe.getAndAddLong(this, valueOffset, 1L) + 1L; } } public final class Unsafe { public...
# 背景 今天分享下前段时间遇到的一个case,相信大家都有做过类似频率限制的东西,我们的也有类似的业务场景,某个接口或者功能需要限制用户一段时间内的访问量,我们的解决方案是通过Redis去做,一方面是由于Redis完全是内存访问性能比较高,另一方面系统是分布式的,如果是单机的或者说只需要限制单机访问的QPS那么可以采用`Guava`的`RateLimiter`。 # 现象 比如有这么一个场景,接口A限制用户30S内只能调用3次,但出现了一个诡异的现象是,已经过了这个时间还是不能调用,查看应用日志、外部依赖都没有发现异常。 # 问题定位 首先看一下应用最近有没有发布过,是不是新功能导致的,然而并没有。因为这段代码最近一直没有改动,而且一直没遇到过类似的问题,因此开始怀疑代码逻辑有漏洞,一层一层拨开迷雾,找到最核心的代码,伪码如下: ```java Jedis redis = getRedis(); try { redis.set(SafeEncoder.encode(key), SafeEncoder.encode(def + ""), "nx".getBytes(), "ex".getBytes(), exp); Long count = redis.incrBy(key.getBytes(), val); } finally...