Perry Li
Perry Li
**Feature 名称:** album 组件 lazy-load 特性支持 **简要描述:** 微信小程序官方提供的image组件中有一个 `lazy-load` 属性,该属性可以实现图片懒加载,在即将进入一定范围(上下三屏)时才开始加载,详情可见 https://developers.weixin.qq.com/miniprogram/dev/component/image.html#lazy-load **使用场景:** 图片较多的情况下能够实现加载速度的优化,节省CDN流量 **其他组件库或类似功能的截图:** 暂无
Use english '(' instead of chinese '('.
### Is your feature request related to a problem? Please describe. 作者您好 本人在进行 ChatGLM 全参微调的相关工作,但是发现模型中并没有 Dropout 机制的相关代码(除了 pre_seq_len 不为 null 对应的 ptuning 情况)。 很好奇,因而去看了 THUDM 发布的 GLM 预训练模型的代码,发现模型中是存在 Dropout 机制的。...
https://huggingface.co/THUDM/chatglm-6b
Hi, I'm trying use lightseq to accelerate [MarianMTModel](https://huggingface.co/docs/transformers/model_doc/marian) seq2seq inference. This model is basically same with BartForConditionalGeneration. There are two differences between MarianMTModel and BartForConditionalGeneration. 1. MarianMTModel use [swish](https://pytorch.org/docs/stable/generated/torch.nn.SiLU.html?highlight=silu#torch.nn.SiLU) activation...
尊敬的作者您好 关于每个数据集中生成的缓存文件 `kb_cache.json` `m2n_cache.json` `query_cache.json`,我有些小小的疑问 在您的代码文件 `code/KBQA_Runner.py` 中的 701-705 行,有这样几行被注释掉的代码: ```python model_to_save = policy.module if hasattr(policy, 'module') else policy torch.save(model_to_save.state_dict(), save_model_file) Save_KB_Files(convert_json_to_save(KB), save_kb_cache) Save_KB_Files(M2N, save_m2n_cache) Save_KB_Files(list(QUERY), save_query_cache) ``` 在我看来,这是在训练过程中动态生成以上三个缓存文件,然后将其保存。 但是当我在使用我本人的数据集(非freebase)时,训练过程中生成的这三个文件确是空的,是否需要用其他方式手动初始化?...
尊敬的作者,您好 我近日在学习您的代码,看到GAT层中,有一处代码,我较为疑惑 https://github.com/MrLeeeee/GCN-GAT-and-Graphsage/blob/42660722db60ad26ef5b342492e0f153d6e2e1bf/models/PyGAT.py#L161 该处的代码为什么有一个负号?按照原始论文给出的计算方式,这里应该直接用leaky relu激活函数后给出的结果即可 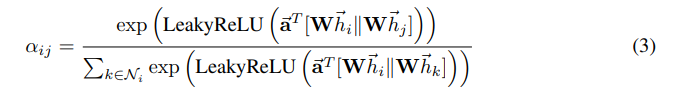 这样**添加一个负号**,是否有特殊的用意呢? 还望作者能在百忙之中抽出时间答复,感激不尽!
关于数据集的问题

尊敬的作者您好, 非常感谢您分享您的代码,您的研究工作对我的科研工作有很大的帮助。 关于您的训练数据我有一些问题,看到代码中 `run_config/train-enzh-self.json` 文件有 `/path/to/CLS_src/train_zh.text.wordseg.norm.bpe` 和 `/path/to/CLS_tgt/train_en.sum.norm.tok.lowercase.bpe` 这样的文件。我的理解是这里给出的应该是分词后的中英文文件。 想问一下您,具体分词的细节是怎么实现的,使用了什么分词器(是Google的sentencepiece吗)。能否给出更详细的数据处理流程呢? 非常感谢您在百忙之中解答我的问题! 再次感谢您的分享。
fix(deps): upgrade pydantic from v2.9.2 to v2.10.3+ in requirements.txt and pyproject.toml - Resolve firecrawl-py dependency conflict between firecrawl-py(>=2.10.3) and pinned pydantic(2.9.2) - Ensure compatibility with other Python packages by aligning...
Fix an issue where clicking inline citations in subsequent chat messages failed to open the citation modal when multiple collapsible sections are present. The root cause was duplicate "collapsible-sources" IDs...