YadongWei
![]()
![]()
YadongWei

## detail | 详细描述 | 詳細な説明 1.模型量化后bin size缩小了一倍,但是从float32->int8应该是缩小为原来的四分之一才对呀,有点奇怪,请大佬解惑。 2.量化后模型推理变慢了10%(cotex x2 thread number 4),为什么会变慢呢,我使用的模型是yolov5 nano x0.5,请大佬解惑。
**1. 使用环境(environment)** - OS: Docker **3. 详细描述bug 情况 (Describe the bug)** A clear and concise description of what the bug is. - issue type: 模型不对齐(model misalignment) - original model: ONNX...
## detail | 详细描述 | 詳細な説明 在ncnn上测试了一个算法的性能,有几个不太清楚的地方辛苦大佬帮忙看看: 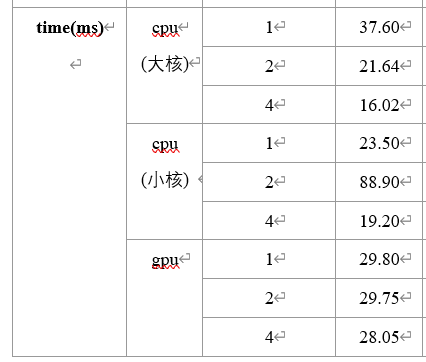 其中cpu大核指的是设置的cpu_powersave为2跑出来的数据,cpu小核指的是使用cpu_powersave为1跑出来的数据。 感觉疑惑的地方有两个: 1.为什么cpu大核单线程的速度慢于cpu小核单线程。 2.为什么cpu小核双线程的速度慢于小核单线程,而且慢了很多,看起来有点异常。
error log | 日志或报错信息 | ログ 原项目地址:https://github.com/derronqi/yolov7-face 关于ncnn的代码在https://github.com/derronqi/yolov7-face/tree/main/cpp 中,我用export.py完成模型到onnx的转换,然后使用最新版的pnnx完成onnx到ncnn的转换(也尝试过pt-> pt script->ncnn也有问题)。 [pt的模型地址](https://drive.google.com/file/d/1HNXd9EdS-BJ4dk7t1xJDFfr1JIHjd5yb/view?usp=sharing) 使用pt模型测试325*352的结果是正确的,但是转换为ncnn之后测试结果就不正确了,初步判断有可能是模型转换带来精度损失导致的。 context | 编译/运行环境 | バックグラウンド 最新版本的pnnx和ncnn how to reproduce | 复现步骤 | 再現方法 1.下载模型 2.使用https://github.com/derronqi/yolov7-face/blob/main/cpp/export.py 进行onnx转换 3.使用ncnn的转换工具pnnx把onnx模型转换为ncnn模型(shape...