Tendis
 Tendis copied to clipboard
Tendis copied to clipboard
Tendis is a high-performance distributed storage system fully compatible with the Redis protocol.

## Description 3主 4从 其中一台主shutdown,其从无法升主 日志分析如下: 主的相关日志:  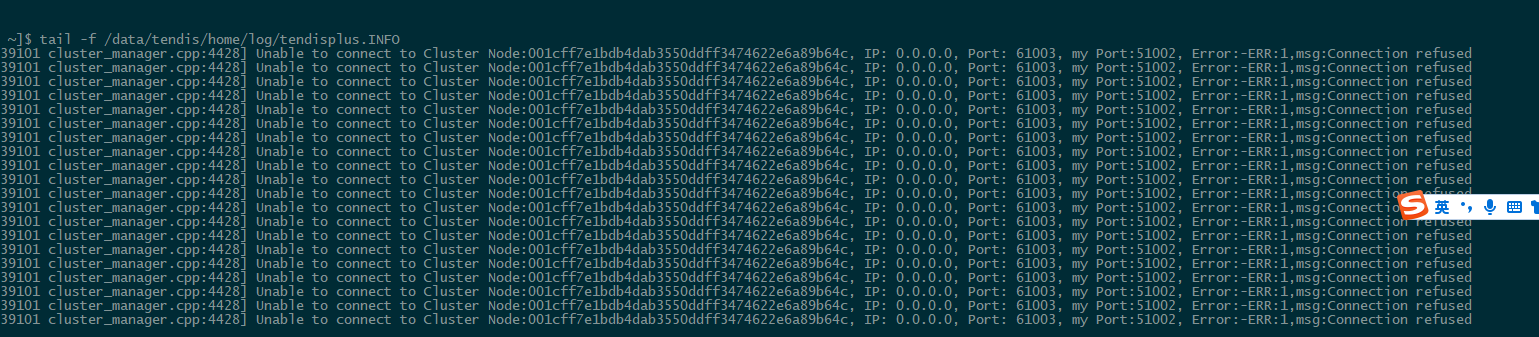 从的相关日志: 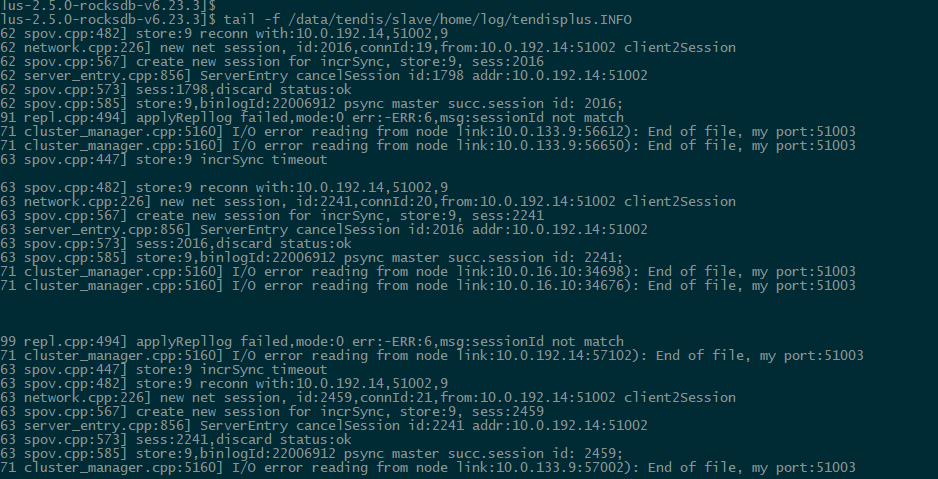 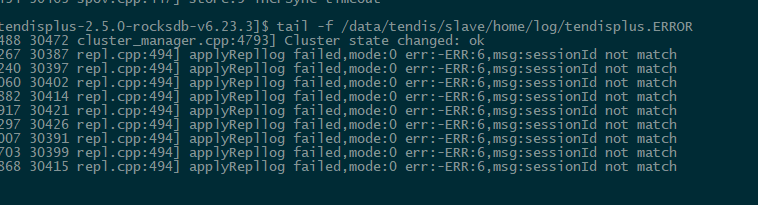 集群信息: 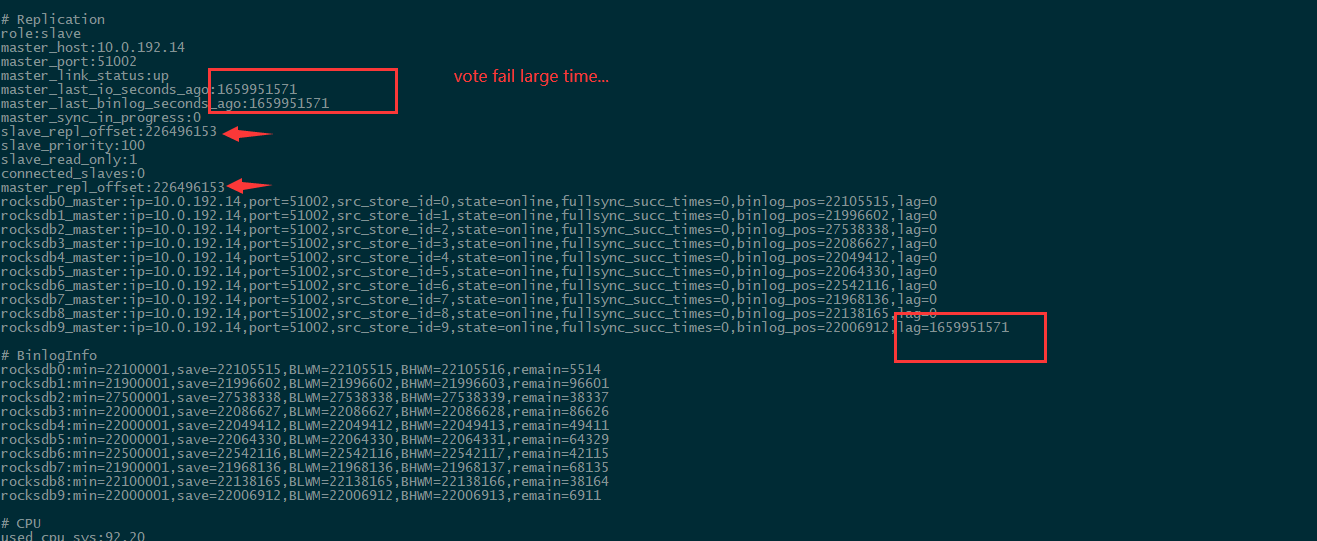 从机器报Error:vote fail 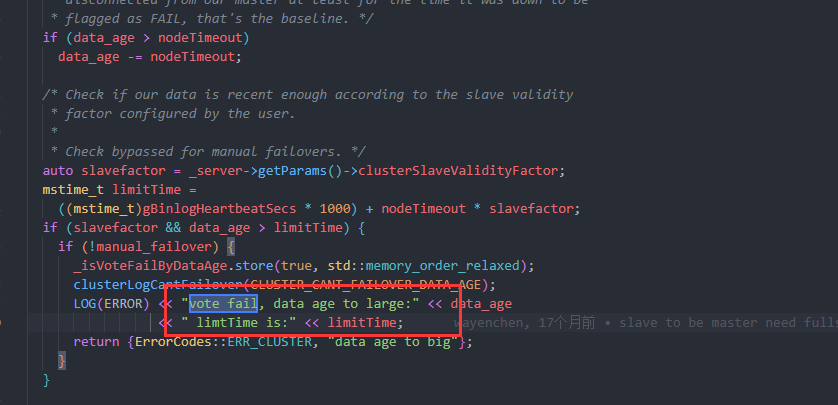 ------------------------- 从的同步一直报失败。测试其他的节点是可以顺利切主的。辛苦大佬给看下这个问题
## Description tendis集群的slave节点能支持读吗?或者可配请求的分布,比如3主3从, 3从(80%的读) + 3主(100%的写+20%的读) 实际业务中对读的要求较高。希望能通过从的水平扩展增大并发,即使数据尚未同步到从也可以接受短暂的延迟。 1当前从只是冷备功能吗?测试发现即使数据在自身,收到的请求也会Redirected到其所在的master 2 集群的从同步进度如何查看呢? 发现info replication的offset和master一致了 但是db还在写。  ----- 辛苦,感谢大佬答疑
您好,我对rocksdb修改了c++源代码,进行了优化,如何嵌入替换掉tendis原有的rocksdb,可否有详细的教程,谢谢您,麻烦帮忙解决一下!
编译生成的tendisplus执行文件,在执行的时候只是输出了如下日志就结束了,后台并没有启动服务,如何解决?请大佬明示~ [root@localhost tmp.Y1QIlpiVuL]# **./tendisplus tendisplus.conf** start server with cfg: allow-cross-slot:no aof-enabled:no aof-psync-num:500 bind:"127.0.0.1" binlog-enabled:yes binlog-save-logs:yes binlog-send-batch:256 binlog-send-bytes:16777216 binlog-using-defaultCF:no binlogDelRange:100000 binlogFileSecs:1200 binlogFileSizeMB:64 binlogRateLimitMB:64 checkkeytypeforsetcmd:no chunkSize:16384 cluster-allow-replica-migration:no cluster-enabled:no cluster-migration-barrier:1 cluster-migration-batch-size:16 cluster-migration-binlog-iters:10 cluster-migration-distance:10000...
tendisplus.conf中rocksdb可配置参数少于rocksdb原有的,如何配置rocksdb原有的参数?
## Description 背景:压测工具压了大批数据,memtier_benchmark -t1 -c1 -s -p --cluster-mode --ratio=1:1 -n5000 -d 512000000 (数据量io的瓶颈),在其后,发现集群整体性能下降, 普通的测试也较之前很差的结果,是因为数据量大memtable的不停的切到固定,不停的触发合并compact所致吗?  这是普通测试的结果  这种情况下对线上可能有隐患,如何防止呢?还是我的使用有误  ---------------------------------------------------- 感谢大佬解答
现在有这么几个需求: 1. 知道集群存了多少个key和总大小 2. 在1的基础上统计以固定prefix开头的key的数量和总大小 3. 这些key的根据大小进行区间统计,比如4KB的多少等等 请问官方对这种场景有什么好的建议或最佳实践吗?
Tendis集群3主3从,每slave节点运行一段时间会都进行dump操作 dump之前slave节点的数据量比master节点数据大一倍,dump之后slave节点db数据大小恢复正常, 手动删除slave的dump目录后新建dump目录,会导致下次dump的时候KVStore::createBinlogFile失败【见后面错误日志】。 建议生成binlog的时候判断下dump/{storeId}父目录是否存在,不存在创建下。 请问slave什么情况下会进行dump操作?如何关闭dump或者设置dump目录清理时间? # 节点信息 redis_version:2.3.4-rocksdb-v5.13.4 redis_git_sha1:552a4365 redis_git_dirty:23 redis_build_id:4869811118804139172 redis_mode:cluster TENDIS_DEBUG:OFF os:Linux 4.4.226-1.el7.elrepo.x86_64 x86_64 arch_bits:64 multiplexing_api:asio gcc_version:5:5:0 process_id:15779 tcp_port:51002 uptime_in_seconds:84462 uptime_in_days:0 config_file:/data3/tendisplus02/scripts/tendisplus.conf # 错误日志 E0722 15:54:55.841712 16220 kvstore.cpp:573]...
在数据量比较大的情况下重启会不会很慢? 假如会比较慢,会有日志打印出来,告诉节点在干什么吗? PS:这点很重要,否则启动的人,不知道他到底是出问题了,还是正在进行某些工作。