SugarTeam
SugarTeam
# 前言 在日常的开发中,从服务器端异步获取数据并渲染是相当高频的操作。在以往使用React Class组件的时候,这种操作我们已经很熟悉了,即在Class组件的componentDidMount中通过ajax来获取数据并setState,触发组件更新。 随着Hook的到来,我们可以在一些场景中使用Hook的写法来替代Class的写法。但是Hook中没有setState、componentDidMount等函数,又如何做到从服务器端异步获取数据并渲染呢?本文将会介绍如何使用React的新特性Hook来编写组件并获取数据渲染。 # 数据渲染 先来看一个数据渲染的简单demo ```js import React, { useState } from 'react'; function App() { const [data, setData] = useState({ products: [{ productId: '123', productName: 'macbook'...

# 协同编辑场景的基础分析及方案设计 # **背景** 最近笔者在做一款具有协同编辑功能的思维导图时。在实现协同编辑的过程中对这一场景中笔者有了一些自己的理解,于是便在这里抛砖引玉。 # **协同编辑是什么:** 协同编辑,即多个操作端同时对一个对象进行操作。在协同编辑的过程中,有俩个首要的性能指标,一致性与实时性。二者相互制约,不同的场景有不同方案。 协同编辑中最容易出现的问题就是**由于多个操作端状态不一致导致的操作冲突**。 所以,如何解决具体某个具体模式协同编辑中的冲突,首先的就是了解该事物的**状态与操作**。 # **“状态”与“操作”:** 状态,即事物表现出来的状况与形态。操作,这里我把操作定义为改变状态的动作。 在一次操作改变状态的过程中,有以下四个要素: **1、原始状态** **2、触发操作的条件** **3、操作** **4、新的状态** 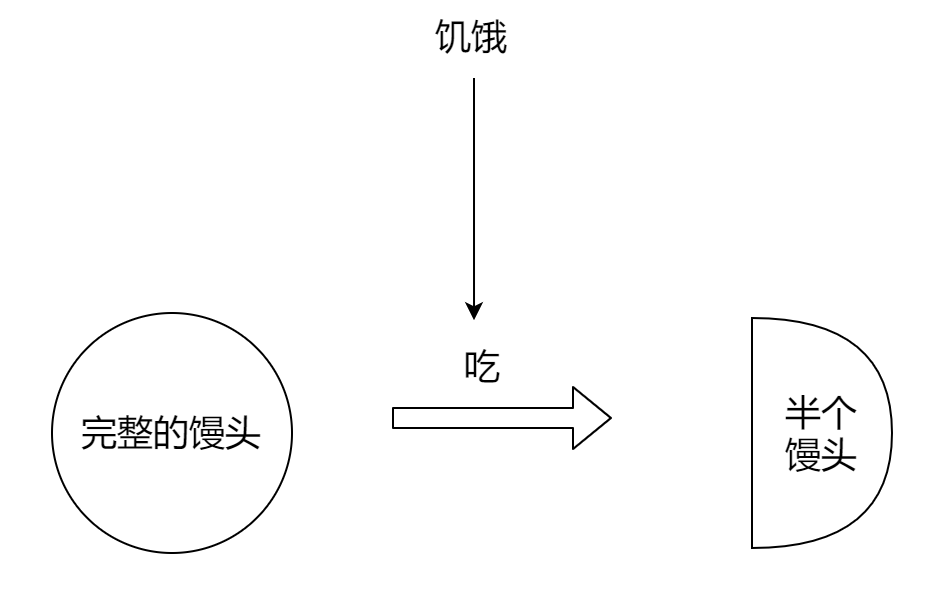 以上述过程为例,完整即为馒头的初始状态,触发操作的条件为饥饿,吃为该操作的具体动作,而半个则是馒头在经历这次操作后的后续状态。 所以为了确保协同编辑的一致性,我们就要 **确保每一次事件发生在不同端时,四要素一致**。 # **设计目标** 不同的业务场景下,我们往往对一项技术的性能要求也不同。 在思维导图协同编辑的过程中,我们 **重一致性,轻实时性**。 # **设计方案** 在明确重一致,轻实时这一目标后。我们就对目标进行解构。...
# 背景 团队的项目 A 经历两年需求的洗礼,一些问题也随之暴露出来: - 项目引用的`npm`包很多,业务代码也很多,有着向巨石应用发展的趋势。巨石应用的一些典型问题如下:**构建效率低下**、**dev-server 占用内存大甚至内存泄露**、**维护成本急剧增加**。 - 项目主框架升级成本高,要**兼容旧代码**。 - 项目里的某些业务几乎不再迭代,但每个版本依然会被打包构建,每次构建的`npm`包版本可能不同,导致一些**隐藏未知错误**。 - 该项目之前是由两个不同的项目合并而来,代码风格上存在两种方式,解决类似问题时引入的技术方案也是不一样,导致后期**维护成本高**,同样对于新人来说**阅读性差**。 # 解决之路 ## 为什么用微前端 对于微前端跟 iframe 的方案区别,为什么用微前端这个问题,这里不再累赘,`qiankun`里面有一篇文章已经说得非常不错,有兴趣可以去看看。 [why not iframe](https://www.yuque.com/kuitos/gky7yw/gesexv) ## 为什么我们选择`qiankun` - `qiankun`的接入对项目改动小,成本低。 - 社区活跃,作者对于...
## 千里之堤,溃于蚁穴。 在Web系统中,一个小小的漏洞,往往能引发极其严重的后果。因此,Web安全是每个系统在设计、开发、运维时必须要重点考虑的问题。 现如今很多Web系统所采取的防御措施是偏向于基础和简单的,往往只针对常见的安全漏洞做了防御,比如: * Csrf * XSS * Sql注入 等等。这些基础的防御措施是必须要做的,且实施的成本不高,但它们只是系统安全防御中的基础部分。很多开发人员在意识中认为做好这些就足够应付大部分情况了,这种想法是非常危险的。实际上,除了这些基础且标准化的漏洞,每个业务系统本身的业务逻辑也很有可能成为黑客攻击的目标,一旦被抓到并攻破,那后果将是非常严重的。下面将列举一些常见的业务逻辑漏洞,这些漏洞也是之前开发系统时踩过的坑,希望能对大家有所启发。 ## 会话凭证管理混乱 我们都知道HTTP本身是无状态的,为了能让浏览器和服务器互相知道身份并信任对方,大部分web系统都是利用“token”这种约定的凭证来实现的,token会在用户登录之后产生,并在用户主动退出或者超过一段时间后失效。也就是说,请求带上了相应的token,那么服务端就能拿到token做相应的校验,校验通过则信任该请求并执行相关业务逻辑,如果没带、带一个非法的或者过期的则认为不合法。这看上去并没有什么问,但实际的实现上可能暗藏漏洞。 来看两个例子: 1.前端开发人员小明在写用户点击退出按钮的逻辑时,只是单纯的清空了cookie或者localstorage中的token值(token一般存这两个地方),并没有向后台发起请求让token在业务中过期失效。那这个token的有效性本质上违背了用户的意图,此时就存在非常大的风险。当用户自发退出后,token仍然有效,假如该token被他人通过某种方式获取并记录下来,那他可以完美的回放用户执行过的操作,比如更改用户信息,下单等。 2.在上面的例子中,我们有提到token是要设置过期的,合理的过期时间能有效降低风险。但后台开发小哥也许在设置token过期的配置中,眼花加手抖,多打一位数,或者把单位理解错,在S级单位上用了MS级的数值,那过期时间就会被设定的很长。对于登录之后就不喜欢主动退出或者长期挂着页面的用户就非常的危险。token在用户长期不使用的情况下依然有效,如果被他人拿到token,也能干很多的坏事。 ## 校验失效 文件上传应该是Web应用上比较常用的功能,比如上传头像,上传文件到网盘等等。恶意用户可能会在上传的时候,上传木马、病毒、恶意脚本等文件,这类文件在服务器上被执行会带来比较严重的后果。这种攻击方式成本较低,比较容易被攻击者利用。允许上传的文件类型越多,受攻击的可能性就越大。当恶意程序被成功上传后,可能被用户下载,在用户电脑上执行后使之中毒。也可能在服务器上就执行恶意程序,造成服务器被控制,进而服务器瘫痪,数据丢失。 正常情况下,程序都会对文件类型进行判断,只允许我们认为合法的文件上传到服务器。但是,这个判断在一些web程序中,只在前端做了,在后端没做。这就给攻击者带来了机会,攻击者可以轻松的串改请求,从而实现非法文件的上传。 正确的做法应该是后端进行文件扩展名判断、MIME检测以及限制上传文件大小等限制来防御。另外,可以将文件保存在一个与业务隔离的服务器来防止恶意文件攻击业务服务器导致服务不可用。 ## 数据枚举 在登录系统,大部分系统会在用户登录的时候判断用户是否存在,然后给出提示“该手机号未注册”。如果这个逻辑是用一个单独的接口做的,那么就会存在被暴力枚举的风险。攻击者可以通过该接口利用手机号码库进行请求枚举,识别出哪些手机号是在系统中注册过的,给下一步暴力破解密码带来机会。 对于这个问题,建议是将该判断放到登录验证的接口中,并不返回明确的提示。你会看到做的好的网站上,一般会提示“该手机号未注册或密码错误”。虽然这在用户体验上打了折扣,但也更加的安全。 ## 数据写入重放 以一个论坛的发帖举例,利用抓包工具抓取论坛发帖的请求过程,并通过该工具重放过程,会发现帖子列表出现了两条一样的帖子,这就是被重放攻击了。如果加快重放频率,不仅会在系统中产生很多的垃圾数据,还会因为频繁写入给业务数据库带来巨大压力。 对于此类有重放风险的请求,建议加上请求频率限制。比如,可以判断两个请求的时间戳,设定大于某个时间值才有效。...
# 什么是混沌 混沌即混沌工程,首先我们得知道混沌工程是什么。 混沌工程起源于Netflix公司,Netflix公司的工程师创建了一种验证服务可靠性的测试工具Chaos Monkey。使用这个工具,可以在我们的web系统中随机的制造一些麻烦,比如触发网络异常,流量激增,容器退出等异常,我们可以在这些异常发生时,观察我们的系统是否依旧按照我们预期的方式运行。假设在流量激增突破承载能力的场景下,我们的系统是否会触发熔断机制来保障功能稳定运行。该工具最大的作用是,让故障在造成重大损失之前暴露出来,给工程师提供足够的时间和机会来修复问题。随着时间的发展,混动工具演变成了一套方法论,用来指导工程师如何让系统提前暴露问题,及时修复问题。 目前国内很多大厂都有相关的混沌工程实践,不过多数都在后端领域实践,在前端中实践混沌工程的相对较少。那在前端中,如何将混沌的方法论和思想落地呢?  # 混沌组件 近期在逛github的时候,找到了一个让react组件混沌起来的开源库 [react-chaos](https://github.com/jchiatt/react-chaos)。这个组件的功能非常简单,它提供了一个高阶组件,该高阶组件的功能是通过一个随机数,让组件随机的Throw Exception出来。如果你的组件没有处理异常的代码,那组件在页面就不会渲染出来的,并且在控制台中会显示出相应的错误信息。出错时的效果如下图所示:  我们来看看他的源码 ```javascript const withChaos = ( WrappedComponent: React.ElementType, level: Level, errorMessage?: string, runInProduction?: boolean ): WithChaosReturn =>...
## 前言 最近发现项目里面会出现一些重复的请求,在某些页面中,相同参数相同地址的请求会在1s之内连续发送多次。为了解决这个问题,最终做出了两个工具([repeat-request-minder](https://github.com/SugarTurboS/repeat-request-minder)和[repeat-request-minder-webpack-plugin](https://github.com/SugarTurboS/repeat-request-minder-webpack-plugin))来辅助我们避免重复的请求。 ## 背景 随着项目越来越复杂,写代码的时候难免会没留意到有些请求在别的组件已经发送过,特别是用了 hooks 之后,有一些 hook 在 useEffect 中封装了请求的逻辑,而hook被多个组件引用导致重复请求。另外也有可能是按钮的点击没有防抖造成重复发送请求。 通常面对这些状况,我们都只能是在控制台上人为的检查,比较难发现并处理。 ## 重复请求的危害 这些重复的请求主要有两个影响 - 增加服务器的压力 - 可能由于其中的某个请求失败导致页面显示错误 ## 解决思路 ### 前置处理 一般开发的时候可能不会留意到有重复的请求,要避免这种情况需要自动监控并给出警告,才能从源头杜绝重复请求的发生。 ### 后置处理 出现了重复请求之后能够自动取最后的请求,不发出之前的请求。 ### 结论...
## 概述 先聊一聊业务背景,随着系统服务的不断开发,我们的系统会充斥着各种个样的业务.这种时候,我们应该要开始考虑一下如何将系统的粒度细化.举个常见的例子: 电商系统可以拆分为 商品模块,订单模块,地址模块等等.这些模块都可以独立抽取出来,形成一个单独的服务.这就会涉及到各个模块之间的通信问题,一些简单的服务,我们可以通过 `rpc` 接口 直接进行通信,但是有些服务却不适用这种模式.本文主要讲一下在`多数据源`路上遇到的一些坑. #### 多数据源  #### 项目结构 源码地址: https://github.com/jaycekon/SpringBoot/tree/master/spring-boot-mybatis-multi  配置文件: `DataSourceConfig` ``` java @Bean(name = "masterDataSource") @Qualifier("masterDataSource") @ConfigurationProperties(prefix = "spring.datasource") public DataSource masterDataSource()...
# 概述: 最近在开发中遇到了一个刚好可以用AOP实现的例子,就顺便研究了AOP的实现原理,把学习到的东西进行一个总结。文章中用到的编程语言为kotlin,需要的可以在IDEA中直接转为java。 这篇文章将会按照如下目录展开: - AOP简介 - 代码中实现举例 - AOP实现原理 - 部分源码解析 # 1. AOP简介 相信大家或多或少的了解过AOP,都知道它是面向切面编程,在网上搜索可以找到很多的解释。这里我用一句话来总结:AOP是能够让我们在不影响原有功能的前提下,为软件**横向扩展**功能。 那么横向扩展怎么理解呢,我们在WEB项目开发中,通常都遵守三层原则,包括控制层(Controller)->业务层(Service)->数据层(dao),那么从这个结构下来的为纵向,它具体的某一层就是我们所说的横向。我们的AOP就是可以作用于这某一个横向模块当中的所有方法。 我们在来看一下AOP和OOP的区别:AOP是OOP的补充,当我们需要为多个对象引入一个公共行为,比如日志,操作记录等,就需要在每个对象中引用公共行为,这样程序就产生了大量的重复代码,使用AOP可以完美解决这个问题。 接下来介绍一下提到AOP就必须要了解的知识点: - 切面:拦截器类,其中会定义切点以及通知 - 切点:具体拦截的某个业务点。 - 通知:切面当中的方法,声明通知方法在目标业务层的执行位置,通知类型如下: 1. 前置通知:@Before 在目标业务方法执行之前执行 2. 后置通知:@After...
## 背景 在[自定义Egg.js的请求级别日志](https://juejin.im/post/5bdcfd1f518825171b2d820d)这篇文章中,我们实现了自定义请求级别的日志模块。看上去功能是完整了,但好像还缺点什么。 大家在根据日志追查问题的过程中,很多时候看到了某条log信息想去找出处,但是实际上代码里面打相同类型的log地方可能不止一处,这时你就比较难去定位这行log到底是哪里打的。 举个最极端的例子 ```javascript //home.js class AppController extends app.Controller { async first() { this.ctx.swLog.info('in controller'); await this.ctx.render('first.html'); } async second(){ this.ctx.swLog.info('in controller') await this.ctx.render('second.html'); } } ``` 上面的例子虽然比较极端,但是我们在代码中难免会碰到类似的情况。两个route对于的controller中都打印了相同的log,你在查日志的时候,是无法区分log到底是first里面打的还是second里面打的。...
在之前的项目中遇上移动端微信h5页面上传用户录像的功能需求,在简单使用input type=file的时候发现,ios录像上传会做自动压缩,而安卓端会直接上传录制的原视频,在用户不主动设置降低分辨率的情况下导致录像体积巨大,上传缓慢,体验及其不好,便有了这次的优化之旅。  在当下浏览器的飞速发展,可以看到getUserMedia这个获取媒体功能权限的API已经有了很好的兼容性,那么我们便从浏览器端主动调用摄像头功能入手。实时音视频通信的未来是WebRTC的天下,在安卓微信浏览器(X5内核)上兼容性很好,直接使用开源的RecordRTC JS封装,交互体验好,未来可以支持实时活体审核。 在这里先给大家安利一个控件recordrtc:https://github.com/muaz-khan/RecordRTC 目前这个组件集成了录像录音录屏多种功能,本文暂以录像的应用为例,欢迎大家试验和探讨研究。 首先,调用浏览器获取流媒体权限必不可少 ``` const mediaConstraints = { audio: true, video: true } navigator.mediaDevices.getUserMedia(mediaConstraints) .then(this.successCallback) .catch(this.errorCallback) ``` 紧接着 succuess回调(successCallback(stream))中进行video标签与摄像头的相关绑定,同时初始化recordrtc,相关常见配置大家可以去查看下文档噢(这里碰上个小坑,一开始直接使用 new RecordRTC(stream),结果发现微信里面录的视频有相当的卡顿感,改用了MediaStreamRecorder,神秘优化点...) ``` let recordingPlayer =...