PaddleHub
 PaddleHub copied to clipboard
PaddleHub copied to clipboard
Awesome pre-trained models toolkit based on PaddlePaddle. (400+ models including Image, Text, Audio, Video and Cross-Modal with Easy Inference & Serving)
使用ge2e_fastspeech2_pwgan语音克隆模型,生成的音频总是叫1.wav,修改out_dir也是指定文件夹名称然后在下面生成1.wav,在哪里修改生成音频的名称?
图片生成古诗报错

您好,我使用命令行对图片进行生成古诗,报错如下,可以帮忙看看么?谢谢了 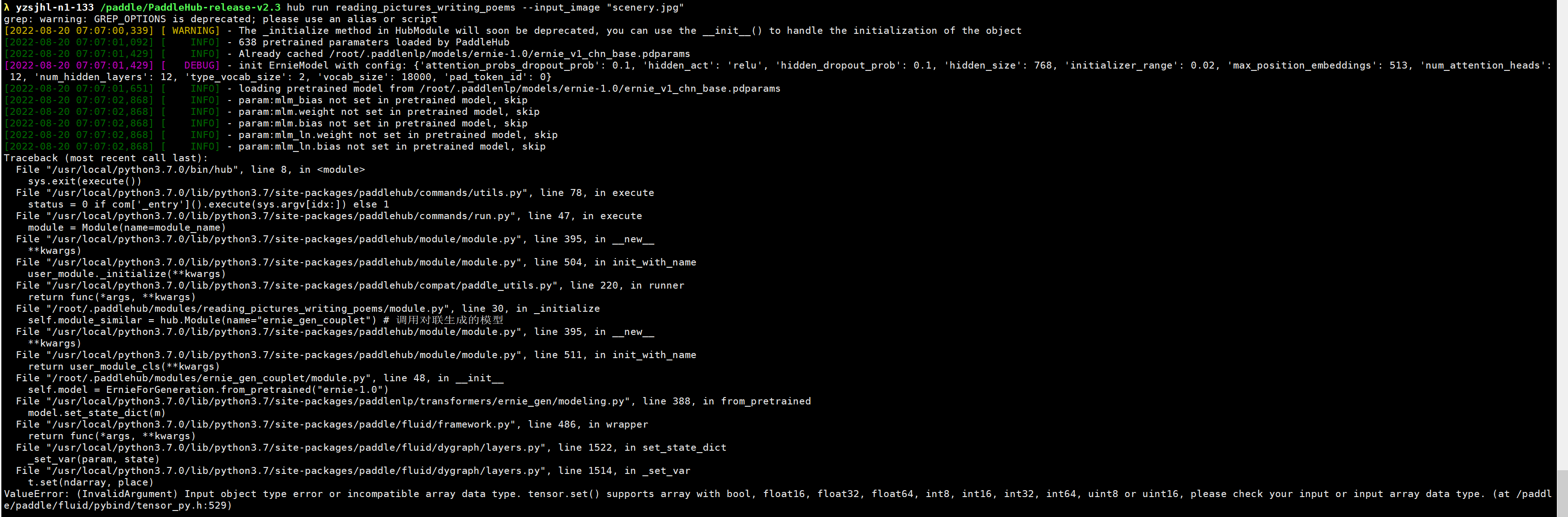
欢迎您对PaddleHub提出建议,非常感谢您对PaddleHub的贡献! 在留下您的建议时,辛苦您同步提供如下信息: - 您想要增加什么新特性? - 什么样的场景下需要该特性? - 没有该特性的条件下,PaddleHub目前是否能间接满足该需求? - 增加该特性,PaddleHub可能需要变化的部分。 - 如果可以的话,简要描述下您的解决方案
欢迎您对PaddleHub提出建议,非常感谢您对PaddleHub的贡献! 在留下您的建议时,辛苦您同步提供如下信息: - 您想要增加什么新特性? 通过hub调用文字识别接口时,希望增加一个参数,在每次请求后都释放显存。 - 什么样的场景下需要该特性? 关于 https://github.com/PaddlePaddle/PaddleHub/issues/937 提到的显存不释放问题,如果用不同的图片请求服务(即使都缩放成768*768),多次请求后显存就因为不释放而不足了。如果每次请求都能释放显存,应该能支持长期的大量的请求。 - 没有该特性的条件下,PaddleHub目前是否能间接满足该需求? 没有这个参数,就不会释放显存。 - 增加该特性,PaddleHub可能需要变化的部分。 需要在调用 chinese_ocr_db_crnn_server 的功能时增加一个参数。 - 如果可以的话,简要描述下您的解决方案 比如增加参数cacheVideoMemory参数,默认值为1,可以设置为0,这时不缓存。
环境:CentOS7, Python3.6.8, paddlepaddle==2.0.0rc0 第一次使用8核16G的云服务器,以cpu模式进行预测,一张大小为792x692,大小为215k的png图片预测时报内存不足,预测失败。  第二次把内存提升至32G后,同样对同一张图进行预测,内存占用超过50%;但是预测成功了。请问有什么办法降低内存占用? 预测方式是: 第一种:hub run chinese_ocr_db_crnn_server --input_path "/Images/Image1.png" 第二种:hub serving start -m chinese_ocr_db_crnn_server;然后执行:python3 ./tools/test_hubserving.py http://127.0.0.1:8866/predict/chinese_ocr_db_crnn_server /Images/Image1.png
Metadata
Owner
Metadata
Awesome pre-trained models toolkit based on PaddlePaddle. (400+ models including Image, Text, Audio, Video and Cross-Modal with Easy Inference & Serving)