Reinforcement-learning-with-tensorflow
 Reinforcement-learning-with-tensorflow copied to clipboard
Reinforcement-learning-with-tensorflow copied to clipboard
Simple Reinforcement learning tutorials, 莫烦Python 中文AI教学

Hello Dr. MorvanZhou, Thanks for sharing this great repository. May I ask you 2 simple (stupid, as I am a rookie of RL~lol) questions: 1. How can I save the...
``` def _discount_and_norm_rewards(self): # discount episode rewards discounted_ep_rs = np.zeros_like(self.ep_rs) running_add = 0 for t in reversed(range(0, len(self.ep_rs))): running_add = running_add * self.gamma + self.ep_rs[t] discounted_ep_rs[t] = running_add # normalize...
您好,我正在使用simply_PPO训练我的机器人做步态行走训练,其中,S_DIM是18,A_DIM 是12,请问需要对simply_PPO做哪些改变才能更好地适应我的训练?
I tried your DPPO algorithm with EP_MAX = 8000 and the total moving reward is not converging. Any Idea why ?
Hello, I have question . If I want combine actor and critic neural, how could calculate them loss? nerual like this: ``` with tf.variable_scope('AC'): w_initializer = tf.random_normal_initializer(0.0, 0.01) l1 =...
莫烦您好,请教您下面几个问题: 1. DPPO中关于PPO的伪代码 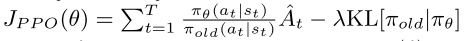 这一部分是计算从t=1到T新旧策略ratio的累加值。但是您代码中的实现是求得tf.reduce_mean,这应该是和这个目标函数相匹配:  我很困惑这两种目标函数到底哪个是正确的?或者说都正确,那么有什么区别? 2. 关于PG和PPO的目标函数。 这个问题和上个问题有点类似。下图是传统PG的目标函数:  这是对轨迹求期望,所以计算t=1到T的累加值。但是PPO的目标函数如下:  这个是对action-state pair来求期望,我不太理解怎么从对轨迹求期望变换到对action-state pair求期望。 3. 关于PG本身的目标函数好像都有这两种写法: 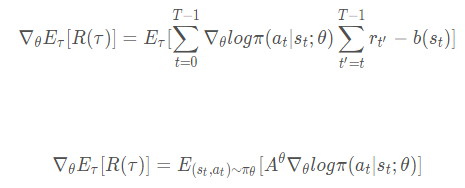 第一个绝对是对了,第二个我就不知道怎么理解了? 希望得到莫烦老师的帮助!
Hi @MorvanZhou , the BipedalWalker A3C example fail to converge after updating the TensorFlow. It would be great if we can fix it. https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/blob/master/experiments/Solve_BipedalWalker/A3C.py ``` W_3 Ep: 7983 | -------...
我下载了DQN的代码,发现运行报错,主要错误在两个地方上 1.choose_action(self, observation): observation = observation[np.newaxis, :]出现错误为TypeError: tuple indices must be integers or slices, not tuple 2.在修改了第一部分的错误之后(通过课程讨论区一位朋友提供的想法先observation=np.array(observation)然后再进行reshape,发现在transition部分又出现错误,提示输入的transition和self.memory列数不同,在进行observation的打印之后发现它的格式很奇怪,是(array([ 0.00107828, -0.02266533, -0.03175206, -0.04841794], dtype=float32), {}) 这样的一个形式,和observation_的形式也不同,我又回去check了maze的observation和observation_的形式发现maze的是相同,不知道该如何修改RL_brain的代码,希望大神们能给点建议
pandas==1.4.4 FutureWarning解决 ## 警告内容 ```python Reinforcement-learning-with-tensorflow\contents\2_Q_Learning_maze\RL_brain.py:45: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead. self.q_table = self.q_table.append( ``` ##...
Metadata
Owner
Metadata
Simple Reinforcement learning tutorials, 莫烦Python 中文AI教学