Reinforcement-learning-with-tensorflow
 Reinforcement-learning-with-tensorflow copied to clipboard
Reinforcement-learning-with-tensorflow copied to clipboard
Simple Reinforcement learning tutorials, 莫烦Python 中文AI教学
store_transition self.memory[index, :] = transition ValueError: could not broadcast input array from shape (26) into shape (32) print(self.memory.shape, transition.shape) 打印出来:(10000, 32) (26,) 哪位大侠能提供下解决这一问题的思路?
state的形式

Hi 博主, 我的state是一个列表,初始值为[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],选择action时出错:TypeError: tuple indices must be integers or slices, not tuple 我认为state已经是(1, size_of_observation)形式了,就注释掉了,observation = observation[np.newaxis,...
https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/blob/master/contents/5.2_Prioritized_Replay_DQN/RL_brain.py#L114 ``` min_prob = np.min(self.tree.tree[-self.tree.capacity:]) / self.tree.total_p # for later calculate ISweight ``` 由於Sumtree 在剛開始的時候存在大量 0 所以 np.min 會返回 0 而導致 ``` ISWeights[i, 0] = np.power(prob/min_prob, -self.beta) ``` 返回錯誤
对于奖励函数的设定是不是有什么要求啊?在A3C算法中使用的是状态值而不是动作值,那么奖励函数中的是不是要跟状态变量直接相关?而且还有个很迷奇的问题,为什么在相同权重的条件下,两次运行的结果差别很大?目前我的累积奖励值虽然有收敛趋势,但是波动还是很大! 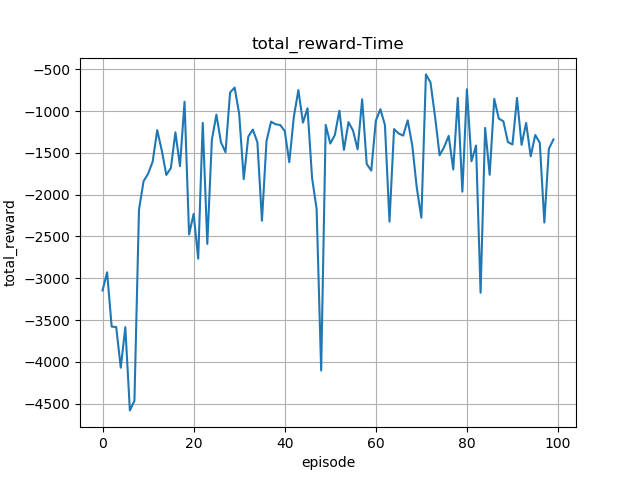
does your Deep Q Network (DQN) code work for 3d objects in unity or its only for 2d objects ?
在我研究的问题中,agent的动作包含两个维度,且两个维度的取值范围不一样,请问怎么解决这个问题呢,谢谢各位的回答先!
莫烦:您好 请问如果actor输出多维连续动作值,那么还能用函数tf.distributions.Normal构建多维概率密度吗?如果能,那么函数方法prob_log输出tensor的维度与样本维度一致,即不能与标量retrun相乘。请问该如何解决这个问题? 谢谢
`with tf.variable_scope('sample_action'): self.sample_op = tf.squeeze(pi.sample(1), axis=0) # choosing action` 代码中与环境交互使用的是new_pi, 但是根据surrogate loss 公式的话,  不应该都用old pi 交互吗
Metadata
Owner
Metadata
Simple Reinforcement learning tutorials, 莫烦Python 中文AI教学