MeJerry215
MeJerry215
补充说明,这个模型后续在连续两次overwrite-input-shape之后确定了两个输入的shape, 但是onnxsim 需要继续执行多次才能无法继续优化下去。 目前看 目前gpt2 模型當前onnxsim 兩次overwrite-input-shape + 6次的正常sim 最終onnx模型图才没有变化。  @daquexian
@AniZpZ smooth quant only get high accuracy with activation **per-token dynamic** quantization, weight per-channel quantization. 
@AniZpZ the root cause is activation is still too large. you can dump the down proj's input tensor. if you disable llama model down proj quantization, accuracy will get improved...
> I have conducted more experiments that achieve the same results as in the paper. > > There is only one problem: per-channel weight quantization is not compatible with the...
so where is the inference code? Its about two months.
当我导出en2fr的时候 推理在加载h5py的时候出错异常,如果我注释掉layernorm 参数
嗨哥们, 我不知道为啥他给的这个weight 用起来的时候要减1,从这个导出的脚本来看, 他这个emb的size 会大一点 在我修改他那个地方的逻辑之后,不知道为什么还是有个地方报错。。  下面这个。所以他的这个Bert 自己的weight,导出来的pb 还不能跑。。。我很迷茫 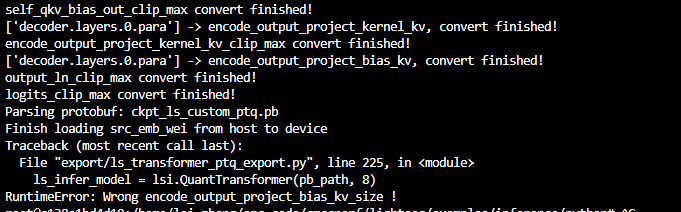
Can u use smooth quant to quant llama without accuracy drop? I try to quant the llama-7b, but accuracy also drops a lot. @fmo-mt 
@Guangxuan-Xiao
> > Can u use smooth quant to quant llama without accuracy drop? I try to quant the llama-7b, but accuracy also drops a lot. @fmo-mt > >  >...