MaybeShewill-CV
MaybeShewill-CV

# 平台(如果交叉编译请再附上交叉编译目标平台): # Platform(Include target platform as well if cross-compiling): Ubuntu 16.04 GCC-8.2 CUDA-10.2 MNN-Version: MNN-2.0.0 release # 编译方式: # Compiling Method -DCMAKE_BUILD_TYPE=Release -DMNN_CUDA=ON Model's output was wrong with MNN-2.0.0...
Could you please release more information about the training details such as batch_size, learning rate , epoch nums if it matters nothing? Thanks a lot
首先感谢大佬 @ycszen 的工作:) 文章中有些我觉得写的不是很清楚的地方想问一下,关于generalization to large models章节中提到的两个参数α和d。 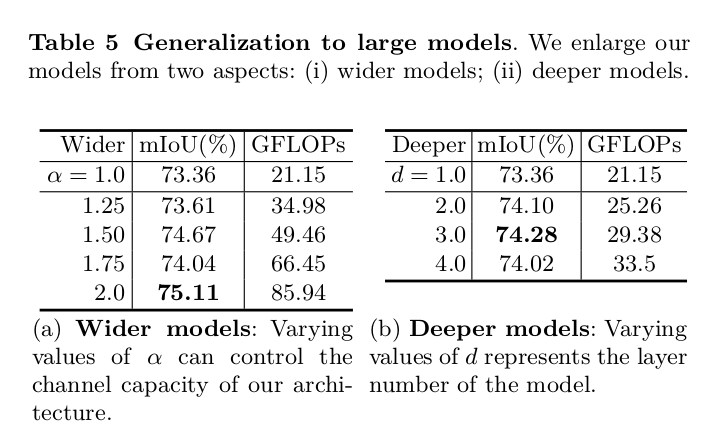 关于α,我觉得指的是进入segmentation heads模块之前的channel expansion倍数,如下图所示 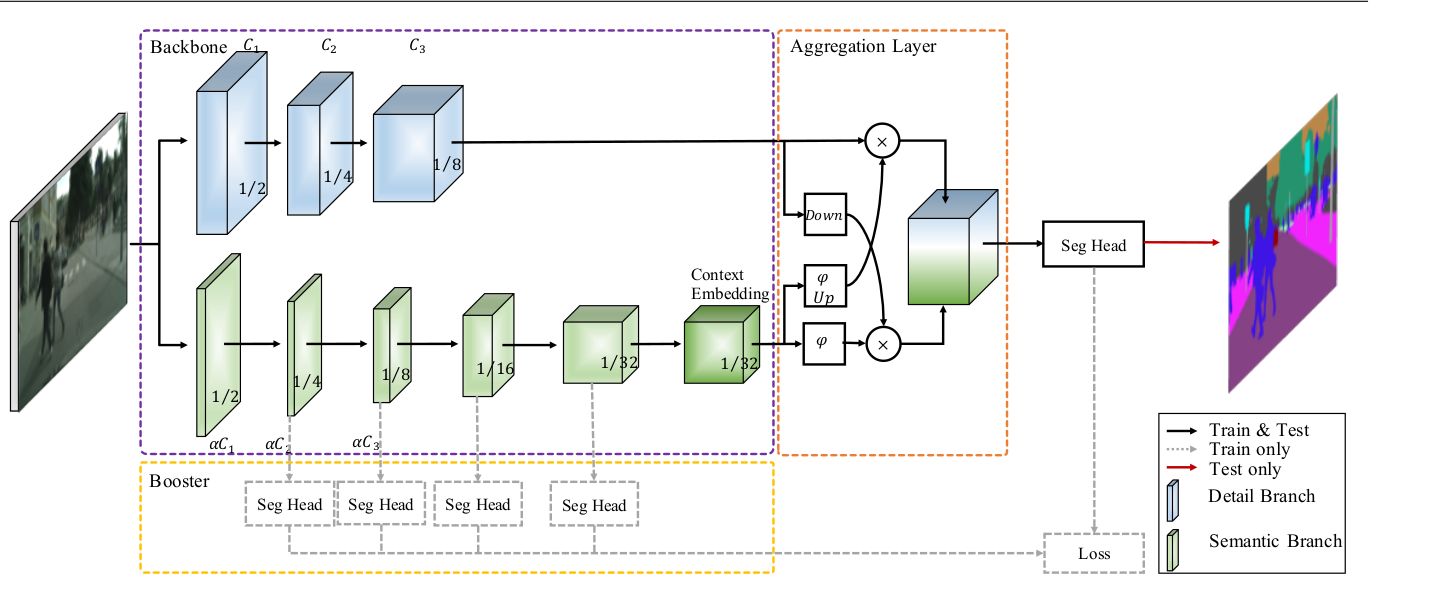 那么这个d参数指的是什么呢,文章中说d参数控制的是模型的深度,那么这个d是指代上文中的什么参数呢,是module repeat的次数吗. 还有点疑惑就是table5下方的描述α控制模型的channel capacity而d控制layer nums.然后下文中说α是width multiplier,d是depth multiplier。请问这个地方上下文的表述是否一致。  这两个参数该如何理解更为准确呢。还请大佬有时间不吝赐教...
Hi I'm very interested in your great work. I wonder whether the training dataset be released in the future?:)
I wonder if the excellent model is able to converted into onnx ?
Does the method have detailed results on metric measurements, especially in comparison with the metric3d method?
Could you please tell me the ipm function need external camera parameters?
Wonder if mobile-sam can reach the inference performance mentioned in origin paper using mnn backend. As mentioned in origin paper encoding part cost 8ms, decoding cost 4ms. I've tested it...