JavieYuan
JavieYuan
> 这部分代码在这个类里: > > https://github.com/PaddlePaddle/PaddleOCR/blob/7f6c9a7b99ea66077950238186137ec54f2b8cfd/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml#L94 > > https://github.com/PaddlePaddle/PaddleOCR/blob/7f6c9a7b99ea66077950238186137ec54f2b8cfd/ppocr/data/imaug/rec_img_aug.py#L499 ![Uploading ques2.png…]() 三个月前拉取的代码,我这边的rec_img_aug.py如图所示,代码对应行都不一致了应该是旧版本,官方应该是更新了。我这边仅仅替换掉这一个rec_img_aug.py文件重新使用自己的数据训练应该较之前影响不大吧?还是说也有其他关联更新需要同时做修改?
> 请提供下述完整信息以便快速定位问题/Please provide the following information to quickly locate the problem > > * 系统环境/System Environment: > * 版本号/Version:Paddle: PaddleOCR: 问题相关组件/Related components: > * 运行指令/Command Code: > * 完整报错/Complete Error...
> > > 请提供下述完整信息以便快速定位问题/Please provide the following information to quickly locate the problem > > > > > > * 系统环境/System Environment: > > > * 版本号/Version:Paddle: PaddleOCR: 问题相关组件/Related components:...

使用真实的扫描笔拼接数据进行eval以及infer发现准确率为0,真实数据如下:  
真实数据的识别结果类似如下所示,其中中文以及英文识别结果都很离谱: ./testdata/tr/000000017.bmp 蚕 ./testdata/tr/000000018.bmp 疆晶曹 请问是什么原因呢?????
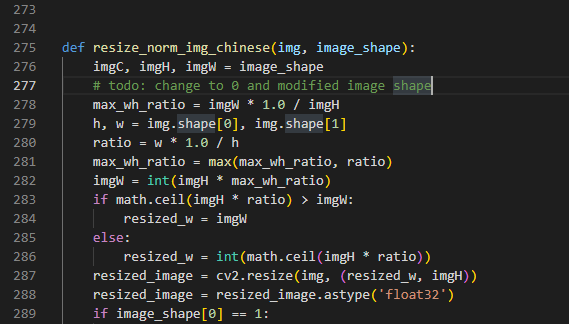
 请问关于输入图像32*320这部分,说把图像等比例缩放至3,32,320以及不足320部分补0,关于这部分的源码在哪里呀,好像不在数据增强rec_img_aug里面???
> 1)推理的时候,字典更换了吗 2)可以用paddleOCRv3预训练模型直接预测看下效果 3)测试生成数据效果怎么样呢 4)生成的数据和真实数据还是有一些偏差,可以在生成数据集上再改造下 在训练的时候是没有用预训练模型的,是直接训练的,如果加载预训练模型开始训练的话泛化性会变强吗?还是说最终泛化性拟合效果仅仅趋向于自己人工合成的训练数据?训练数据是只有自己人工合成的
 