Hideaki Imamura
![]()
![]()
![]()
Hideaki Imamura

Thanks for a great project. I'm using the benchmarking function in `bayesmark/sklearn_func.py`. This file defines several benchmark functions using `sklearn`. A "space" is defined for each function's hyperparameters. How is...
Related to #3701, #3730, #3700, #3731, #3784, and #3798. ## Motivation Currently, the tests of plot_contour for the plotly backend and matplotlib backend have a lot of overlap. This PR...
### Expected behavior The `optuna.samplers._tpe.sampler._solve_hssp` should consider `+/-inf`. As shown in [here](https://github.com/optuna/optuna/pull/3662/files#r895502801), currently it does not take into account +/- inf, so it behaves unnaturally. Ideally, one would expect the...
### Expected behavior Should be resolved after #3674. The `optuna.samplers._tpe.sampler._calculate_weights_below_for_multi_objective` should consider `+/-inf`. Currently, the `nan`'s list is returned when the trials include `+/-inf` as objective values, but it should...
### Motivation Currently, `bayesmark` benchmark is available to use some scikit-learn benchmark problems. But, it has a different backend `bayesmark` with that of other benchamrks `kurobako. We have following drawbacks....
### Expected behavior It should be possible to take a benchmark on the WFG1 test problem, but the current generated plot looks empty. You need to fix https://github.com/optuna/optuna/tree/master/benchmarks/kurobako/problems/wfg. 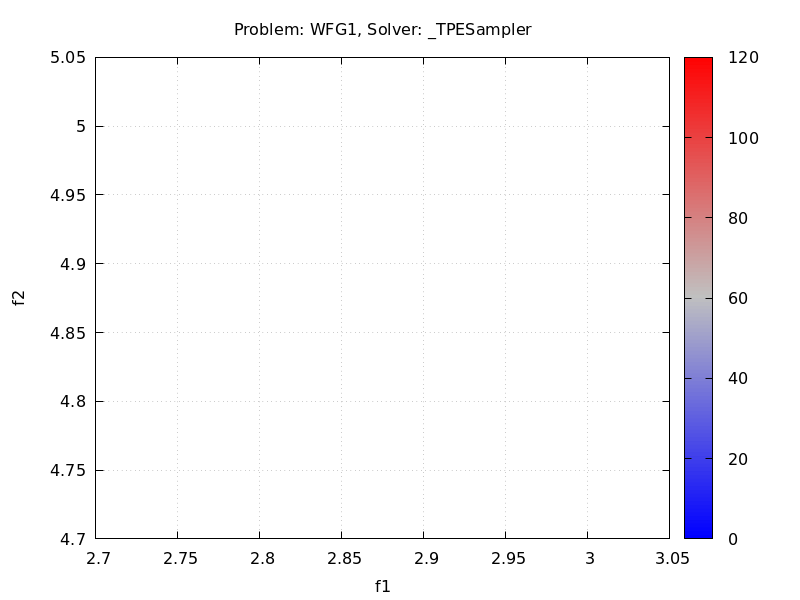 ###...
### Motivation Recently, we have introduced the multi-objective benchmark suite in Optuna. The current performance metric is only the pareto font plot. It is difficult to judge the performance from...
### Expected behavior Based on #3716. The current `report.md` generated by `kurobako` in the multi-objective optimization is unnatural. See below. The column of Best and AUC are NaN. If we...
### Expected behavior Recently, the benchmark for multi-objective optimization have been introduced. We can run different settings in the one workflow. Each setting can have several studies. Each setting generates...
### Motivation Since this issue is an RFC, any opinions/comments are welcome. Now, we cannot edit the information of trials, such as `params`, `values`, `intermediate_values`, or `user_attrs`, after they are...