Guangchuang Yu
Guangchuang Yu

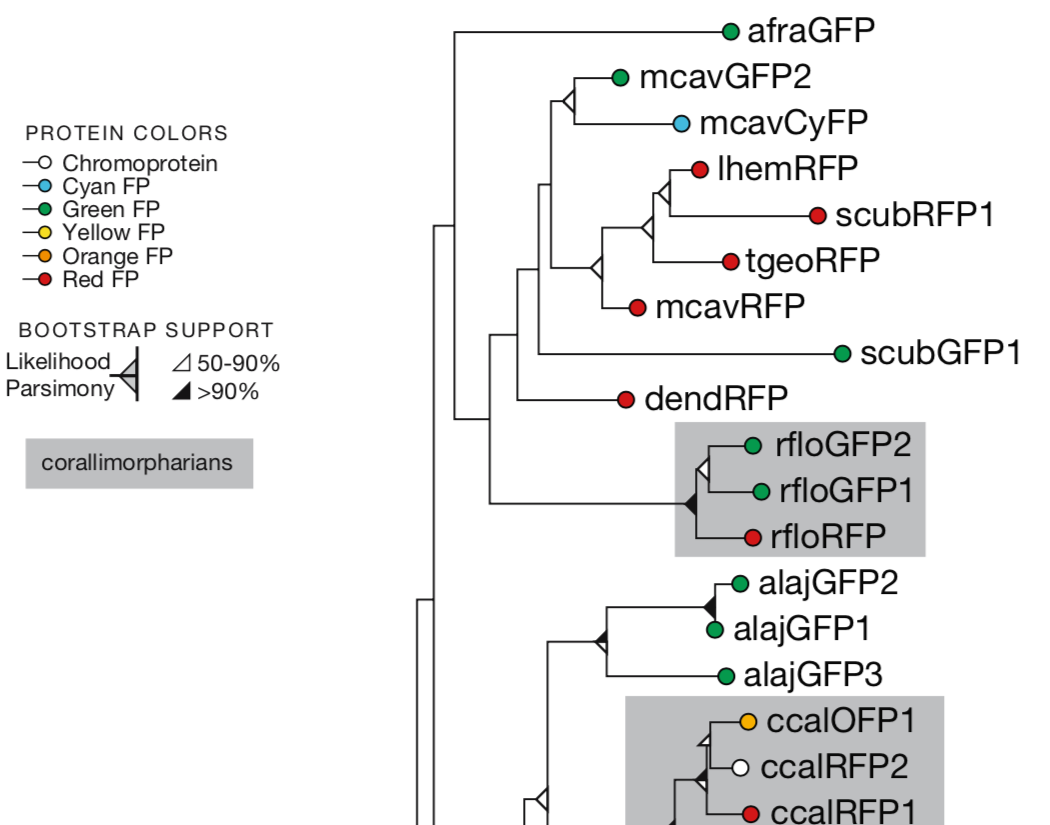  There are different methods to calculate support values and we may want to display all these pieces of information simultaneously. @xiangpin I think your package can help in...
hosting images for posting in forum.
this PR solve the issue on , making it possible to capture complex UpSet plot like: ```r upset(movies,attribute.plots=list(gridrows=60,plots=list(list(plot=scatter_plot, x="ReleaseDate", y="AvgRating"), list(plot=scatter_plot, x="ReleaseDate", y="Watches"),list(plot=scatter_plot, x="Watches", y="AvgRating"), list(plot=histogram, x="ReleaseDate")), ncols = 2))...
```r library(ggpomological) basic_iris_plot
enricher和GSEA可以搞一下。 `gson_GO`函数已经有了,,GO的分析就可以衔接。 这里`gson_GO`我不支持`ALL`,因为三个ONTOLOGY是独立的。我后面想要通过GSONList对象来支持。 然后输出对象可以是enrichResultList(默认)或者是enrichResult(简化版本,result data frame里多一个gsname的column)这样子两种的。这样子是通用的。可以比如KEGG、GO、wikiPathway一次过地跑富集。
1. Pathway Commons: GMT file can be downloaded from
基于@778055611 这个PR, 实际上在`parse_gff`中补全了GO间接注释,这个功能我们有个函数`buildGOmap`是同样的功能。 1. 把pase_gff里相应的补全间接注释的功能分离出来 2. 和buildGOmap比较,在结果一致的情况下,看那个版本的速度快,在`buildGOmap`的用较快的版本。 3. `parse_gff`调用`buildGOmap` @778055611 你来完成这个,优先级不高,有空时搞搞就行,当前以翻译为主要任务。
+ For GO, we can access such information from `meta(OrgDb)`. + For KEGG, , we can use (hsa as an example) to get the current release version.
see . We should change to using ensemble ID as default when passing an EnsDb to the TxDb parameter.