FATE
 FATE copied to clipboard
FATE copied to clipboard
An Industrial Grade Federated Learning Framework

我们测试了fate在1.92和1.11版本下的求交算法的运行时间 (本来准备测raw的,但是后面发现不支持raw,会默认改成ecdh算法) 但是测试结果显示fate1.11求交的时间是1.92的接近三倍,想请问下这是由于什么原因所导致的呢? 这是我们的作业配置 ``` # host端 docker exec -it confs-9999_client_1 bash cat > /tmp/upload.json
fate 已训练部署好的模型, 如何在脱离 fate-serving 的环境下进行API调用 (预测) ? 比如, 有没办法用python简单加载fate的模型来调用? (由于业务上的限制, 我这无法部署fate-serving.)
FATE版本是1.10,通过ansible三方部署 FATE-serving版本是2.1.5 我在guest端绑定模型成功后,可以在guest端的FATE-serving上面看到绑定的模型和serviceID,在host端的FATE-serving上面能看到绑定的模型,但是看不到绑定模型的serviceID,导致我在guest端发起在线预测时host端返回的是"host return code 104 host msg :mode is null",请问这个问题应该怎么解决? 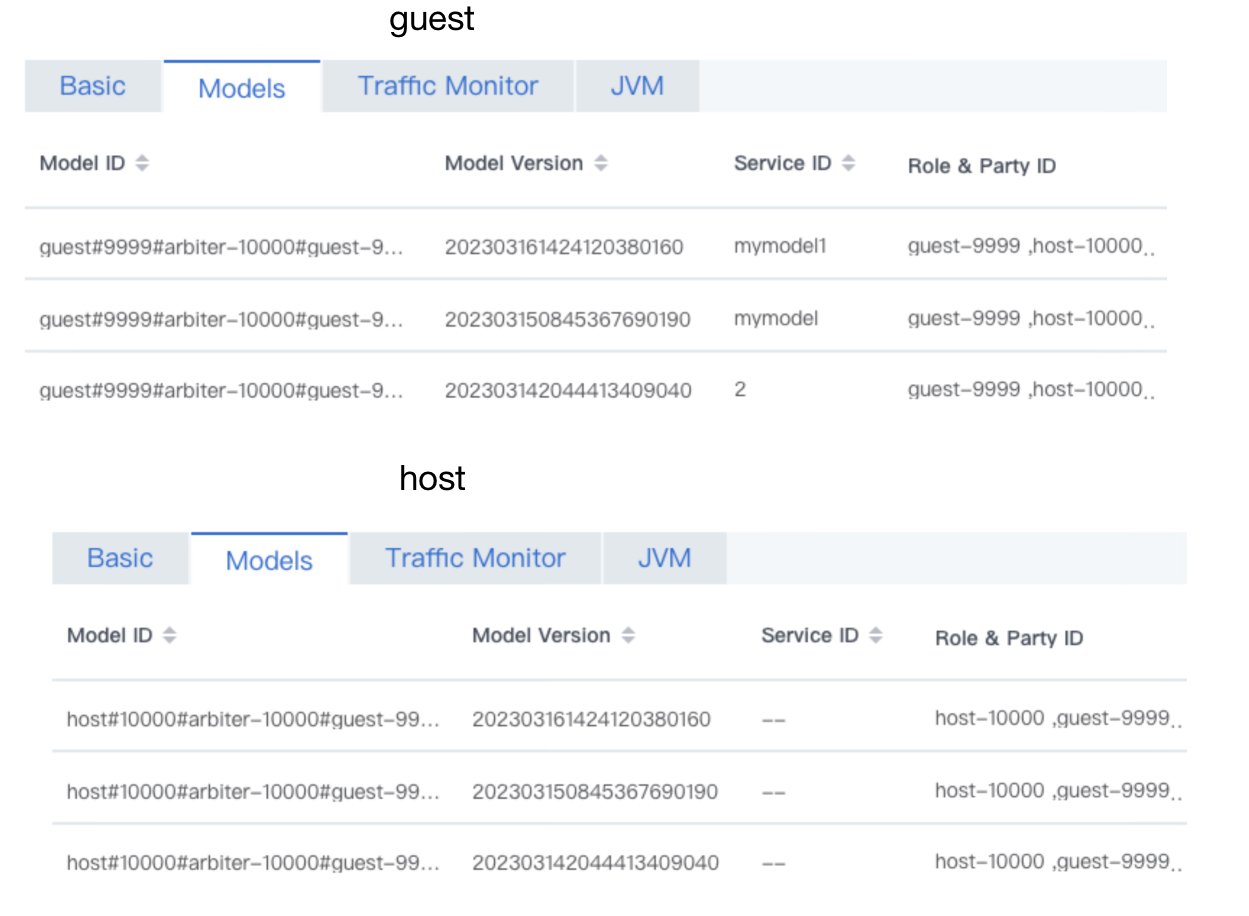
**Is your feature request related to a problem? Please describe.** 数据上传任务慢,有没有相关的配置参数 比如partition或者task_core等参数修改
您好,我在尝试tutorials中都能遇到以下问题,请问有什么解决办法吗,谢谢指导. 版本是Fatellm2.1 [INFO] [2024-05-02 03:36:43,059] [202405020336083952670] [52:140389839259392] - [base_saver.execute_update] [line:223]: UPDATE "t_task" SET "f_update_time" = 1714621003059, "f_error_report" = 'Traceback (most recent call last): File "/data/projects/fate/fate/python/fate/components/entrypoint/cli/component/execute_cli.py", line 147, in execute_component_from_config component.execute(ctx,...
 binning_0: inputs: data: train_data: task_output_artifact: output_artifact_key: output_data producer_task: psi_0 parties: - role: guest party_id: - '9999' - role: host party_id: - '10001' - '10000' model: {} component_ref: hetero_feature_binning dependent_tasks:...
fate环境:docker集群版(两方)fate2.0.0/fate2.1.0 (2.0和2.1都部署调试过) 作业发起:使用postman请求http://xxx.xxx.xxx.xxx:9380/v2/job/submit,将[train_lr.yaml](https://github.com/FederatedAI/FATE-Flow/blob/689345f1be753610851e63b6cd75ea6fa92e6b82/examples/lr/train_lr.yaml)转化成json格式作为body,创建一个作业。  现象:2.0.0和2.1.0都是同一个现象,运行到lr_0就卡住了,查看日志发现,LR总共迭代10次,但是迭代到第9次就不往下执行了,程序也不报错,整个作业状态还是running  
Metadata
Owner
Metadata
An Industrial Grade Federated Learning Framework