stable-baselines3
 stable-baselines3 copied to clipboard
stable-baselines3 copied to clipboard
DQN does not learn after long training and performs the same as random moves
I have created a gym wrapper around a snake game I made. I am using stable baseline 3 to train a snake to play the game. I have verified that the gym environment is functional and supports the correct interface for sb3 (using from stable_baselines3.common.env_checker import check_env).
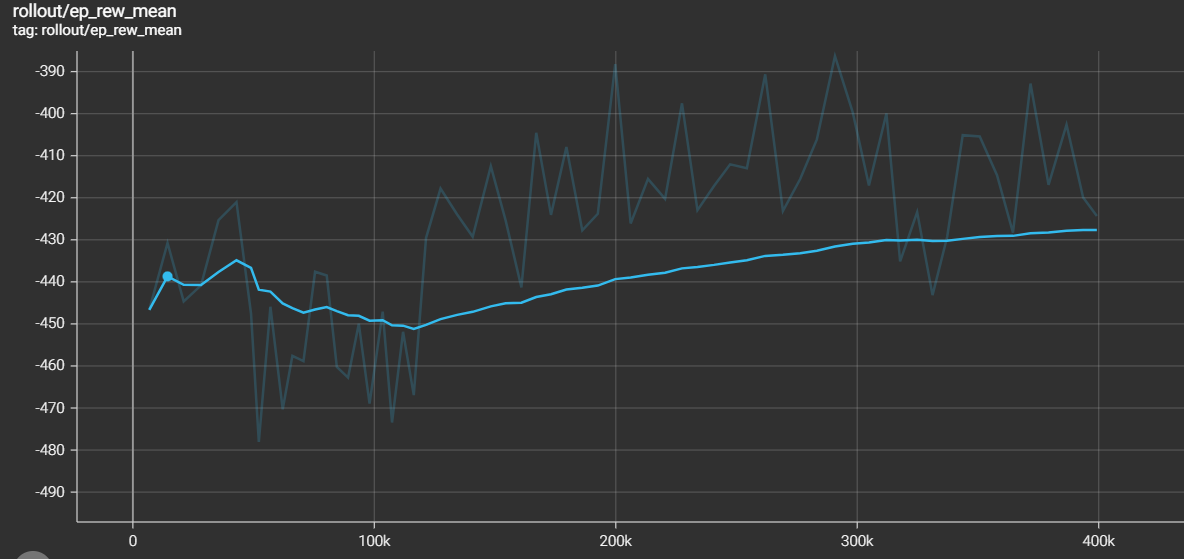
I am training the DQN (with 2 hidden layers of 64 each) for 400k steps. The DQN seems to learn slowly (ep_rew_mean at step 1: -446, at step 400k: -427; see tensorboard log for further details)
System Info:
- OS: Linux-5.4.188+-x86_64-with-Ubuntu-18.04-bionic
- Python: 3.7.13
- Stable-Baselines3: 1.6.0
- PyTorch: 1.12.0+cu113
- GPU Enabled: True
- Numpy: 1.21.6
- Gym: 0.21.0
Complete code can be found on: https://gist.github.com/techboy-coder/795e9dc00b743901963c75ede56cf6eb
Reward:
Reward calculation idea:
- If dead: Reward = -500
- If alive: Reward = Score + [Change in score * 50 + previous change in score * 0.2 - 0.5 (penalty to avoid infinite circles...)]
Reward calculation python implementation:
self.delta = (snake.score - self.score) * 50 + self.delta * 0.2 - 0.05
self.score = snake.score
reward = self.delta + snake.score
self.dead = not snake.alive
if self.dead:
reward = -500
steps = 400000
with ProgressBarManager(steps) as callback:
model.learn(total_timesteps=steps, log_interval=200, callback = callback)
- Evaluation of untrained model: mean_reward:-479.99 +/- 31.81
- Evaluation of trained model: mean_reward:-429.42 +/- 93.32
- Evaluation of model making random moves:mean_reward:-425.72 +/- 117.29
My question:
Why is the model not learning much (is performing similarly to a model making random moves) after 400k steps? I have played around with the learning rate, network size, observation size, but haven't seen any big improvements. Do I need to train longer?
Checklist
- [X] I have read the documentation (required)
- [X] I have checked that there is no similar issue in the repo (required)
Unfortunately, the maintainers don't have time to offer technical support. Check the links here to find other forums to ask this question. I also suggest that you carefully read the RL Tips and Tricks in the documentation, it could really help.