N-step updates for off-policy methods
Changes
OffPolicyAlgorithm
- Now accepts buffer class as argument type
- Rationale: allows for other types of replay buffers besides the current implementations
- Now accepts arguments for the replay buffer
- Rationale: makes it easier to pass arguments because we don't need to check every scenario.
- I haven't moved
buffer_sizein it
NStepReplayBuffer
- Derives ReplayBuffer and adds two more arguments,
n_stepandgamma. - Overrides
_get_samples(self, batch_inds, env) -> ReplayBufferSamplesto compute NStepReturns.- Computation is done purely through numpy without python loops. This makes the implementation easier and faster.
Computing Nstep returns
- Find correct transition indices
- Create a 2d mask for the rewards using done
- Filter the mask so that
self.posis ignored because it contains older experience. - Multiply the filter with the reward, the discounting, and sum across.
Motivation and Context
- [x] I have raised an issue to propose this change (required for new features and bug fixes)
Closes #47
Types of changes
- [ ] Bug fix (non-breaking change which fixes an issue)
- [x] New feature (non-breaking change which adds functionality)
- [x] Breaking change (fix or feature that would cause existing functionality to change)
- [ ] Documentation (update in the documentation)
Checklist:
- [x] I've read the CONTRIBUTION guide (required)
- [x] I have updated the changelog accordingly (required).
- [x] My change requires a change to the documentation.
- [x] I have updated the tests accordingly (required for a bug fix or a new feature).
- [ ] I have updated the documentation accordingly.
- [x] I have checked the codestyle using
make lint - [x] I have ensured
make pytestandmake typeboth pass.
Nstep Implementation details
Funny, I also recently gave it a try here: https://github.com/DLR-RM/stable-baselines3/tree/feat/n-steps
The implementation appears mostly the same. I would like to add the class and the arguments as parameters to the OffPolicyAlgorithm along with a variable named replay_args, in a similar fashion to how policies are passed. This will make it easy to add other methods as well. IIRC energy based replay buffer was also considered at some point.
@araffin
So I was working on this and there's a bug with both your and my implementations.
The bug is due to % self.buffer_size.
https://github.com/DLR-RM/stable-baselines3/blob/41eb0cb37e8ac35413c0b11d0d5bd5cfbd2c92e2/stable_baselines3/common/buffers.py#L441-L454
The bug is basically the same as with memory optimization. To be exact, going around the buffer (% self.buffer_size) gives no quarantine that the transition is part of the same trajectory.
My implementation is WIP and there's a couple of issues that I am working on.
** Edit: **
Completed it. Removed loops, added tests, using just numpy arrays, no loops. Should be quite fast.
The bug is basically the same as with memory optimization.
:see_no_evil: Yep, I did only quick test with it and could not see any improvement yet.
Completed it. Removed loops, added tests, using just numpy arrays, no loops. Should be quite fast.
Sounds good =)
Ping me when you want a review
I merged master and removed the generic from offpolicyalgorithm since it wasn't discussed. I think it's ready for a review.
Ps. sorry for autoformatting >.< ...
Ps. sorry for autoformatting >.< ...
I will do a PR soon for that ;) Apparently will be with black.
On a quick glimpse it looks good, like arrafin already mentioned, but I would be even more exhaustive with the comments. The numpy tricks are compact and can be performant, but the code becomes harder to understand. I would also include the shape of arrays in the comments with a definition of contents, e.g. # (batch_size, num_actions) of {0,1}.
I'm currently given a quick try to that one (feat/n-steps in the zoo), and it already yields some interesting results with DQN on CartPole ;)
And I couldn't notice any slow down.
The command:
python train.py --algo dqn --env CartPole-v1 -params replay_buffer_class:NstepReplayBuffer replay_buffer_kwargs:"dict(n_step=4)" --num-threads 2 -tb /tmp/sb3
The two first curves are with n_step=4 (much more stable learning) and the two others are with n_step=1
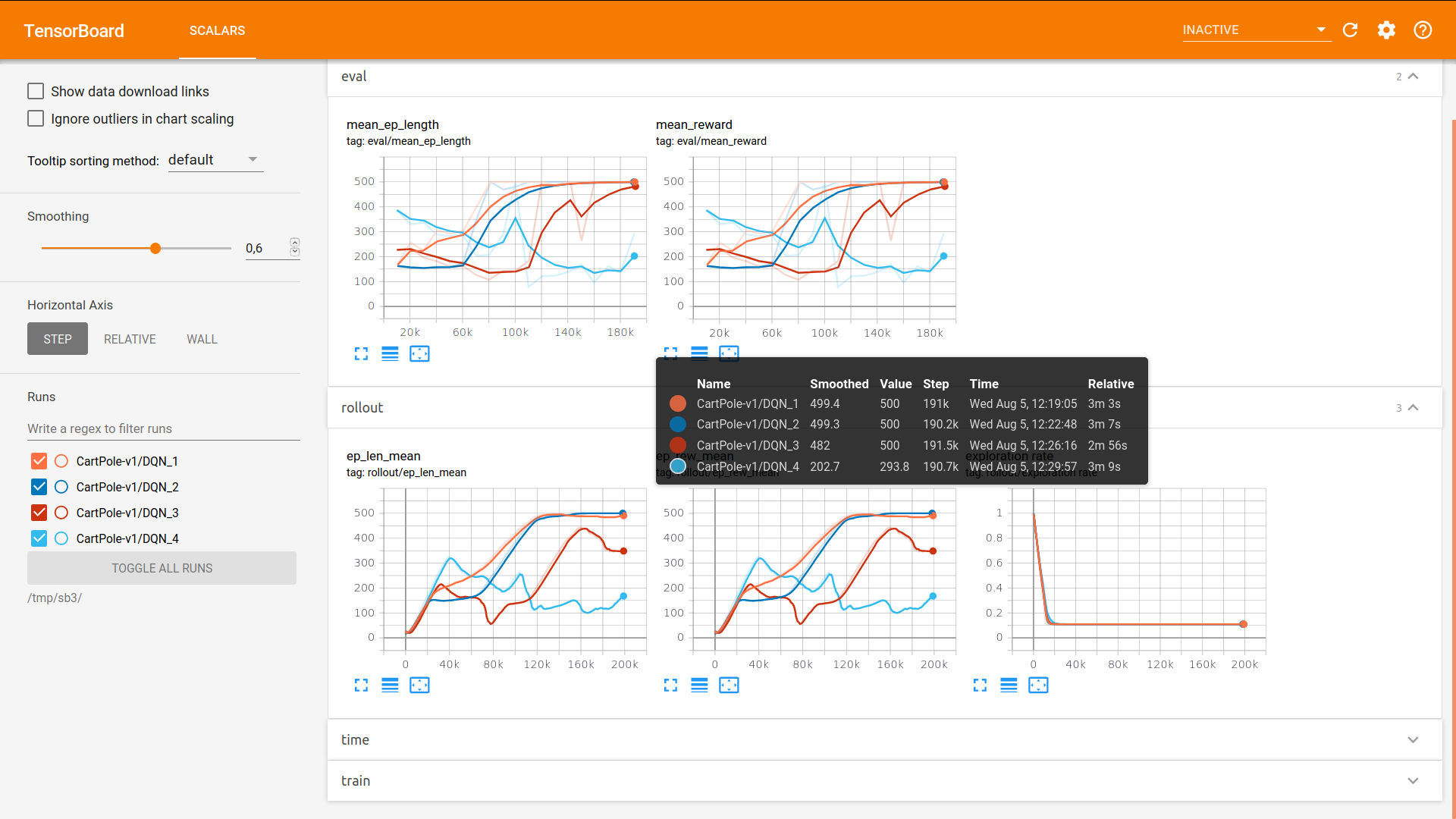
I will try with SAC soon.
Looks good! What about the FPS? It should have very small impact, but, there are still some optimizations that can be made.
Looks good! What about the FPS? It should have very small impact, but, there are still some optimizations that can be made.
On DQN with CartPole, as mentioned, I couldn't notice the difference (all runs where around 1000FPS). For SAC, experiments are currently running but there is no difference for now =)
For sac, I am not sure if n-steps can be applied directly as I am under the impression that the backup requires the entropy for the intermediate states as well, not just the last one.
For sac, I am not sure if n-steps can be applied directly as I am under the impression that the backup requires the entropy for the intermediate states as well, not just the last one.
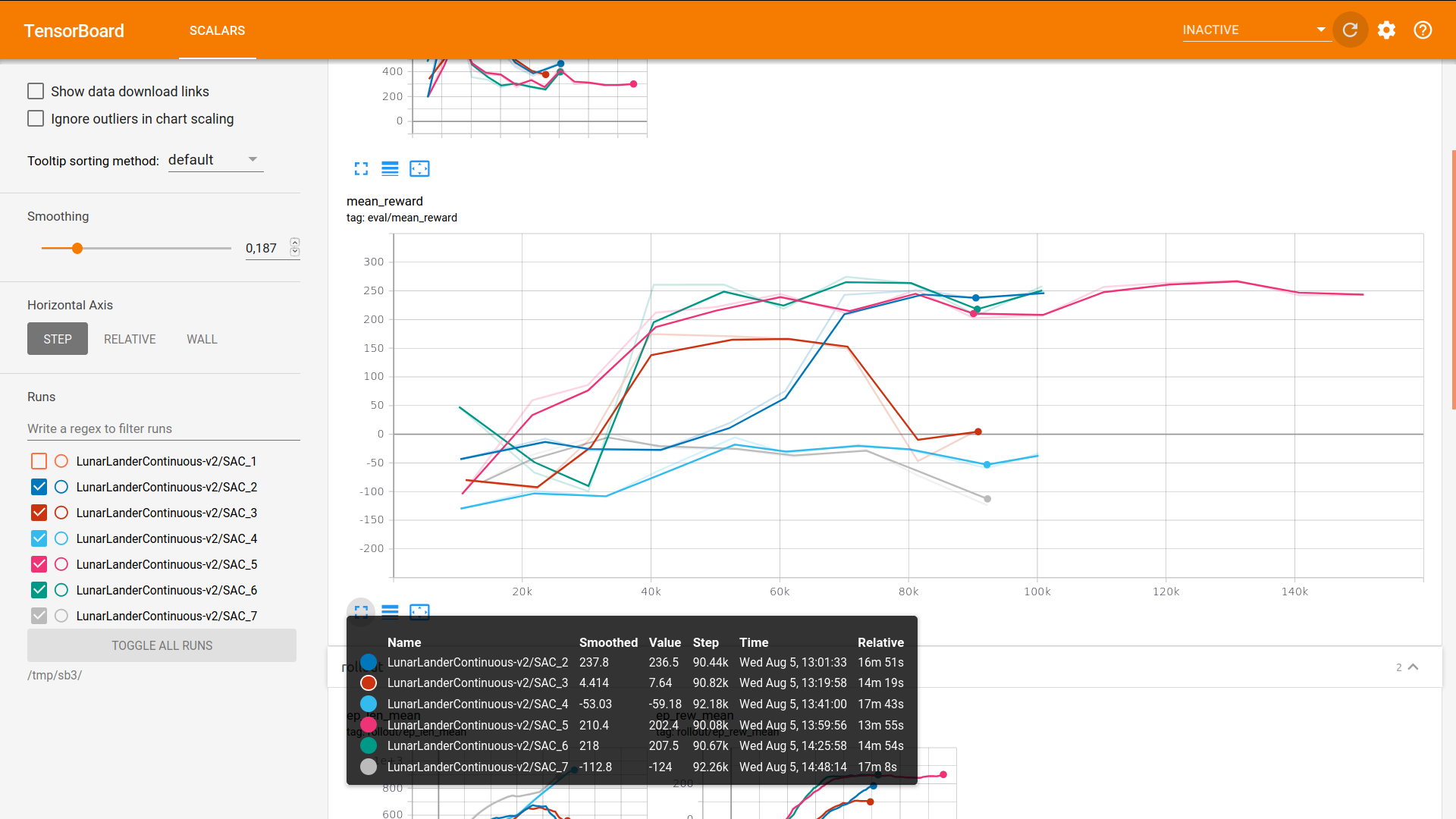
Good point, for now I'm just checking quickly assuming the entropy term is neglectable compared to the reward term. I could see a positive impact on LunarLanderContinuous but not on PyBullet envs yet (probably because the reward is quite shaped).
The 3 runs with mean reward > 200 are the one with the n-step replay buffer:
I added a sketch of how it would look like for SAC, it fits in ~10 lines. We would need to allocate one more array log_prob of size buffer_size and pass the actor to the buffer.
I also did a small pre-processing step to remove duplicated indices when predicting the log_prob.
If you have plans for other n_step methods, (I'd love to have retrace), then, we can sketch out how those would work (most of which require action probabilities) and figure out how to incorporate sac there as well, I was thinking of something along the lines of adding an entropy coefficient like so:
# compute rewards, entropy and other weighting fractions onto rewards,
rewards = (rewards + entr_coef * entropy) @ weighting
If we go with something like this, because we will be computing action probabilities anyway, we would have the entropy for (almost) free and it will be easier to add everything together. It will also open a path towards other soft methods.
'd love to have retrace
I would need to look at that again. but yes, it would be nice to have an eligibility trace estimate style (i.e. TD(lambda) style).
The weighting is already there with the gammas, no?
we would have the entropy for (almost) free
?
For me the main issue is how to compute action log proba in a clean way? (passing the actor to the sample method, as we do when we normalize the rewards seems the cleanest for now)
Btw, n-step does not help for now on PyBullet envs (I think to think why, maybe some tuning is needed) but it improves results and stability on env like LunarLander or BipedalWalkerHardcore (I could finally get the maximum performance with SAC).
The weighting is already there with the gammas, no?
In retrace(lambda), treebackup(lambda), Q(lambda), etc, the weighting also uses some other factor besides gamma, thus I added it in a single term.
we would have the entropy for (almost) free
?
To compute Retrace, TreeBackup and Importance Sampling, we need the action probabilities. If we have the action probabilities, we also have the entropy (for free), thus if we implement any of the above, we will also have a clear path towards implementing n-steps with entropy.
For me the main issue is how to compute action log proba in a clean way? (passing the actor to the sample method, as we do when we normalize the rewards seems the cleanest for now)
I was also thinking of passing a function instead of the actor directly but the two are more or less the same.
In retrace(lambda), treebackup(lambda), Q(lambda), etc, the weighting also uses some other factor besides gamma, thus I added it in a single term.
yes, I meant that gamma played already the weighting role.
I was also thinking of passing a function instead of the actor
sounds better, yes ;)
EDIT: if you don't pass the actor, you still need to know the device (see issue #111 )
Yeah makes sense, I assume the function will be of the form np.ndarray -> np.ndarray, so as to make it agnostic of the device.
Yeah makes sense, I assume the function will be of the form np.ndarray -> np.ndarray, so as to make it agnostic of the device.
Good idea
So how should we continue from here? Since n_steps was planned for v1.1, I can take the time to add extensions and draft a more generic version of this that also includes entropy.
Yes, sounds good ;) I would wait for support of all algorithms anyway to avoid inconsistencies. But if it is ready and fully tested, we can merge it with master.
I don't have anything to add to NStepReplay, or any other tests. So feel free to merge this. In the mean time, I can start drafting the next step (hah, not intended).
I don't have anything to add to NStepReplay, or any other tests.
So the entropy is not part of it? Maybe add an example in the doc.
I’d rather have a separate implementation that includes entropy but it’s up to you.
Yes I will add an example in the docs.
I don't have anything to add to NStepReplay, or any other tests.
So the entropy is not part of it? Maybe add an example in the doc.
I’d rather have a separate implementation that includes entropy but it’s up to you.
Hmm, the issue is that if we merge it now, it will be half-working only (working for DQN, TD3 but not for SAC).
Yes I will add an example in the docs.
yes, please =)
Fair point! I have a couple of weeks before grad classes pick up the pace so hopefully I will have everything tied up before then.
@araffin I am considering the following changes:
- Use a component called say "batch generator" that given the indices produces the batch.
- Instead of subclassing the buffer class for the different buffers, just pass
buffer_kwargs, the constructor of the buffer will then create the correct component.
The component can be anything from simple n_steps to n_steps with entropy.
This removes the need to create all buffer combinations, e.g. if we were to have prioritized replay, we wouldn't need to create n_step_prioritized_replay.
What do you think?
Use a component called say "batch generator" that given the indices produces the batch.
How is that different from _get_samples() ?
Instead of subclassing the buffer class for the different buffers, just pass buffer_kwargs, the constructor of the buffer will then create the correct component.
Not sure what you mean, it sounds like a _get_samples() with a lot of branching?
How is that different from
_get_samples()?
_get_samples() is bound to the class of the buffer. I would like to use composition instead of sub-classing the buffer to create new _get_samples().
very rough example
class ReplayBuffer(BaseBuffer):
def __init__(self, ..., batch_method, **batch_kwargs):
self._sampler = Sampler.make(batch_method, **batch_kwargs) # Will create the correct sampler depending on args
# make is a class method.
The consequence here is that we can do:
env = ...
agent_classes = [TD3, SAC] # SAC will add `use_entropy=True` in `buffer_kwargs` unless specified otherwise
for cls in agent_classes:
agent = cls(env, buffer_kwargs={'batch_method':'nsteps', 'nsteps':5}) # all these can be trivially logged because they are strings and ints
The pros are:
- We remove the need to provide the buffer class
- The sampler can be swapped on the fly
- We don't need to create multiple classes for buffers that just combine other classes, e.g. for Nstep+PER, we will not have to add
NStepPer, andEntropyNStepPer, for Retrace(lambda) we will not have to addRetracePer,EntropicRetracePer - We can make it trivial to create new sampler classes and register them.
- SAC will not actually require a new buffer class for itself that would need to be specified in its arguments to ensure correctness.
- The number of classes is linear to the number of sampler methods.
The cons are:
- More types
- Need to write a function to construct the correct sampler (fairly easy)