Linly
 Linly copied to clipboard
Linly copied to clipboard
Chinese-LLaMA 1&2、Chinese-Falcon 基础模型;ChatFlow中文对话模型;中文OpenLLaMA模型;NLP预训练/指令微调数据集
使用llma.cpp对int4模型进行推理时,加载模型需要错误了。有大佬遇到过这个问题吗? 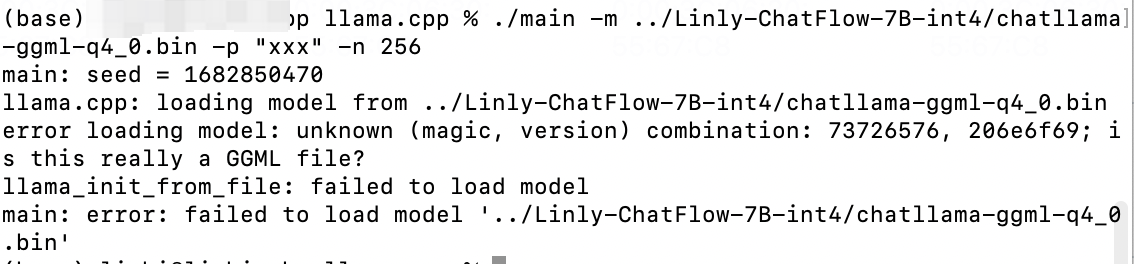

The finetune script ``` use `python3 preprocess.py xxx` to encode dataset token id use `deepspeed pretrain.py xxx` to finetune ``` the `preprocess` add `CLS_TOKEN` in the left `document` and `SEG_TOKEN`...
我生成的结果:  readme中的结果:分词结果分别为:无线电,法国,别研究。 有些答非所问,不知道是什么原因
33b模型权重少了五份 https://huggingface.co/P01son/LLaMA-zh-33b-hf/tree/main pytorch_model-00001-of-00007.bin pytorch_model-00007-of-00007.bin 只有这两个
指令微调readme中提供了一个数据下载的超链接:https://huggingface.co/datasets/P01son/instructions 但对应repo内还没数据,请问后期会上传数据吗?大概什么时间?
when I run pretrain.py of llama-7b model, it has exception below (not user zero3): ExceptionException: : Current loss scale already at minimum - cannot decrease scale anymore. Exiting run.Current loss...