phoenix
 phoenix copied to clipboard
phoenix copied to clipboard
AI Observability & Evaluation
![]()


![]()



Phoenix provides MLOps insights at lightning speed with zero-config observability for model drift, performance, and data quality. Phoenix is notebook-first python library that leverages embeddings to uncover problematic cohorts of your LLM, CV, NLP and tabular models.
Installation
pip install arize-phoenix
Quickstart


Import libraries.
from dataclasses import replace
import pandas as pd
import phoenix as px
Download curated datasets and load them into pandas DataFrames.
train_df = pd.read_parquet(
"https://storage.googleapis.com/arize-assets/phoenix/datasets/unstructured/cv/human-actions/human_actions_training.parquet"
)
prod_df = pd.read_parquet(
"https://storage.googleapis.com/arize-assets/phoenix/datasets/unstructured/cv/human-actions/human_actions_production.parquet"
)
Define schemas that tell Phoenix which columns of your DataFrames correspond to features, predictions, actuals (i.e., ground truth), embeddings, etc.
train_schema = px.Schema(
prediction_id_column_name="prediction_id",
timestamp_column_name="prediction_ts",
prediction_label_column_name="predicted_action",
actual_label_column_name="actual_action",
embedding_feature_column_names={
"image_embedding": px.EmbeddingColumnNames(
vector_column_name="image_vector",
link_to_data_column_name="url",
),
},
)
prod_schema = replace(train_schema, actual_label_column_name=None)
Define your production and training datasets.
prod_ds = px.Dataset(prod_df, prod_schema)
train_ds = px.Dataset(train_df, train_schema)
Launch the app.
session = px.launch_app(prod_ds, train_ds)
You can open Phoenix by copying and pasting the output of session.url into a new browser tab.
session.url
Alternatively, you can open the Phoenix UI in your notebook with
session.view()
When you're done, don't forget to close the app.
px.close_app()
Features
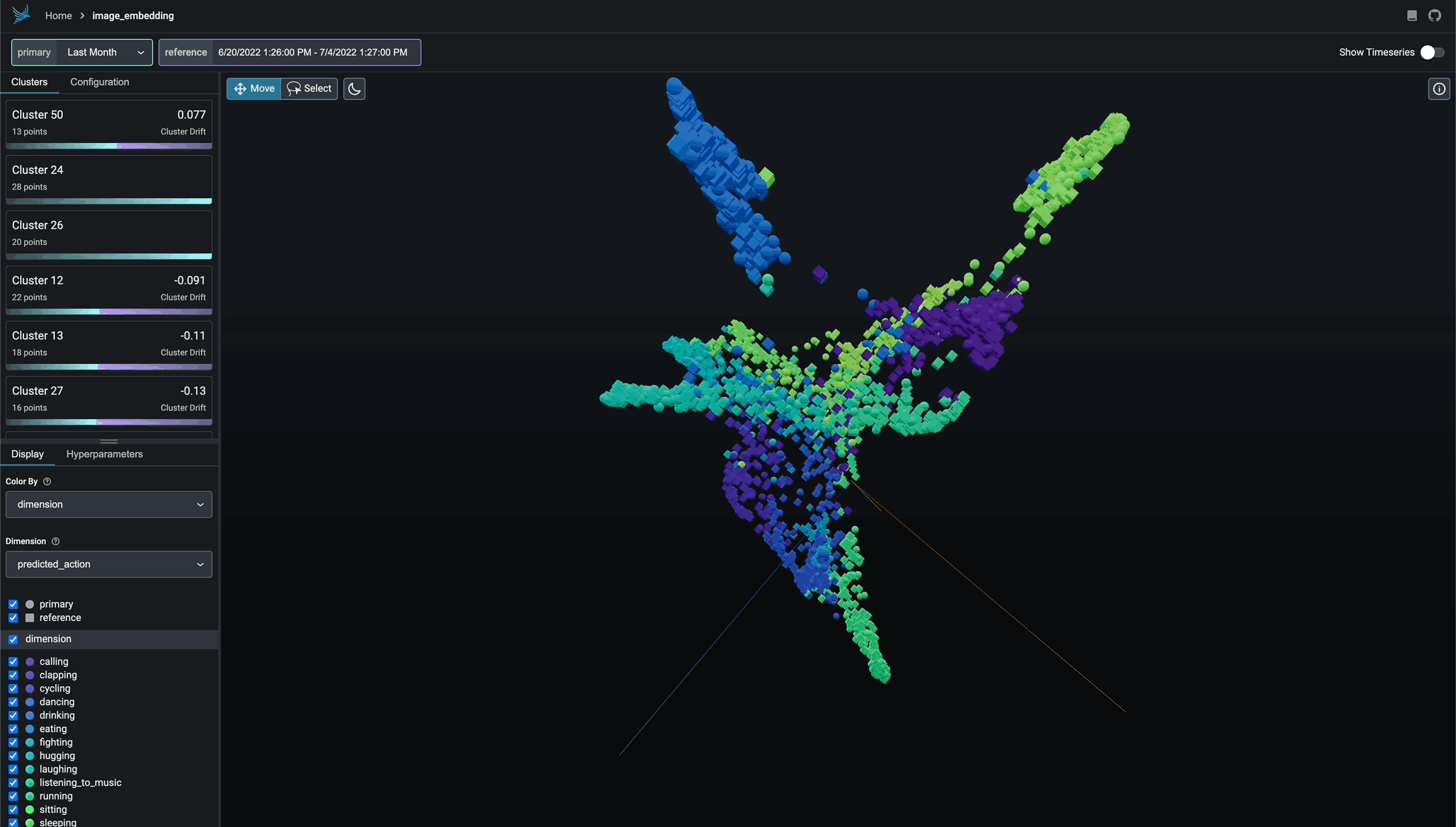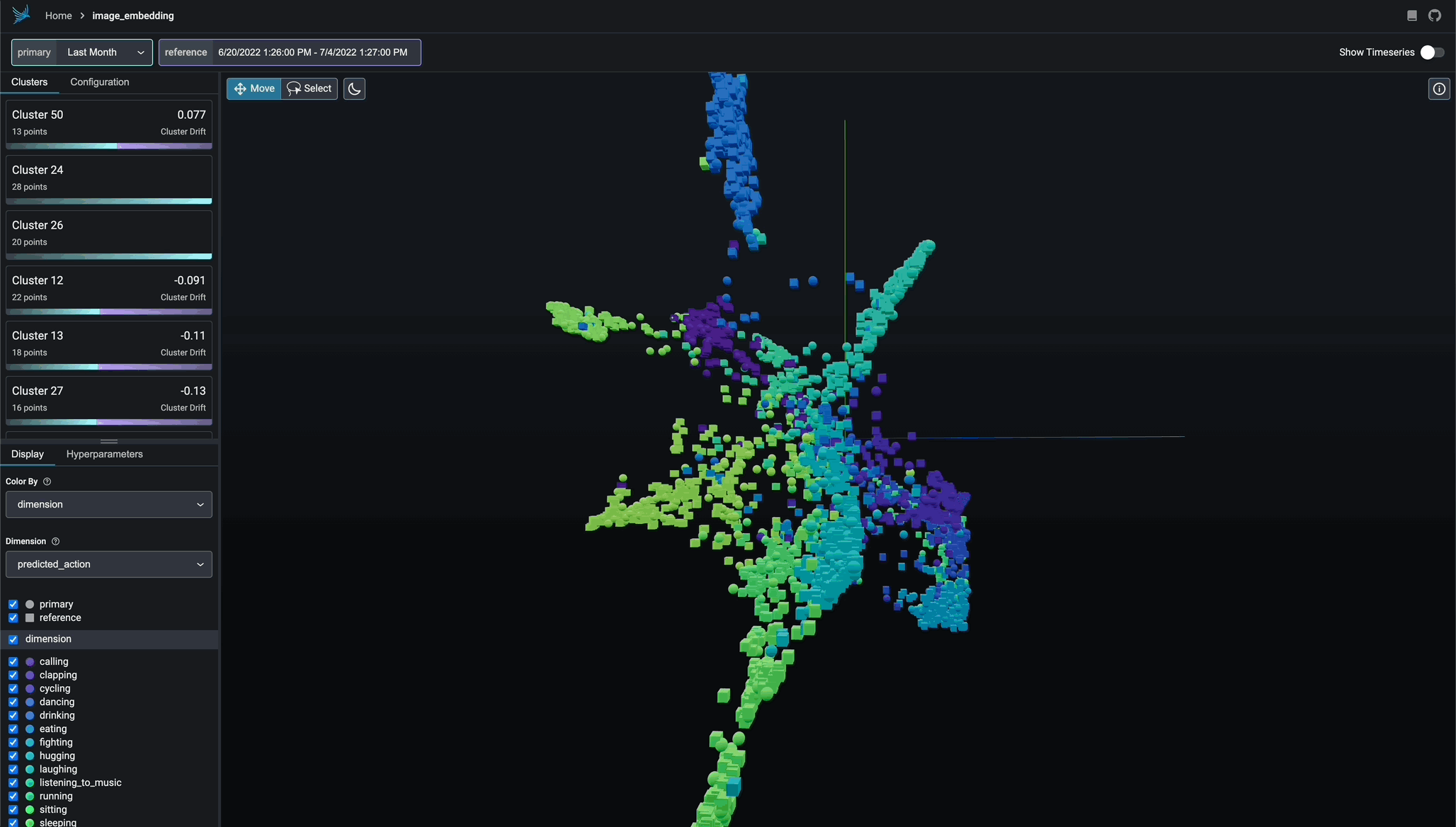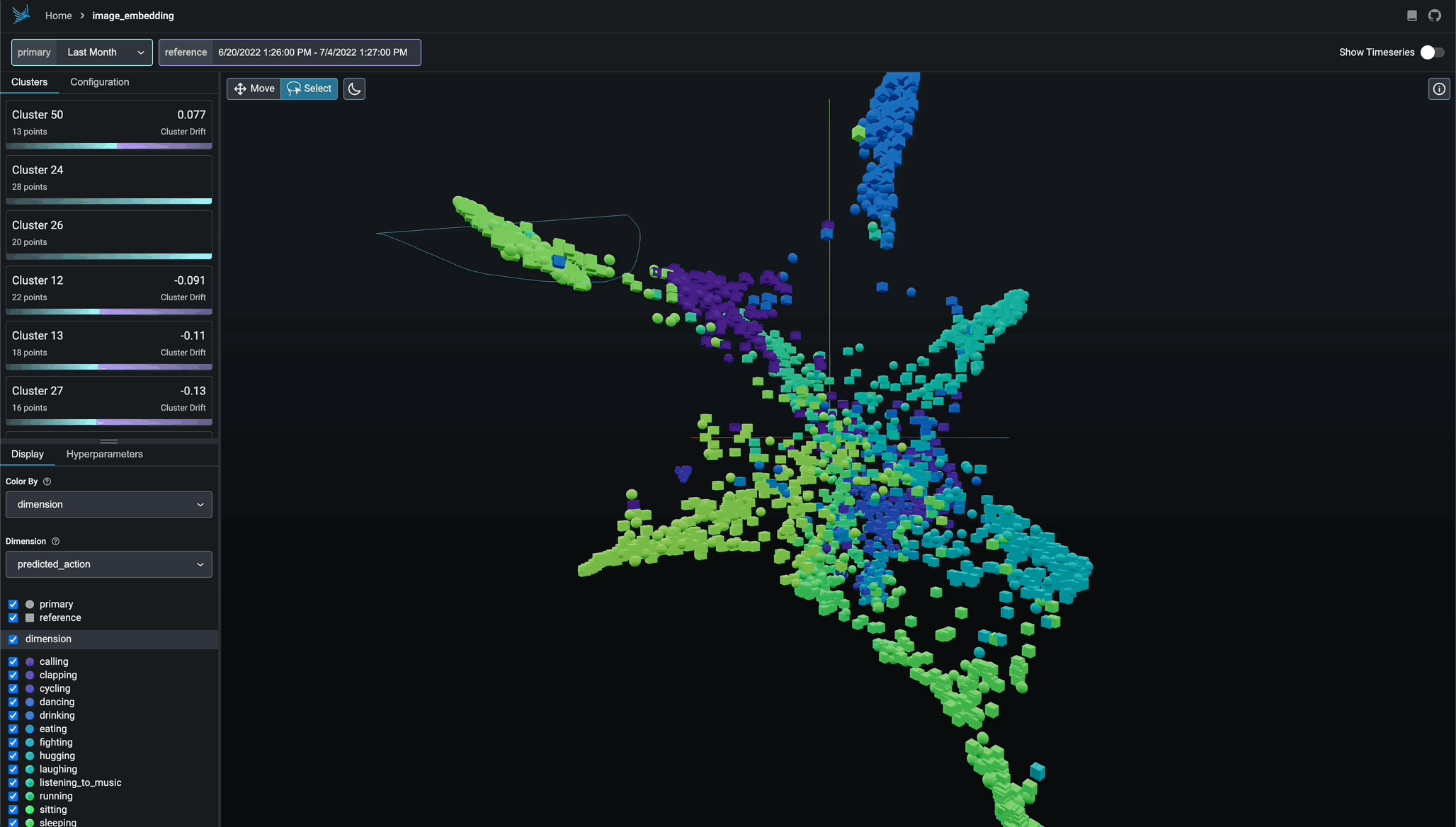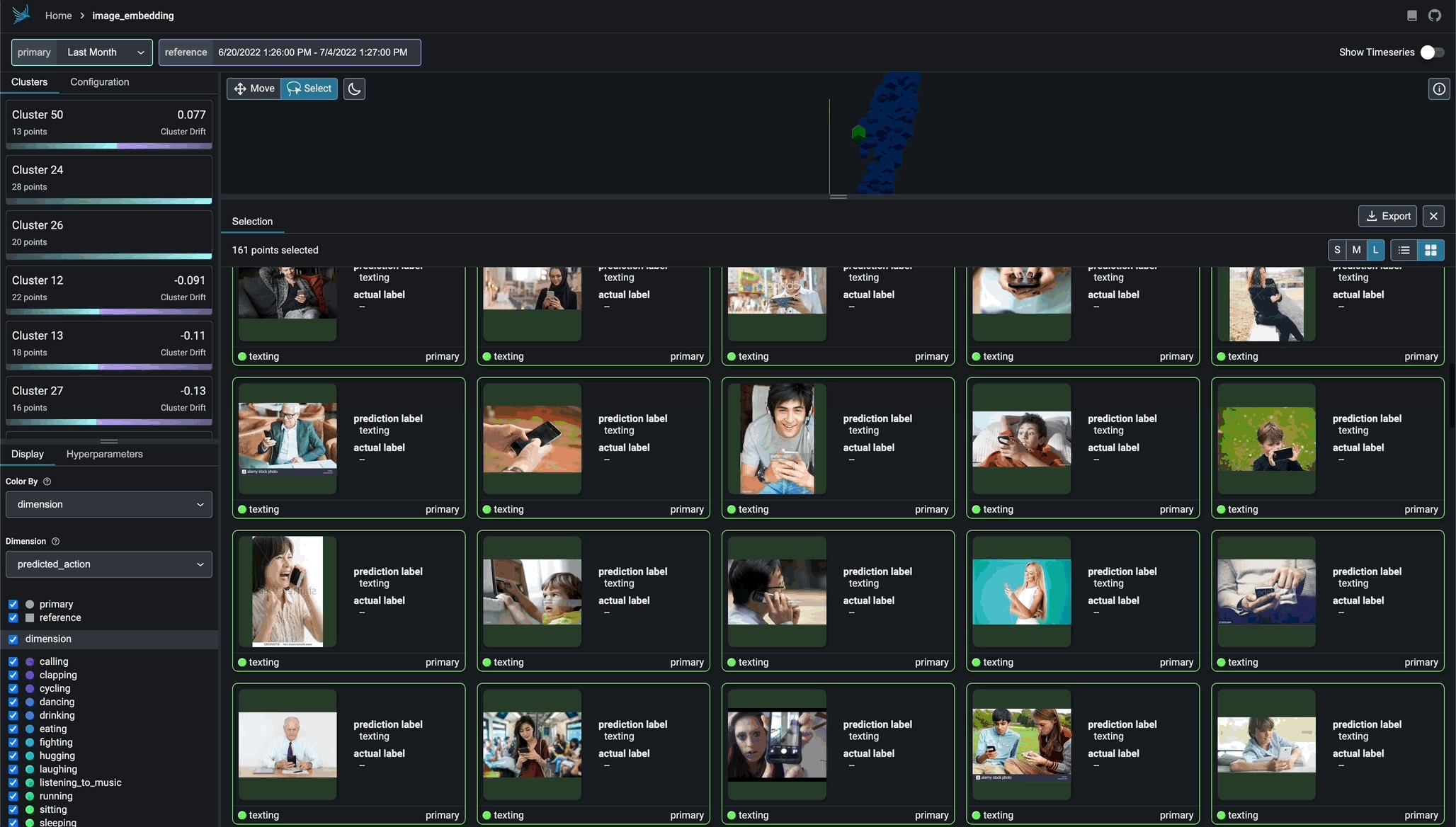
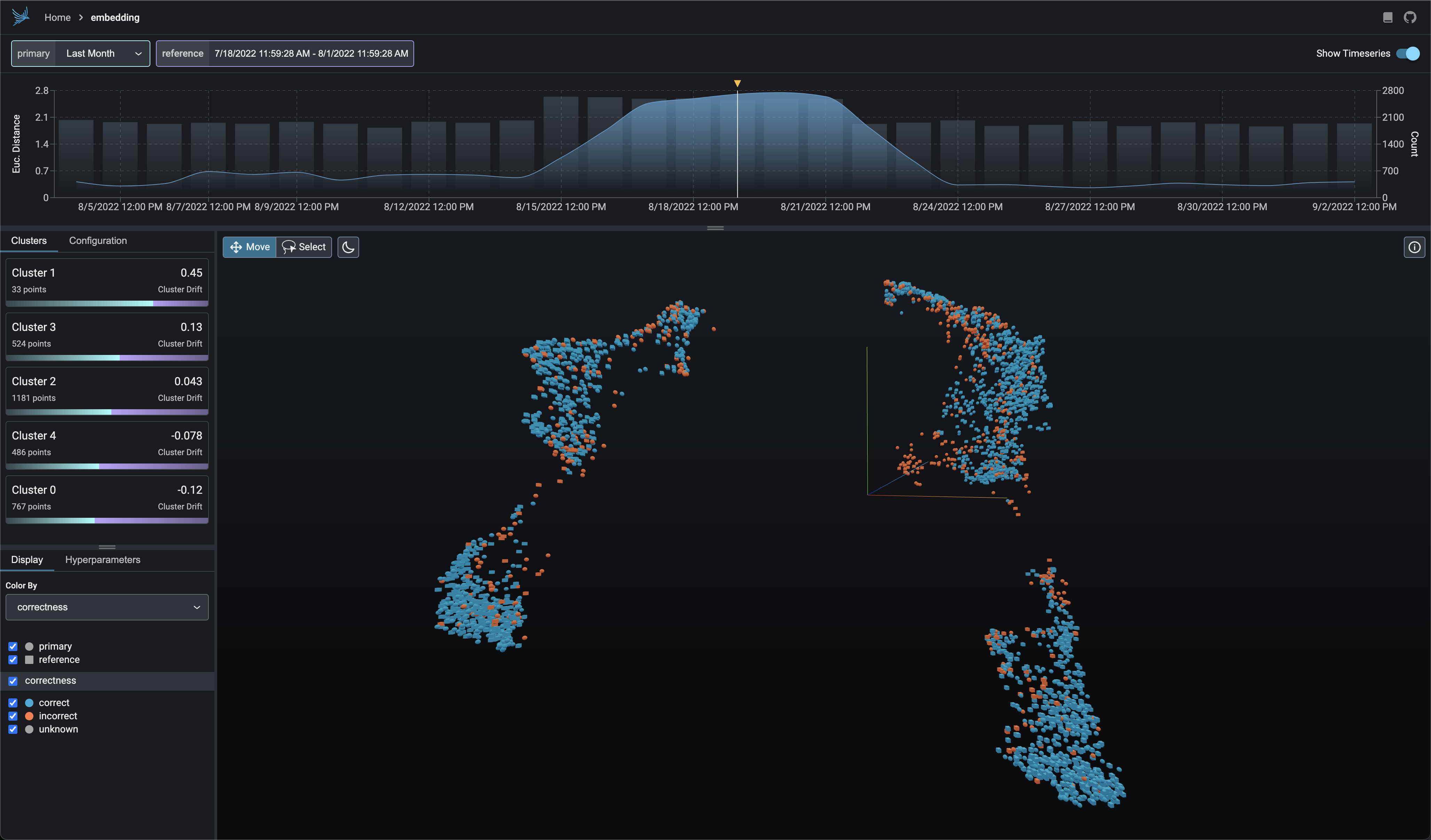
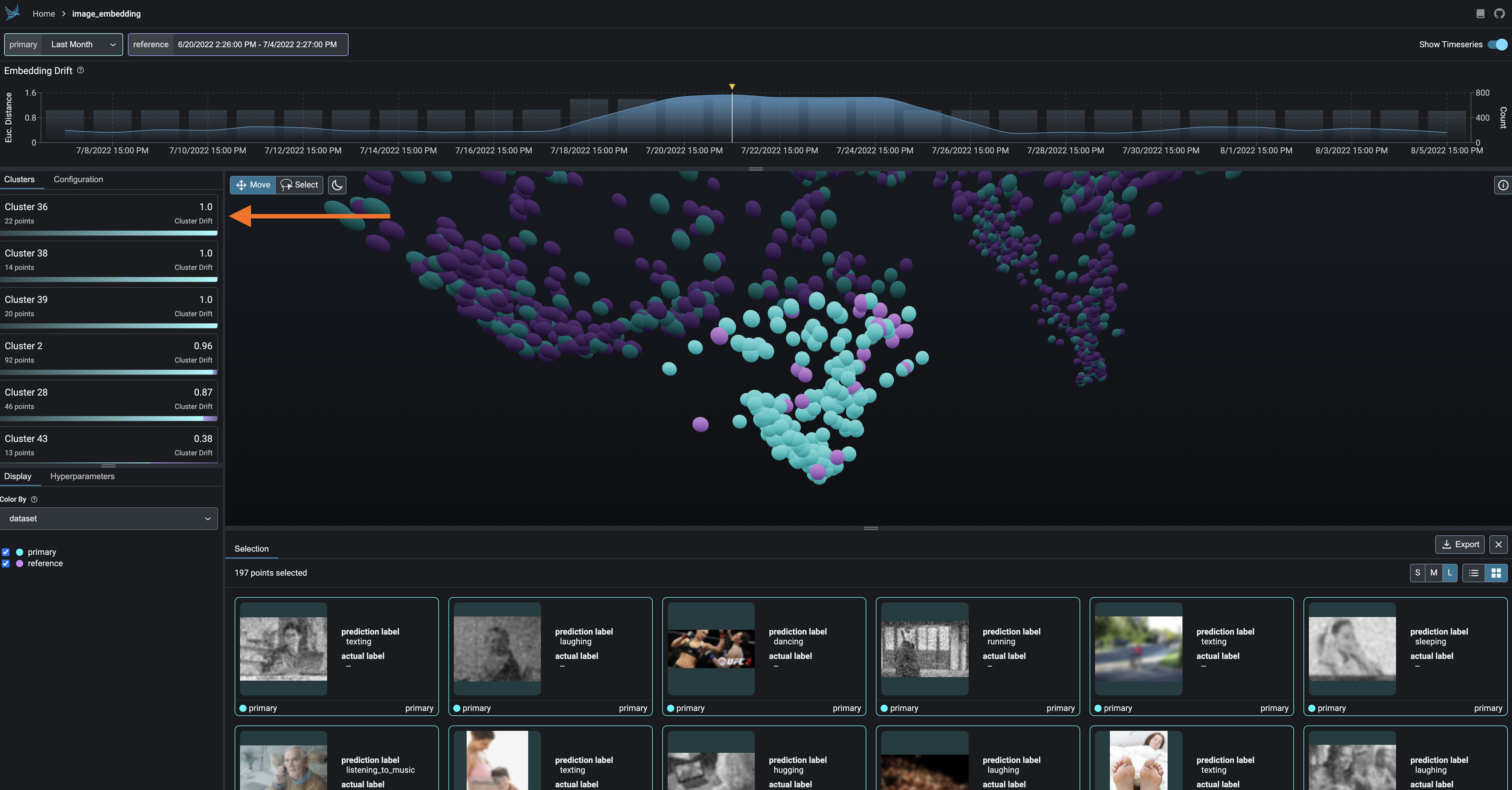
Embedding Drift Analysis
Explore UMAP point-clouds at times of high euclidean distance and identify clusters of drift.
UMAP-based Exploratory Data Analysis
Color your UMAP point-clouds by your model's dimensions, drift, and performance to identify problematic cohorts.
Cluster-driven Drift and Performance Analysis
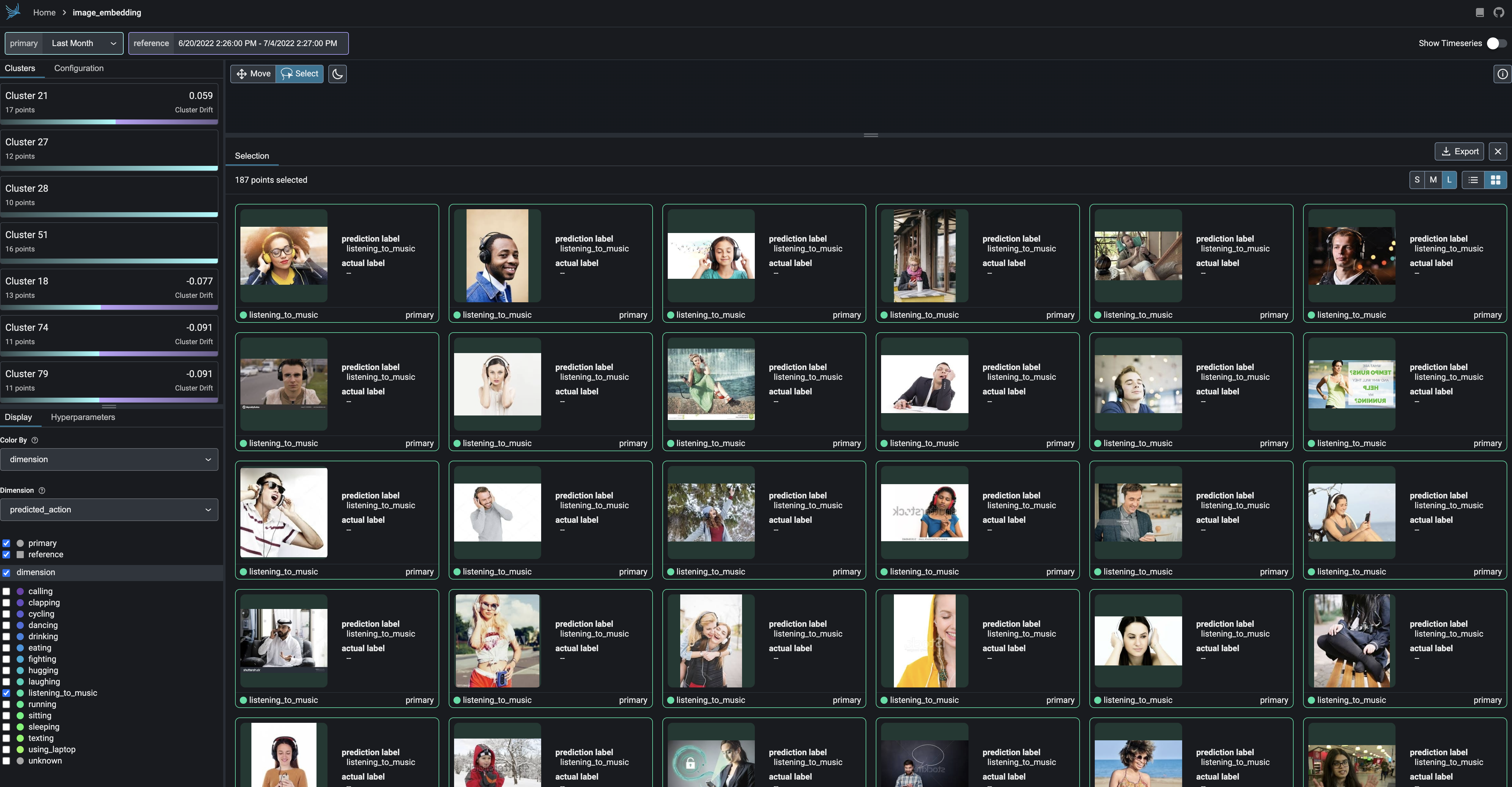
Break-apart your data into clusters of high drift or bad performance using HDBSCAN
Exportable Clusters
Export your clusters to parquet files or dataframes for further analysis and fine-tuning.
Documentation
For in-depth examples and explanations, read the docs.
Community
Join our community to connect with thousands of machine learning practitioners and ML observability enthusiasts.
- 🌍 Join our Slack community.
- 💡 Ask questions and provide feedback in the #phoenix-support channel.
- 🌟 Leave a star on our GitHub.
- 🐞 Report bugs with GitHub Issues.
- 🐣 Follow us on twitter.
- 💌️ Sign up for our mailing list.
- 🗺️ Check out our roadmap to see where we're heading next.
- 🎓 Learn the fundamentals of ML observability with our introductory and advanced courses.
Thanks
- UMAP For unlocking the ability to visualize and reason about embeddings
- HDBSCAN For providing a clustering algorithm to aid in the discovery of drift and performance degradation
Copyright, Patent, and License
Copyright 2023 Arize AI, Inc. All Rights Reserved.
Portions of this code are patent protected by one or more U.S. Patents. See IP_NOTICE.
This software is licensed under the terms of the Elastic License 2.0 (ELv2). See LICENSE.