Alan Wei
Alan Wei
> 以下信息仅供参考,不对您构成任何投资建议。 2020 年是我真正接触股票投资的第一年,从六月底开仓到现在刚好半年时间。昨天(12 月 18 日)是今年的最后一个四巫日(Quadruple witching day),上周我也对自己的投资组合进行了今年最终的调整,准备迎接接下来的圣诞行情。 因为本文涉及到的内容较多,我会分为上、中、下三篇。上、中两篇主要介绍我关注的具体板块及个股,下篇会更多地讲一些形而上的投资心得和对未来的展望。 ### 总体回顾 按照惯例我们先来看一下这半年的总体投资回报率。 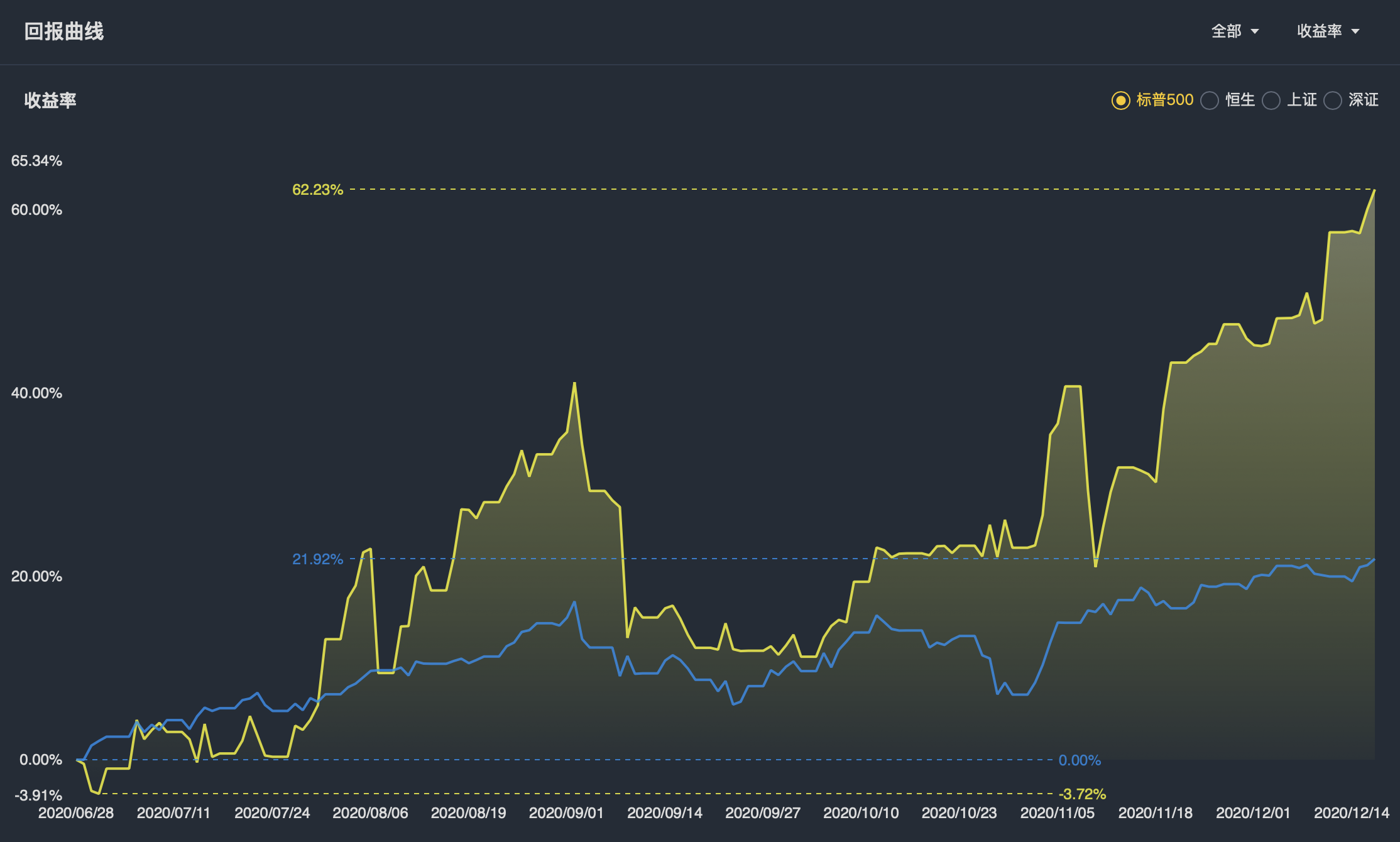 借着年底的这波牛市,今年的投资回报率创下了 62.23% 的新高,以此推算的年化回报率大约为 132.06%,计算方式以老虎证券的算法为准。 这当然主要归功于今年四月份后美股的整体大牛市,除了九、十两个月出现了小幅度回调外,美股整体还是走出了一波非常强势的行情。虽然今年出现了像新冠肺炎这样大的黑天鹅事件,但在美联储 2 万亿救助法案和长期低利率的宽松货币政策下,美股在经历了三月份十天四次熔断后,又奇迹般地恢复了生机,三大股指(标普、纳斯达克、道琼斯)都在 12 月份创下了历史新高。 有人说现在的美股正在经历一段**虚假的繁荣**,这个观点我是赞同的。在全球范围内新冠疫情远未成功控制的情况下,根据国际货币基金组织(IMF)最新的预测,2020 年全球 GDP 的增长率为 -4.4%(2019 年为 +2.8%)。在这样的经济大背景下,屡创新高的美股自然存在着一定水分,但对于擅长造梦的资本市场来说,在某种程度上这样的表现又是合理的,原因主要有以下两点:...
2020 年 11 月 12 日,拼多多(NASDAQ: PDD)在盘前发布了 2020 年第三季度的财报。该季度拼多多营收 142.098 亿元,同比增长 89%。归属于拼多多普通股股东的净亏损为 7.847 亿元,去年同期净亏损为 23.35 亿元。非美国通用会计准则(Non-GAAP)下,归属于拼多多普通股股东的净利润为 4.664 亿元,去年同期净亏损为 16.604 亿元,首次实现单季度盈利。随着这份财报的发布,拼多多的股价也在随后的两个交易日内大涨超过 30%,创下了 $155.61 的历史新高。 从 2018 年上市就让人『看不懂』的拼多多越来越让更多的人『看不懂』了,这其中也包括我自己。作为原先拼多多坚定的多头,却在 $86.75 就出光了自己所有的筹码,彻彻底底地踏空了这一波超过 70% 的涨幅。微信流量红利、二三线下沉市场、中小商家外溢、百亿补贴,这些贴在拼多多身上的标签真的足以支撑其...
关注美股的朋友们最近应该都注意到了一家大热的 IPO 公司,那就是 Snowflake。作为云计算领域一只新进的独角兽,Snowflake 在资本市场受到了前所未有的追捧,其中最耀眼的标签就是『股神』巴菲特的加持。要知道老巴可是在 1956 年福特 IPO 后就再也没有参与过新股的发售,这次却通过伯克希尔公司购买了 700 万股的 Snowflake,按照发行价来算市值 8.4 亿美金,而按照截止十月十三日的收盘价计算,这 700 万股的 Snowflake 价值已经飙升到了 17 亿美金,翻了一倍不止。 Snowflake 到底是一家什么样的公司能够让声称『不懂科技股』的巴菲特都为它破戒呢?让我们看看能不能从 Snowflake 的招股书中找到一些蛛丝马迹。 在招股书的第一页,Snowflake 的 slogon 是 MOBILIZING THE...
作为一个『二进宫』的阿里人,这个月刚好是入职 Lazada 的两周年。虽然两次与阿里结缘都是在数据团队(DT),但这次从数据中台到业务前台,从个人贡献者到 TL,团队和身份的转变让我对个人的发展及未来要做的事情都有了更深入的了解和认识,这里也和大家分享一下在业务前台做数据工程的经验与思考。 作为一名前端开发出身的工程师,16 年在 DT 时对于数据团队在整个企业中扮演的角色其实是没有很深的体感的,只知道自己做的是面向淘系商家的数据产品『生意参谋』。而在 18 年加入 Lazada 数据团队后,作为当时大团队里的第一个工程同学,才第一次有机会一窥数据团队的全貌。 ## 数据团队的组成 从最粗的粒度上来讲,数据团队可以分为 4 大部分,即数据采集,数据仓库,数据服务和数据产品。4 个部分自下而上地融通出了一条条数据管道,让通过各个渠道采集过来的明细数据最终成为了驱动业务决策和运营的数据洞见(Insight)。所以从本质上来讲,数据团队并不生产数据,因为数据其实是来源于真实用户与业务系统的日常交互(投放、浏览、点击、购买、订单、物流等)。数据团队更像是数据的搬运工,并在搬运的过程中对数据进行适当加工,让海量、零散的数据最终可以成为业务决策的关键因子来影响下一轮真实用户与业务系统的交互方式,从而形成数据闭环。 ## 工程团队的定位 在数据采集,数据仓库,数据服务和数据产品这 4 个部分中,工程团队很显然承担的是『数据服务』这一层。数据服务作为数据工程团队的交付物,如果我们再把『服务』这个词具象化,又可以拆解为数据接口,数据报表,数据产品和数据大屏这 4 类,分别对应工程师(上下游系统)、分析师、业务运营/商家、媒体,这 4 种不同的用户。 在搞清楚了我们是谁以及我们的客户是谁这 2 个关键问题之后,下一个要解决的问题就是如何服务好他们,并在此基础上沉淀出一定的技术积累。...

在 react + redux 已经成为大部分前端项目底层架构的今天,让我们再回到软件工程界一个永恒的问题上来,那就是如何提升一个开发团队的开发效率? 从宏观的角度来讲,只有对具体业务的良好抽象才能真正提高一个团队的开发效率,又囿于不同产品所面临的不同业务需求,当我们抽丝剥茧般地将一个个前端项目抽象到最后一层,那么剩下的就只有按钮、输入框、对话框、图标等这些毫无业务意义的纯 UI 组件了。 选择或开发一套适合自己团队使用的 UI 组件库应该是每一个前端团队在底层架构达成共识后下一件就要去做的事情,那么我们就以今天为始,分别从以下几个方面来探讨如何构建一套优秀的 UI 组件库。 ## 第一个问题:选择开源 vs 自己造轮子 在 React 界,优秀且开源的 UI 组件库有很多,国外的如 [Material-UI](http://www.material-ui.com/),国内的如 [Ant Design](https://ant.design/),都是经过众多使用者检验,组件丰富且代码质量过硬的组件库。所以当我们决定再造一套 UI 组件库之前,不妨先尝试下这些在 UI 组件库界口碑良好的标品,再决定是否要进入这个看似简单实则困难重重的领域。 在这里,我们并不会去比较任何组件库之间的区别或优劣,但却可以从产品层面给出几个开发自有组...
在上篇[《重新设计 React 组件库》](https://github.com/AlanWei/blog/issues/1)中我们从宏观层面一起探讨了结构自由且数据解耦的 React 组件库应当如何设计,在本文中让我们从具体实践的角度来看如何将这样的设计落地。 ## 组件分类 在传统的组件库设计中,组件分类一直都不是一个必选项,大多数人都认为一个组件究竟是属于组件类还是控件类,不过是名字上的不同而已,并没有实际意义。但在将组件代码写法区分为纯函数与 ES6 class 两种之后,我们发现组件的写法同时也代表着组件的类型,这时就可以给予不同组件一个更清晰的定义,分别是: * 不含有内部状态的以纯函数写法表示的无交互的纯渲染组件 * 含有内部状态以 ES6 class 写法表示的有交互的智能控件 在进行了这样清晰的分类之后,每当我们需要新增一个组件时,我们都可以从是否含有内部状态,是否有交互等几个方面来将其纳入组件或控件,并以此来确定其相应的代码规范。 延伸来说,除了基础的组件与控件的区别之外,我们还推荐大家从业务的角度出发再划分出一种新的组件类型,即容器。 举例来说,在 [Material Design](https://material.io/guidelines/) 大行其道的今天,应该不会有人对**卡片**这样一种基础的内容展示形式感到陌生。对应到前端组件库中,作为展示内容的骨架,卡片本身应当是一个纯渲染组件,但在将其带入具体的业务场景中后就会发现,卡片本身其实是有状态的,常见的如数据加载中、数据为空、数据错误等。这样一个无交互但含有自身状态的组件无论归于上述的哪个分类都会让人感到奇怪,所以我们又引入了容器这样一个新的分类,专门用来存放卡片这类组件。看到这里,相信聪明的你应该能体会到组件分类的真正意义了,那就是用组件分类这样一种形式来强迫工程师去思考每一个组件的本质,然后再利用 pure render 等方法去优化组件性能。作为离用户最近的一批工程师,前端工程师所应该关心的,除了代码本身之外,用户体验,人机交互等领域方面的经验与知识,也是判断前端工程师是否优秀的另一把标尺。 另一方面来讲,我们又可以从容器组件延伸出强依赖数据的组件应当如何设计这样一个更加抽象的问题。从组件库设计的角度来讲,正如上一篇文章中所提到的,不建议将数据获取等逻辑放在组件里去做的。但结合业务场景来说,统一数据获取等逻辑确实是提升业务开发效率的不二选择,这方面的具体实践大家可以参考[琼玖](https://www.zhihu.com/people/xile611)之前的文章[《React实践 - Component...
放眼全球,中国整体的互联网技术实力毫无疑问仅次于美国并领先剩余所有的国家一大截。但如果我们非要找出一个中国互联网公司做得不够优秀的地方,那么产品国际化一定是其中之一。虽然我们也拥有诸如 AliExpress,天猫国际等成功案例,但不得不说大部分中国公司在选择出海后,都没有能够收获到与预期相匹配的回报。这其中原因自然很多,然而缺乏一套可以平台化,产品化的通用国际化方案一直都是其中一个非常重要的原因。 曾经笔者也天真地认为国际化不过是几个 json 文件的键值对匹配,但在深入了解了一些产品的国际化需求后,笔者才意识到要做一套好的国际化方案并没有那么简单。 ## 服务端国际化 对于前端工程师而言,国际化所要面临的第一个挑战就是,并不是所有的数据都可以在前端做国际化。常见的例子如电商类产品的货品或商家信息,这些都是有强更新需求,需要存储在后端数据库中,通过产品后台进行更新的。如果一个商品要销往美国,德国,法国,西班牙,泰国,印度尼西亚,而运营人员又只想维护一套以中文为基准的商品信息,那么这类数据的国际化我们就需要将其做在服务端。 我们当然可以麻烦后端工程师帮助我们根据每个请求的域名或 HTTP header 中的 `content-language` 来返回不同表中的翻译,但如果你是一位致力于向全栈方向发展的前端工程师,不妨可以尝试将国际化这一需求服务化,使用 Node.js 来封装一个国际化中间件,在每个请求返回前对其返回值进行翻译处理。 因为每个公司的技术架构不同,我们暂且略过技术细节不表。但我们需要知道的是,相较于前端国际化,后端接口的国际化其实更为关键与重要。因为这涉及到我们是否能将我们的核心数据以用户可理解的语言展现出来,而国际化也绝不仅仅是将几个字符串翻译为对应语言那样简单。 ## 哪些数据需要做国际化 在讨论具体的国际化方案之前,我们首先要明确一个问题,那就是产品中的哪些数据是需要做国际化的。 简而言之,除去后端返回的数据,所有在前端渲染的单词,语句,以及嵌套在其中的数据,都需要做相应的国际化。对应到代码层面,需要保证代码中没有任何一行硬编码的字符串与符号。不论是大到一个区块标题,还是小到一个确认按钮的文案,所有的展示信息都需要做国际化。 ## 键值对匹配与多语言支持 回到前端,让我们从最简单的国际化场景说起。 例如下拉列表输入框中的“选择”占位符,假设我们需要同时将其翻译为英文与法文,首先我们需要引入两个语言文件: ```javascript // en-US.json { "web_select":...
一个成熟的组件库通常都由数十个常用的 UI 组件构成,这其中既有按钮(Button),输入框(Input)等基础组件,也有表格(Table),日期选择器(DatePicker),轮播(Carousel)等自成一体的复杂组件。 这里我们提出一个**组件复杂度**的概念,一个组件复杂度的主要来源就是其自身的状态,即组件自身需要维护多少个不依赖于外部输入的状态。参考原先文章中提到过的木偶组件(dumb component)与智能组件(smart component),二者的区别就是是否需要在组件内部维护不依赖于外部输入的状态。 ## 实战案例 - 轮播组件 在本篇文章中,我们将以轮播(Carousel)组件为例,一步一步还原如何实现一个交互流畅的轮播组件。 ### 最简单的轮播组件 抛去所有复杂的功能,轮播组件的实质,实际上就是在一个固定区域实现不同元素之间的切换。在明确了这点后,我们就可以设计轮播组件的基础 DOM 结构为: ```jsx ... ``` 如下图所示:  `Frame` 即轮播组件的真实显示区域,其宽高为内部由使用者输入的 `SlideItem` 决定。这里需要注意的一点是需要设置 `Frame` 的 `overflow` 属性为 `hidden`,即隐藏超出其本身宽高的部分,每次只显示一个...
在即将发布的 React v16.3.0 中,React 引入了新的声明式的,可透传 props 的 [Context API](https://github.com/facebook/react/pull/11818),对于新版 Context API 还不太了解朋友可以看一下笔者之前的一个[回答](https://www.zhihu.com/question/267168180/answer/319754359)。 受益于这次改动,React 开发者终于拥有了一个官方提供的安全稳定的 global store,子组件跨层级获取父组件数据及后续的更新都不再成为一个问题。这让我们不禁开始思考,相较于 Redux 等其他的第三方数据(状态)管理工具,使用 Context API 这种 vanilla React 支持的方式是不是一个更好的选择呢? ## Context vs. Redux 在 react...
随着 Webpack 等前端构建工具的普及,客户端渲染因为其构建方便,部署简单等方面的优势,逐渐成为了现代网站的主流渲染模式。而在刚刚发布的 [React v16.0](https://reactjs.org/blog/2017/09/26/react-v16.0.html) 中,改进后更为优秀的服务端渲染性能作为六大更新点之一,被 React 官方重点提及。为此笔者还专门做了一个小调查,分别询问了二十位国内外(国内国外各十位)前端开发者,希望能够了解一下服务端渲染在使用 React 公司中所占的比例。 出人意料的是,十位国内的前端开发者中在生产环境使用服务端渲染的只有三位。而在国外的十位前端开发者中,使用服务端渲染的达到了惊人的八位。 这让人不禁开始思考,同是 React 的深度使用者,为什么国内外前端开发者在服务端渲染这个 React 核心功能的使用率上有着如此巨大的差别?在经过又一番刨根问底地询问后,真正的答案逐渐浮出水面,那就是可靠的 SEO(reliable SEO)。 相比较而言,国外公司对于 SEO 的重视程度要远高于国内公司,在这方面积累的经验也要远多于国内公司,前端页面上需要服务端塞入的内容也绝不仅仅是用户所看到的那些而已。所以对于国外的前端开发者来说,除去公司内部系统不谈,所有的客户端应用都需要做大量的 SEO 工作,服务端渲染也就顺理成章地成为了一个必选项。这也从一个侧面证明了国内外互联网环境的一个巨大差异,即虽然国际上也有诸如 Google,Facebook,Amazon 这样的巨头公司,但放眼整个互联网,这些巨头公司所产生的**黑洞效应**并没有国内 BAT 三家那样如此得明显,中小型公司依然有其生存的空间,搜索引擎所带来的自然流量就足够中小型公司可以活得很好。在这样的前提下,SEO 的重要性自然也就不言而喻了。 除去 SEO,服务端渲染对于前端应用的首屏加载速度也有着质的提升。特别是在...