652994331
652994331

Anyone tried chinese NER task? do we have a relative good result?
Hi, i started bert-as-service with -num_work=4. But i found the gpu usage of single machine's low(lower than 50%). So even i used 4 machines, the processing speed's still not fast....
我在使用下列的方式压缩模型的时候 出现了问题  pip install tensorflow==1.15 freeze_graph --input_checkpoint=./albert_model.ckpt \ --output_graph=/tmp/albert_tiny_zh.pb \ --output_node_names=cls/predictions/truediv \ --checkpoint_version=1 --input_meta_graph=./albert_model.ckpt.meta --input_binary=true 我去检查了下模型生成路径下的graph.pbtxt 里面的node 似乎没有这个cls/....... 我看到里面的node 量有很多, 不知道该用哪个 求助 谢谢
您好,在下游做的一个分类任务, 得到了.pb模型, 利用.pb模型搭建tfserving, ,服务的结果:传入一个单句,进行预测,产看预测时间,预测时间达到了200+ ms 之多, 想问问这个是什么原因
做了一些实验, 网络结构中加入了bilstm + crf , 使用albert_large 来做NER整体的表现要比bert 做NER差, 想问问有没有其他人做过NER任务, ALBERT 真的能做过bert 吗在这个任务上, 感觉试了很多,结果精度上都是Albert _large 不如bert_base 的, 想了解一下自己是不是哪里搞错了,似乎性能不能超越bert base。
albert large 我用batch 64 在我的机器上会有显存不够的问题. 我尝试过一些方式,比如梯度accumulation (多GPU), 调整gpu_fraction 到0.5 都不能解决问题呢,以下截图是我尝试把 gpu fraction 限定在0.5 的时候出现的错误信息: 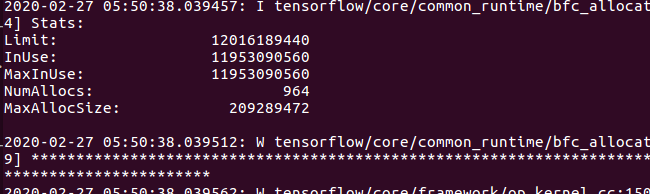 请问下大家有没有什么可行的解决方法, 谢谢
brightmart 你好, 最近看到google 也放出了他的中文预训练模型, 自己这边在尝试他的预训练large 模型的时候发现需要占用的资源很大,下游任务(finetune ) 基本不能使用比较适中的batch 比如32,64. 所以想问问可不可以用他的预训练模型 然后使用你这边的下游run_classifier来进行下游任务,谢谢
对比的结果 ,相同的pretrain 下, (使用公开的ner数据进行了相同步数的pretrain) 然后进行了相同数据,相同步数的finetune ,结果看起来 albert large 要bert 在PER LOC 上下降1% ORG上下降3%.
文档里提到 预训练xlarge 的时候 需要把batch 调的比较大, 否则效果会差, 现在用我们自己的数据在xslarge 模型基础上进行预训练的时候, batch 调大会导致OOM。 请问下这个要怎么解决呢
您好,我看到有两个Optimization? 默认的下游finetune 任务 run_classifier.py 里面用的optimization, 但是我看到还有一个Optimization_finetuneing? 这两个是怎么回事,下游finetune run_classifier的的时候到底该用哪一个呢?