Excessive memory consumption on backup of large repositories
What happened:
Running n3dr repositories --backup --directory-prefix /backup-to command inside an pod in OpenShift to backup Nexus3 with a number of large repositories causes excessive memory consumption. Possibly a memory leak. Setting GOMEMLIMIT enviroment variable doesn't affect memory consumption in any way.
A picture worth of a thousand words:
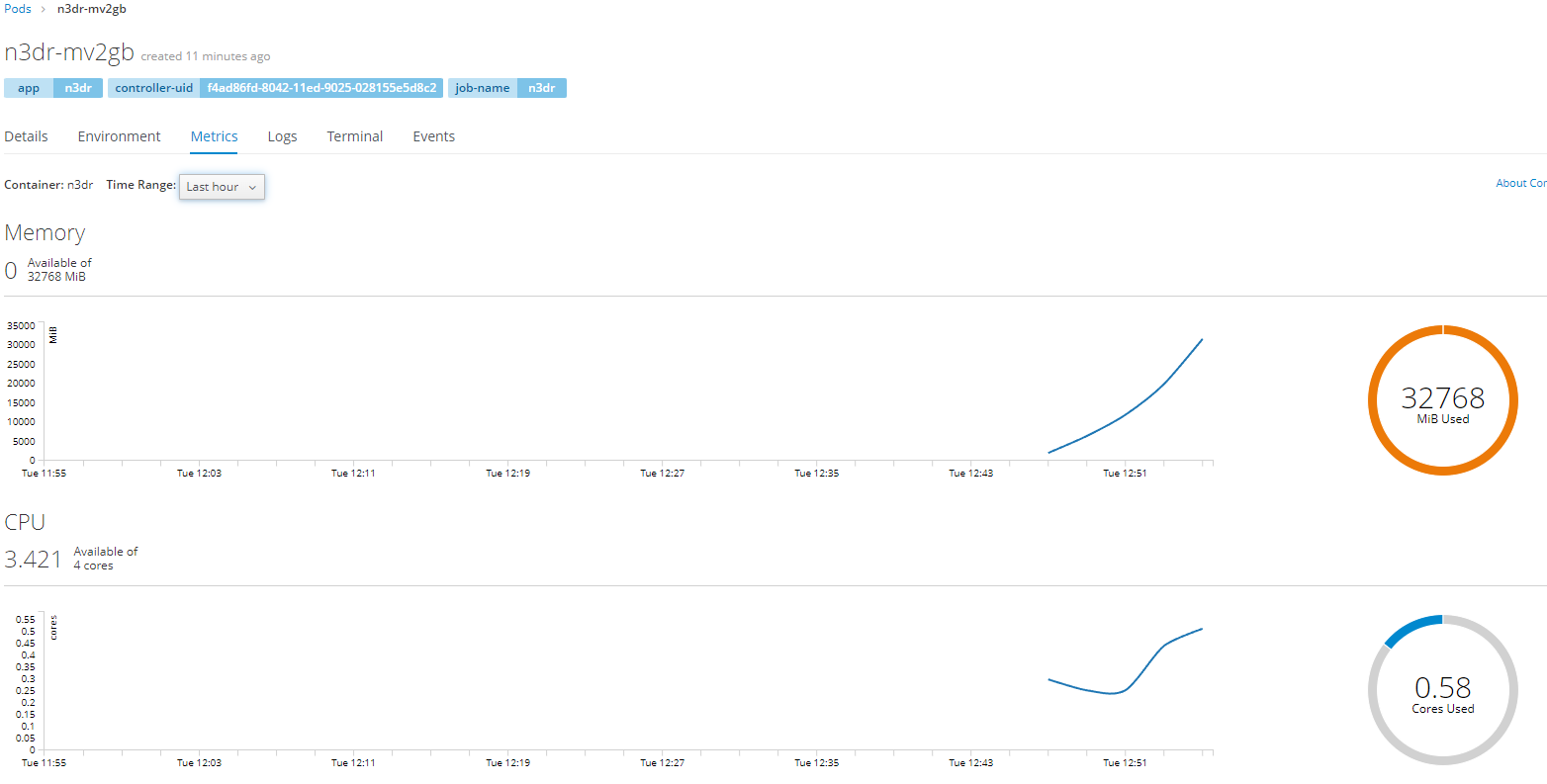
At first the n3dr pod was launched with 4Gi, then 8Gi, then 16Gi, and at last with 32Gi. The result is always the same - the pod is killed with OOM within a couple of hours (sometimes faster) leaving backup unfinished.
What you expected to happen: Reasonable memory consumption.
How to reproduce it (as minimally and precisely as possible): Not sure, but a Nexus3 repo with 250k-300k of blobs might do the trick.
Anything else we need to know?: The n3dr image in build from the 7.0.1 release code. Both Nexus3 pod and n3dr pod are placed in the same namespace, the Nexus3 RestAPI is accessed using local address (http://nexus:8081). The OpenShift is deployed onto AWS, the /backup-to folder is mapped to AWS EFS file system.
The Nexus3 instance has a lot of artifacts:
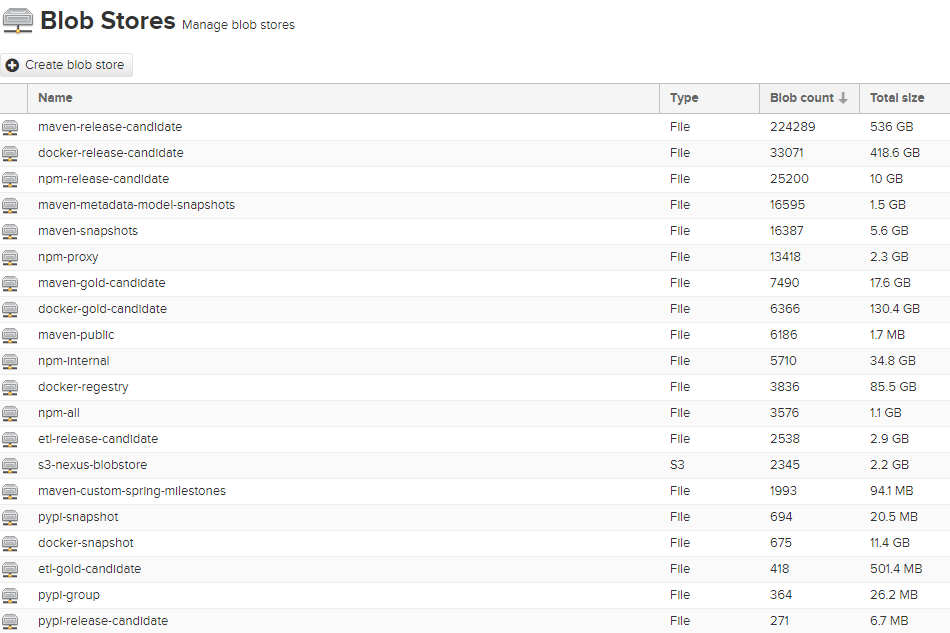
The Kubernetes resources are created with the following commands:
# create persistent volume through claim
cat <<EOF | kubectl apply -f -
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata: {name: n3dr-data, namespace: apps}
spec:
accessModes: [ReadWriteOnce]
resources:
requests:
storage: 1500Gi
storageClassName: efs
volumeMode: Filesystem
EOF
# place n3dr config.yml contents into a variable
config_yml=$(cat <<EOF | base64 -w0
---
n3drUser: admin
n3drPass: admin
n3drURL: http://nexus:8081
showLogo: false
EOF
)
# create a service account, a secret with config.yml and a job
cat <<EOF | kubectl apply -f -
---
apiVersion: v1
kind: List
items:
- apiVersion: v1
kind: ServiceAccount
metadata: {name: n3dr, namespace: apps}
- apiVersion: v1
kind: Secret
metadata: {name: n3dr-config, namespace: apps}
type: Opaque
data:
config.yml: >-
${config_yml}
- apiVersion: batch/v1
kind: Job
metadata: {labels: {app: n3dr}, name: n3dr, namespace: apps}
spec:
backoffLimit: 1
completions: 1
parallelism: 1
template:
metadata: {labels: {app: n3dr}, name: n3dr}
spec:
containers:
- name: n3dr
image: private-registry/n3dr:7.0.1
env:
- name: GOMEMLIMIT
value: 7GiB
command:
- sh
- '-c'
- 'n3dr repositories --backup --directory-prefix /backup-to'
imagePullPolicy: IfNotPresent
resources: {limits: {cpu: "4000m", memory: "32Gi"}}
volumeMounts:
- name: n3dr-config
mountPath: /.n3dr/config.yml
subPath: config.yml
- name: backup-to
mountPath: /backup-to
restartPolicy: Never
serviceAccount: n3dr
terminationGracePeriodSeconds: 36000
nodeSelector:
kubernetes.io/hostname: worker1.compute.internal
volumes:
- name: n3dr-config
secret:
secretName: n3dr-config
- name: backup-to
persistentVolumeClaim:
claimName: n3dr-data
EOF
Environment:
- nexus version: 3.15.0-01
- n3dr version (use
n3dr -v): 7.0.1 - OS (e.g:
cat /etc/os-release): CentOS Linux 7 (Core) - Kernel (e.g.
uname -a): Linux 5.4.228-1.el7.elrepo.x86_64 - Others: OpenShift 3.11 (Kubernetes 1.11)
@n-g-work Could you indicate how many repositories reside in the Nexus3 server and could you post some logging?
Number of repositories: 6 Size: 1.3GB
Without waitGroups: 31m28,351s With waitGroups: 5m47,063s Without waitGroupArtifacts: 19m23,357s Without waitGroupRepositories: 7m50,303s
@n-g-work Could you try to download the artifacts without waitGroups by using N3DR 7.0.2 in conjunction with the --withoutWaitGroups option and let us know the outcome?
@n-g-work Could you indicate how many repositories reside in the Nexus3 server and could you post some logging?
There's 58 repositories: 30 hosted, 19 proxy and 9 group. I'll try to get logs with the 7.0.2 and add them here.
@030, I'm sorry, I no longer have an access to the environment with the bloated Nexus, and I was not able to test the fix before loosing the access. Hence, it's now impossible (or hard enough to not go there) to reproduce it. I believe the issue can be closed.