mmpose
 mmpose copied to clipboard
mmpose copied to clipboard
OpenMMLab Pose Estimation Toolbox and Benchmark.

## Motivation To better use MMPose functionality. ## Modification It's a few lines modified to add more logger hooks to docs.
How well the model performs in occlusion scenario and tracking scenario?
## Motivation Integrate CID (CVPR2022) into mmpose. ## Modification Modify dataset to add 'bbox' and 'area' into db_rec Modify pipeline to support transformation of 'bbox' and add CID target generator...
您好! 我在使用[tools/dist_train.sh](https://github.com/open-mmlab/mmpose/blob/master/tools/dist_train.sh)训练voxelpose时,发现单卡、双卡和8卡DDP训练存在显卡数越多效果越差的现象,并且尝试是否打开选项autoscale_lr,结果打开autoscale_lr效果更差 :( config方面采用lr=0.0001(与voxelpose一致),batch_size=8 1.请问是否有其他地方我忽略了导致这个问题出现? 2.经过查阅资料发现,各卡之间独立计算BN可能是多卡精度下降的原因之一,请问我们mmpose中的分布式训练时同步BN需要手动设置还是自动进行? 【针对2 更新】尝试在build_norm_layer时选择SyncBN代替BN3d,精度有所恢复,但仍不及单卡效果 Hello! When I used tools/dist_train.sh to train voxelpose, I found that single-gpu, dual-gpu and 8-gpu DDP training has a phenomenon that the...
Hi, 请问下,如果我的coco json文件里不仅有 person的 id,还有 另外一种比如 袋鼠的id ,也就是说有两种需要检测的物体, 而且袋鼠也要检测它的大概10个的关键点,人的话还是coco的17个关键点,一共加起来27个关键点,但是 袋鼠和人不同的box id,那么paddle tinypose 支持这种json吗? 该怎么修改呢,有木有参考链接呢或者涉及哪些文件? 多谢多谢 BR
   _base_ = [ '../../../../_base_/default_runtime.py', '../../../../_base_/datasets/coco.py' ] evaluation = dict(interval=10, metric='mAP', save_best='AP') optimizer = dict( type='Adam', lr=5e-4, ) optimizer_config = dict(grad_clip=None) # learning policy lr_config = dict( policy='step',...
这个是报的错 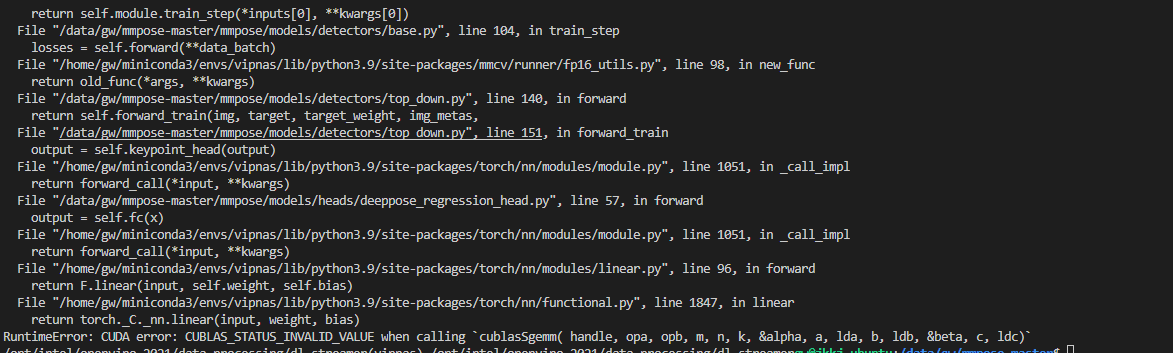 这个是配置文件的截图 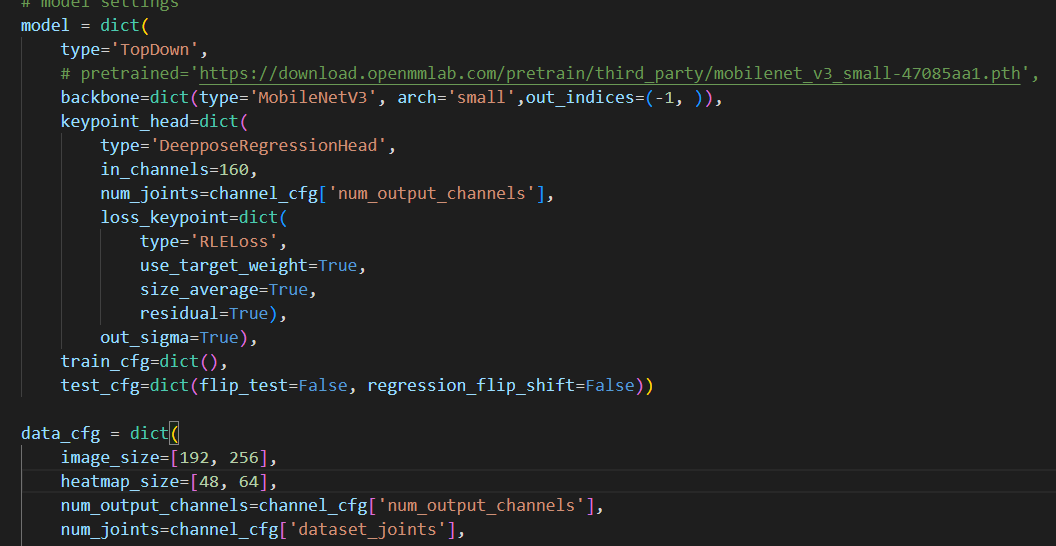 
Hi, I noticed that mmpose has a much better MPJPE than the InterHAnd 2.6M paper. For example, the single hand MPJPE for mmpose is 9.47, but in the paper it...
hi, 请问下 coco-wholebody 里面用到的zoomnet,完整识别133个关键点的模型,什么时候会发布出来呢? 是否有相关资料和mmpose代码链接分享下呢,多谢~~~ BR
Hello I have generated some output images and how can we output ground truth annotations for these images ? @ly015 Please suggest..
Metadata
Owner
Metadata
OpenMMLab Pose Estimation Toolbox and Benchmark.