Yi-Chen (Howard) Lo
### How to Tune Hyperparameters Gamma and C? (Response by Christopher P. Burgess) Gamma sets the strength of the penalty for deviating from the target KL, C. Here you want...
### Summary This paper purposes to train neural machine translation (NMT) model **from scratch** on both bilingual and target-side monolingual data in a multi-task setting by modifying the decoder in...
### Summary Neural text generation models are typically auto-regressive, trained via maximizing likelihood or perplexity and evaluate with validation perplexity. They claim such training and evaluation could result in poor...
### Summary This work can be viewed as a follow-up work on Rei (2017) #3, which porposes a semi-supervised framework for multi-task learning, integrating language modeling as an additional objective,...
### Summary This paper purpose a novel recurrent, attention and memory based neural architecture "Memory, Attention and Composition (MAC) cell" for VQA, featuring multi-step reasoning. Three operations in MAC cell:...
### TL;DR This papers identifies several key obstacles in machine learning research and gives some inspirations for machine learning research that matters, aiming to address the gap between research and...
### Summary This paper is the first group to successfully employ a fully convolutional Seq2Seq (Conv Seq2Seq) model (Gehring et al., 2017) on grammatical error correction (GEC) with some improvements:...
### Prior Approaches on Knowledge Distillation Basically, knowledge distillation aims to obtain a smaller student model from typically larger teacher model by matching their information hidden in the model. The...
### Metadata: Prime-Aware Adaptive Distillation - Author: Youcai Zhang, Zhonghao Lan, +4, Yichen Wei - Organization: Megvii Inc. & University of Science and Technology of China & Tongji University -...
### Highlights 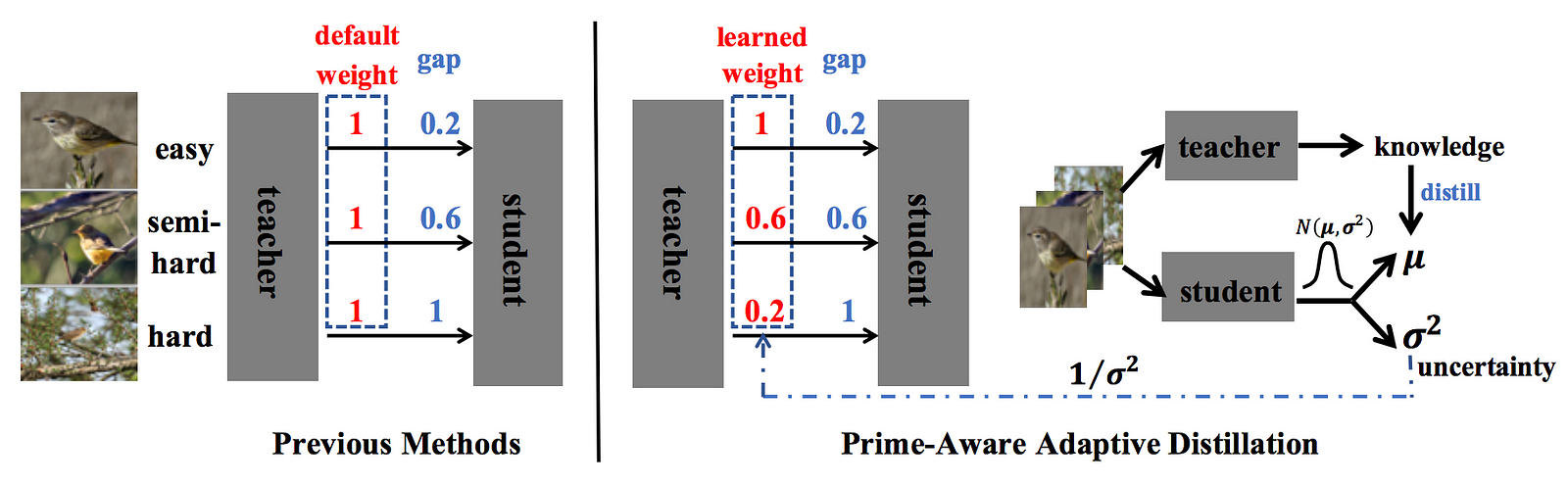 * This paper incorporates data uncertainty for re-weighting samples for distillation. * They conjecture that previous hard-mining (i.e., focus more on hard samples instead of easier ones)...