papernotes
 papernotes copied to clipboard
papernotes copied to clipboard
Auxiliary Objectives for Neural Error Detection Models
Metadata
- Authors: Marek Rei and Helen Yannakoudakis
- Organization: University of Cambridge
- Conference: BEA@EMNLP 2017
- Link: http://www.aclweb.org/anthology/W17-5004
Summary
This work can be viewed as a follow-up work on Rei (2017) #3, which porposes a semi-supervised framework for multi-task learning, integrating language modeling as an additional objective, while this work further extend the auxiliary objectives to token frequency, first language, error type, part-of-speech (POS) tags and syntactic dependency tags (grammatical relations). Also, auxiliary datasets (chunking, name entity recognition and POS-tagging) for different training strategies (pre-training v.s. multi-tasking) are investigated. The experiments shows that the auxiliary task of predicting POS+syntactic dependency tags gives a consistent improvement for error detection, and pre-training on auxiliary chunking dataset also improves.
Auxiliary Tasks
- Token Frequency: The frequency of a token w in the training corpus is discretized as int(log(freq(w)) and used as an auxiliary label. (Plank et al. 2017)
- Error Type: Grammatical error type (binary or fine-grained) from learner corpus.
- First Language: Whether the writing is from the first language (L1) learner.
- POS: Use RASP parser to generate POS tags for training data.
- Syntactic dependency: Again Use RASP parser to generate dependency tags for training data.
The task (cross-entropy loss) weights are [0.05, 0.1, 0.2, 0.5, 1.0] in respect to the above task order.
Error Detection Datasets
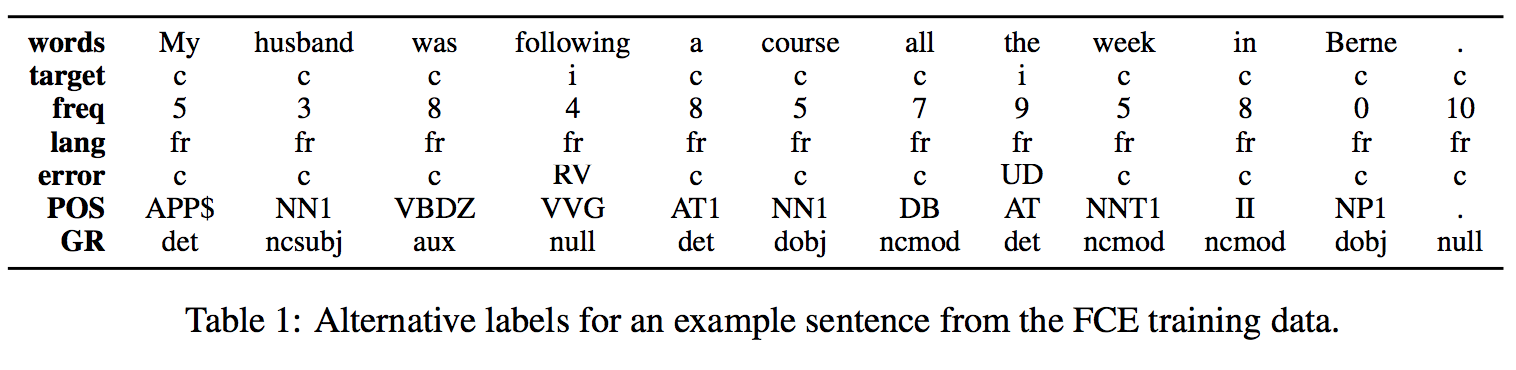
- The FCE dataset: For missing-word errors, the error label is assigned to the next word in the sequence. The released version contains 28,731 sentences for training, 2,222 sentences for development and 2,720 sentences for testing. The development set was randomly sampled from the training data, and the test set contains texts from a different examination year.
- The CoNLL-2014 test dataset (2 different annotations): Only for testing (the model is still trained on FCE).
Experimental Results on Different Auxiliary Tasks for Error Detection
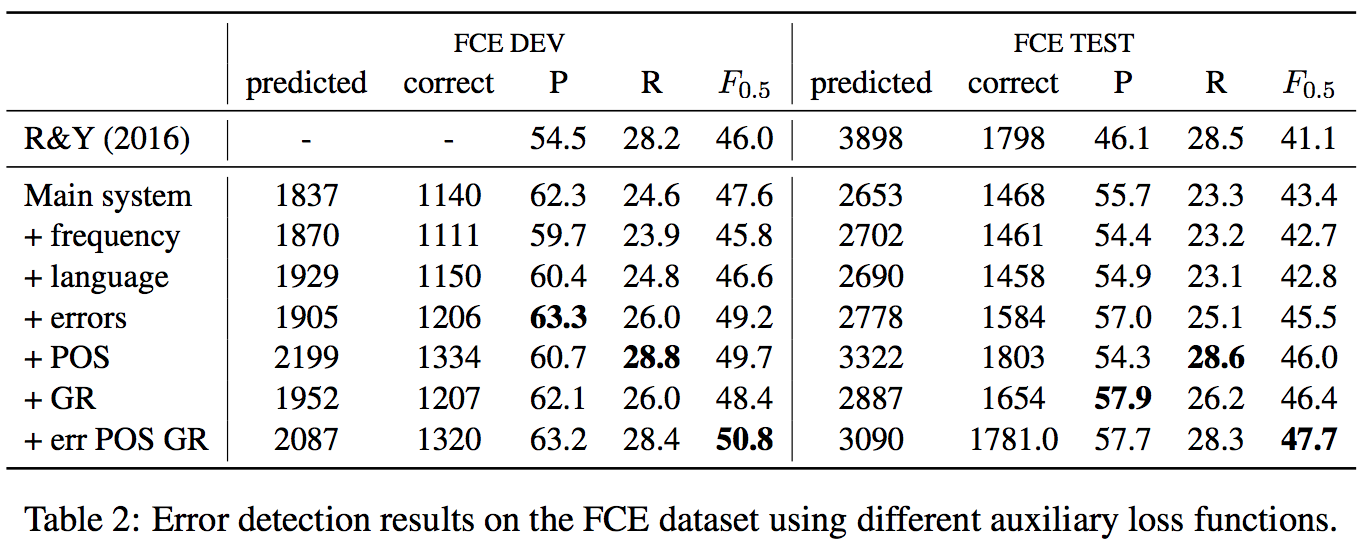
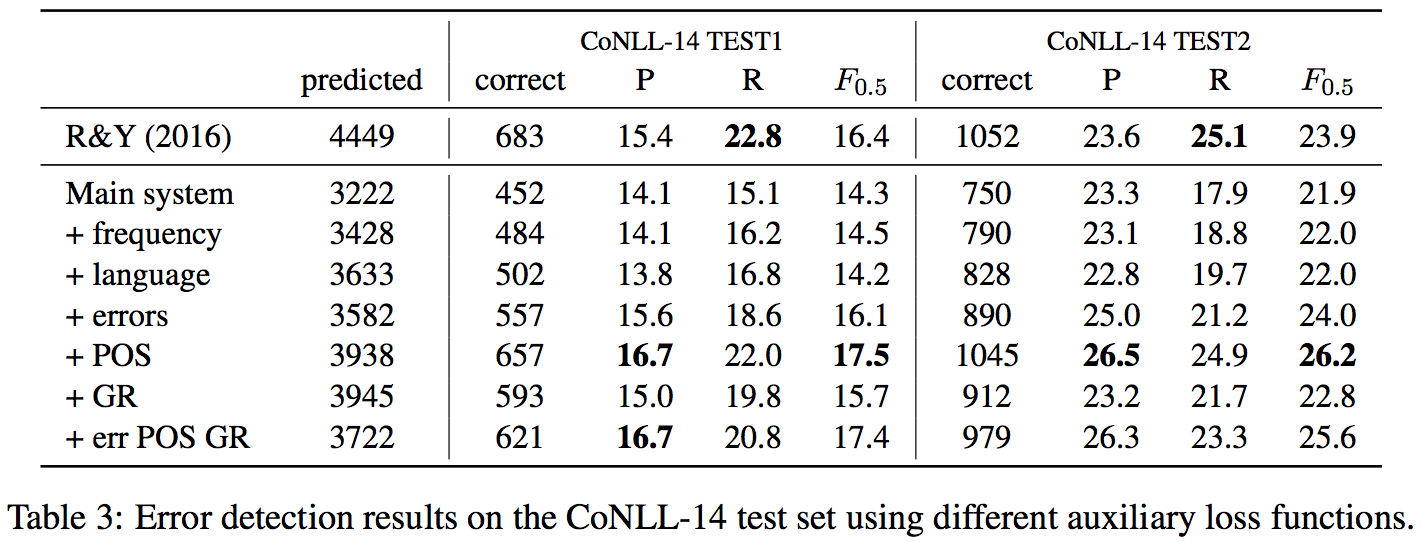
- For evaluation on FCE, the results shows that only predicting error types and syntactic dependency tags help improving performance. It's quite surprising that predicting syntactic dependency tags improves the most unexpectedly, although the syntactic dependency tags will probably incorrectly parsed given a grammatically erroneous sentences.
- But for the evaluation on CoNLL-2014, predicting error types and syntactic dependency tags seem not helping a lot like and even worse. Instead, predicting POS tags surprisingly becomes beneficial to error detection.
- In conclusion, different auxiliary tasks did not give a consistent improvements (only POS+dependency tags improves). Besides, the evaluation results varies on different test set, which cannot be clearly identified which auxiliary tasks really help to improve error detection.
Experimental Results on Different Training Strategies with Auxiliary Datasets
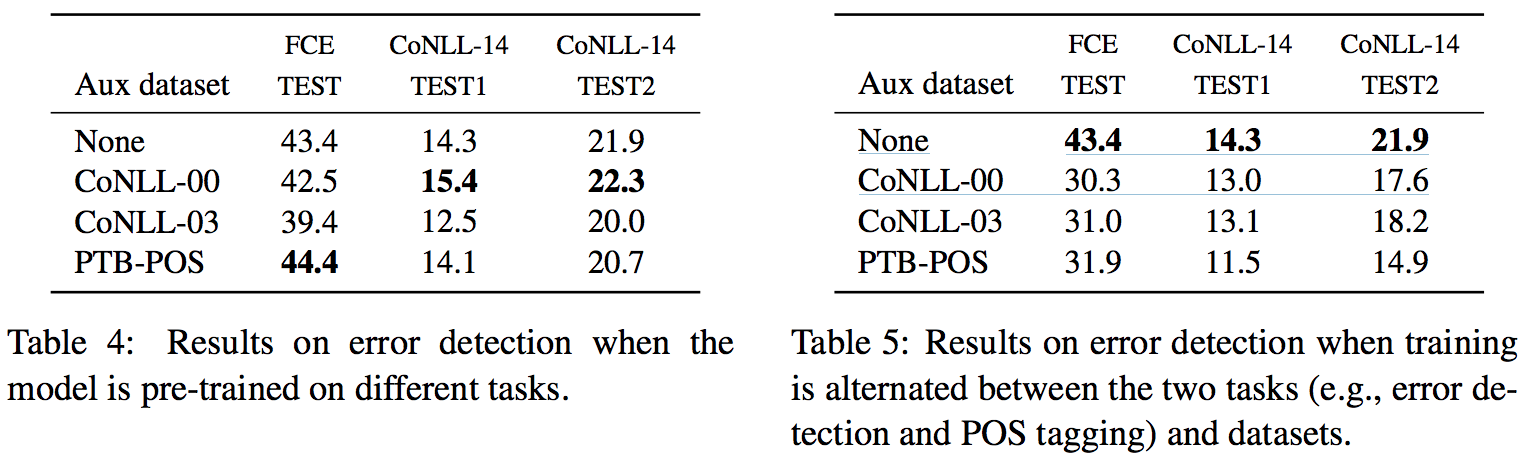
- The CoNLL-2000 dataset: For chunking, annotated with 22 different labels. Bingel and Søgaard (2017) as being the most useful additional training resource in a multi-task setting.
- The CoNLL-2003 dataset: For named entity recognition (NER), annotated with 8 different labels.
- The Penn Treebank (PTB) POS dataset: For POS-tagging, annotated with 48 POS tags.
- In the first strategy: Pre-train on each of these datasets and then fine-tune on error detection.
- In the second strategy: Jointly train on the second domain and task at the same time as error detection.
- The second strategy unsurprisingly hurts the main task's performance, since the domain and writing style of these auxiliary datasets is very different from the learner writing corpus. By including auxiliary labels on the same dataset, the model is able to extract more information from the domain-relevant training data and thereby achieve better results.
Additional Training Data
Trained on larger dataset on CLC, NUCLE and Lang-8 datasets (about 3 million parallel sentences I think...) with auxiliary POS-tagging task and tested on FCE and CoNLL-2014 test sets.
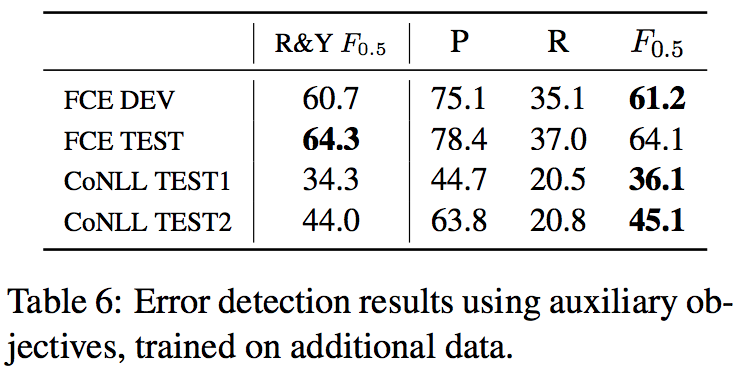
- No improvement on FCE test set, since FCE is one part of the CLC dataset. It is likely that the available training data is sufficient and the auxiliary objective does not offer an additional benefit.
- 1.8% and 1.1% absolute improvements on CoNLL-2014 test sets.
References
- Multilingual Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Models and Auxiliary Loss by Plank et al. (ACL 2017)
- Identifying beneficial task relations for multi-task learning in deep neural networks by Bingel and Søgaard. (EACL 2017)