ERNIE
 ERNIE copied to clipboard
ERNIE copied to clipboard
The official repository for ERNIE 4.5 and ERNIEKit – its industrial-grade development toolkit based on PaddlePaddle.
1. task_reader 里的 self.features_all 里面的特征只存了按 segment 切分的一遍特征,模型里好像没有看到哪里做了特殊处理,这个读两遍机制具体应该怎么实现啊? 2. memory 传递倒是看到了相关代码,可是没有看到同一个 query 不同 segment 之间 memory 的传递具体是怎么传的呢?是训练的时候手动判断文档是否结束,然后初始化 memory ? 3. Ernie3.0 好像编码方式和 ernie-doc 是一样的?如果是的话,Ernie3.0 能对超长文本做类似的操作吗?

-------------------------------------- C++ Traceback (most recent call last): -------------------------------------- 0 paddle_infer::Predictor::Predictor(paddle::AnalysisConfig const&) 1 std::unique_ptr paddle::CreatePaddlePredictor(paddle::AnalysisConfig const&) 2 paddle::AnalysisPredictor::Init(std::shared_ptr const&, std::shared_ptr const&) 3 paddle::AnalysisPredictor::PrepareProgram(std::shared_ptr const&) 4 paddle::framework::NaiveExecutor::CreateVariables(paddle::framework::ProgramDesc const&, int, bool, paddle::framework::Scope*) ----------------------...
Hello, I downloaded the model-ernie-m-large.tar.gz file to my computer, but when unzipping it shows that the archive is corrupt, why does that happen?
之前ernie2.0的时候是可以申请现在cpu和gpu版环境都配置好的docker镜像下载,ernie3.0也有吗
你好,我想借助你们的模型测试一下文本生成的效果,在下载了预训练模型和代码后,执行测试代码提示发现缺少“infer_data_params.json”文件,请问这个文件在哪里可以得到呢?谢谢! 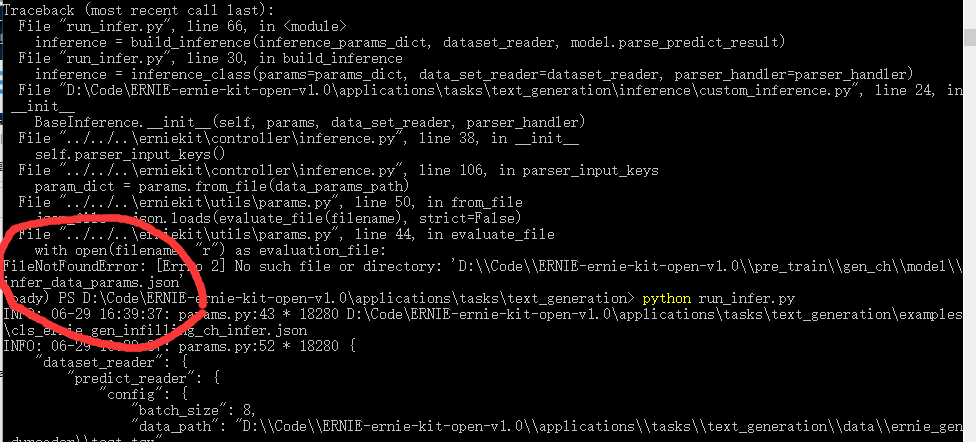
Hi developer in baidu, Thanks for the wonderful work. May I ask how many parameters are there in model such as ERNIE-SAT and ERNIE-ViL model? It seems hard to find...
predictor.run()刚开始运行执行时间短,越往后批次时间越长,每次比对8组文本对(batch_size=8),为啥越往后predictor.run()运行越慢,占用的内存没释放吗?导致后面越来越慢,这怎么解决?内存使用率99%,cpu使用率16%,卡死了比蜗牛还慢,每次predictor.run()(执行时间72s,380s,520s......执行时间越来越长) 调小batch_size(8=>4),内存使用率71%,cpu25%max_seq_len?predictor.run()(每次执行时间11s~12s基本固定),界面等其他操作正常不卡死 解决文本比对慢问题,调整batch_size,max_seq_len等参数能提高速度吗?还是需要修改ERNIE\applications\tasks\text_matching/inference/custom_inference.py代码?
1.目前实现:两个长文本分别切句后,按句子交叉比对(或组合成
Metadata
Owner
Metadata
The official repository for ERNIE 4.5 and ERNIEKit – its industrial-grade development toolkit based on PaddlePaddle.