mysql 证明为什么用limit时,offset很大会影响性能
首先说明一下MySQL的版本:
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.17 |
+-----------+
1 row in set (0.00 sec)
表结构:
mysql> desc test;
+--------+---------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------------+------+-----+---------+----------------+
| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment |
| val | int(10) unsigned | NO | MUL | 0 | |
| source | int(10) unsigned | NO | | 0 | |
+--------+---------------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
id为自增主键,val为非唯一索引。
灌入大量数据,共500万:
mysql> select count(*) from test;
+----------+
| count(*) |
+----------+
| 5242882 |
+----------+
1 row in set (4.25 sec)
我们知道,当limit offset rows中的offset很大时,会出现效率问题:
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (15.98 sec)
为了达到相同的目的,我们一般会改写成如下语句:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.38 sec)
时间相差很明显。
为什么会出现上面的结果?我们看一下select * from test where val=4 limit 300000,5;的查询过程:
- 查询到索引叶子节点数据。
- 根据叶子节点上的主键值去聚簇索引上查询需要的全部字段值。
类似于下面这张图:
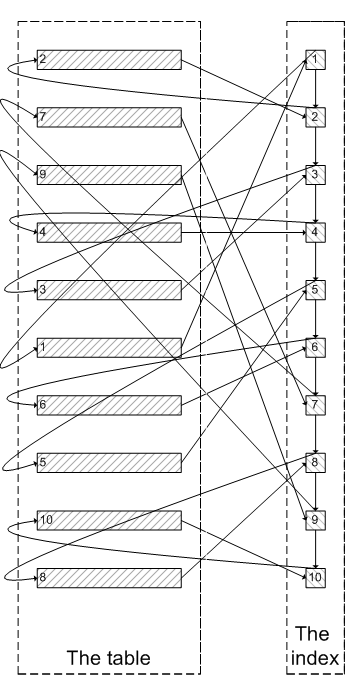
像上面这样,需要查询300005次索引节点,查询300005次聚簇索引的数据,最后再将结果过滤掉前300000条,取出最后5条。MySQL耗费了大量随机I/O在查询聚簇索引的数据上,而有300000次随机I/O查询到的数据是不会出现在结果集当中的。
肯定会有人问:既然一开始是利用索引的,为什么不先沿着索引叶子节点查询到最后需要的5个节点,然后再去聚簇索引中查询实际数据。这样只需要5次随机I/O,类似于下面图片的过程:
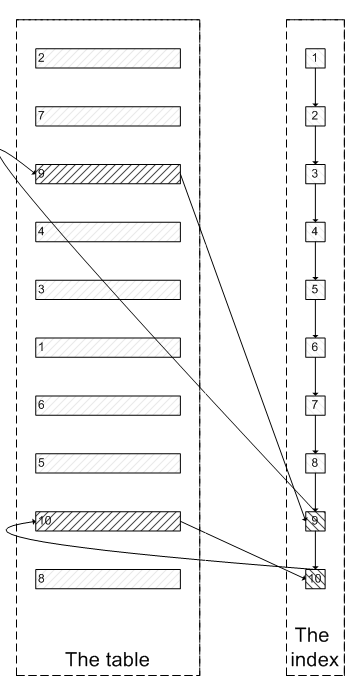
其实我也想问这个问题。
证实
下面我们实际操作一下来证实上述的推论:
为了证实select * from test where val=4 limit 300000,5是扫描300005个索引节点和300005个聚簇索引上的数据节点,我们需要知道MySQL有没有办法统计在一个sql中通过索引节点查询数据节点的次数。我先试了Handler_read_*系列,很遗憾没有一个变量能满足条件。
我只能通过间接的方式来证实:
InnoDB中有buffer pool。里面存有最近访问过的数据页,包括数据页和索引页。所以我们需要运行两个sql,来比较buffer pool中的数据页的数量。预测结果是运行select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;之后,buffer pool中的数据页的数量远远少于select * from test where val=4 limit 300000,5;对应的数量,因为前一个sql只访问5次数据页,而后一个sql访问300005次数据页。
select * from test where val=4 limit 300000,5
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.04 sec)
可以看出,目前buffer pool中没有关于test表的数据页。
mysql> select * from test where val=4 limit 300000,5;
+---------+-----+--------+
| id | val | source |
+---------+-----+--------+
| 3327622 | 4 | 4 |
| 3327632 | 4 | 4 |
| 3327642 | 4 | 4 |
| 3327652 | 4 | 4 |
| 3327662 | 4 | 4 |
+---------+-----+--------+
5 rows in set (26.19 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 4098 |
| val | 208 |
+------------+----------+
2 rows in set (0.04 sec)
可以看出,此时buffer pool中关于test表有4098个数据页,208个索引页。
select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id
为了防止上次试验的影响,我们需要清空buffer pool,重启mysql。
mysqladmin shutdown
/usr/local/bin/mysqld_safe &
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
Empty set (0.03 sec)
运行sql:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+---------+-----+--------+---------+
| id | val | source | id |
+---------+-----+--------+---------+
| 3327622 | 4 | 4 | 3327622 |
| 3327632 | 4 | 4 | 3327632 |
| 3327642 | 4 | 4 | 3327642 |
| 3327652 | 4 | 4 | 3327652 |
| 3327662 | 4 | 4 | 3327662 |
+---------+-----+--------+---------+
5 rows in set (0.09 sec)
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;
+------------+----------+
| index_name | count(*) |
+------------+----------+
| PRIMARY | 5 |
| val | 390 |
+------------+----------+
2 rows in set (0.03 sec)
我们可以看明显的看出两者的差别:第一个sql加载了4098个数据页到buffer pool,而第二个sql只加载了5个数据页到buffer pool。符合我们的预测。也证实了为什么第一个sql会慢:读取大量的无用数据行(300000),最后却抛弃掉。 而且这会造成一个问题:加载了很多热点不是很高的数据页到buffer pool,会造成buffer pool的污染,占用buffer pool的空间。
遇到的问题
- 为了在每次重启时确保清空buffer pool,我们需要关闭
innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup,这两个选项能够控制数据库关闭时dump出buffer pool中的数据和在数据库开启时载入在磁盘上备份buffer pool的数据。
参考资料:
欢迎大家关注我的知乎账号:https://www.zhihu.com/people/zhangyachen
或者可以关注下我的公众号,获得最及时的更新:

额,看来我讲的不清楚:sob: 在文中的情况下,inner join只会取limit pn,rn中的rn次数据页。而第一个sql会取pn + rn次数据页。 而取数据页是随机I/O,所以inner join的随机I/O少,比较快。
能用explain 看下两个sql的执行计划吗? 我猜测是select * from test where val=4 limit 300000,5; 执行过程中没有用到val字段的索引,导致检索的时候每行数据都取出来再进行比较。而mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;子查询中指定了id字段,所以执行计划是用到val索引,并且通过val索引的叶子节点上的主键值,再通过聚簇索引取出5行的所有字段。 求大神信息以及解释~
mysql> explain select * from test where val=4 limit 300000,5;
+----+-------------+-------+------------+------+---------------+------+---------+-------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+--------+----------+-------+
| 1 | SIMPLE | test | NULL | ref | val | val | 4 | const | 899712 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+--------+----------+-------+
1 row in set, 1 warning (0.01 sec)
mysql> explain select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+--------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 300005 | 100.00 | NULL |
| 1 | PRIMARY | a | NULL | eq_ref | PRIMARY | PRIMARY | 8 | b.id | 1 | 100.00 | NULL |
| 2 | DERIVED | test | NULL | ref | val | val | 4 | const | 899712 | 100.00 | Using index |
+----+-------------+------------+------------+--------+---------------+---------+---------+-------+--------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
select * from test where val=4 limit 300000,5;用到了索引,并且查一个索引节点查一次聚簇索引,往复300005次。
select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;覆盖索引,先查300005次索引节点,再利用最后5个索引节点的id查聚簇索引。
@linfasfasf
思考一天后,说一下我的理解,那个子查询快的原因主要是select的内容是索引,查找的内容是可以直接通过索引得到,是比较快的;没有子查询的那个select *的话虽然用到了索引,但是select了包含不是索引的内容,无法直接索引直接获得,是需要通过索引间接查找相关的内容。 两者的区别在于一个是通过索引直接得到索引内容,一个是通过索引间接得到内容,虽然都用到了索引,但获取索引外的其他内容还需要再通过索引查找一遍。
看完这两篇文章,大致就能理解楼主说的东西了
Mysql聚簇索引和索引覆盖
一、myisam与innodb引擎索引文件的异同:
1.myisam中, 主索引和次索引都指向物理行(磁盘位置);
2.innodb的主索引文件上,直接存放该行数据,称为聚簇索引,次索引指向对主键的引用;
注意: innodb来说
1.主键索引既存储索引值,又在叶子中存储行的数据
2.如果没有主键,则会Unique key做主键
3.如果没有unique,则系统生成一个内部的rowid做主键
4.像innodb中主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为“聚簇索引”
聚簇索引优劣:
优势: 根据主键查询条目比较少时,不用回行(数据就在主键节点下)
劣势: 如果碰到不规则数据插入时,造成频繁的页分裂,插入速度变慢
高性能索引策略 :对于innodb而言,因为节点下有数据文件,因此节点的分裂将会比较慢。因此对于innodb的主键尽量用整型,而且是递增的整型,如果是无规律的数据,将会产生的页的分裂,影响速度。
二、索引覆盖:
索引覆盖:是指如果查询的列恰好是索引的一部分,那么查询只需要在索引文件上进行,不需要回行到磁盘再找数据,这种查询速度非常快,这个现象称为“索引覆盖”。
三、索引覆盖实验:
create table A {
id varchar(64) primary key,
ver int,
...
}
条件:在id、ver上有联合索引,表中有几个很长的字段,总共100000条数据
问题:为什么select id from A order by id特别慢?而select id from A order by id,ver特别快?
原因:
1.如果是myisam引擎的话,会将id和ver都存放在索引文件中,所以order by id和order by id,ver不会出现速度上的差别,两次都产生索引覆盖,所以判断引擎为innodb;
2.由于innodb是聚簇索引,主索引id文件上,存放了该行的数据,当表中某个字段的数据很大时,在硬盘上一个数据块所能存放的行数就变少,所以数据块变多。当order by id时,会扫描很多个不同的数据块,导致性能降低。而order by id,ver为联合索引(次索引),次索引不用扫描很大的数据量,并且只筛选id,产生索引覆盖,所以速度快很多。
实验步骤:
1.首先查看是否开启profiling功能:SHOW VARIABLES LIKE '%pro%';
2.开启profiling:SET profiling=1;
3.查看sql语句执行结果:SHOW profiles;
4.建立数据表:
CREATE TABLE t7 (
id char(64) NOT NULL,
ver int(11) NOT NULL DEFAULT '0',
str1 varchar(3000) DEFAULT NULL,
str2 varchar(3000) DEFAULT NULL,
str3 varchar(3000) DEFAULT NULL,
PRIMARY KEY (id),
KEY idver (id,ver)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE t8 (
id char(64) NOT NULL,
ver int(11) NOT NULL DEFAULT '0',
str1 varchar(3000) DEFAULT NULL,
str2 varchar(3000) DEFAULT NULL,
str3 varchar(3000) DEFAULT NULL,
PRIMARY KEY (id),
KEY idver (id,ver)
) ENGINE=innodb DEFAULT CHARSET=utf8;
5.创建php文件批量插入数据:
$mysqli = new mysqli("127.0.0.1", "root", "", "test");
$mysqli->query("set names utf8");
$str = str_repeat('m', 3000);
for ($i=1;$i<=10000;$i++) {
$id = dechex($i);
$sql = sprintf("insert into t8 values ('%s',%d,'%s','%s','%s')", $i,$i,$str,$str,$str);
$mysqli->query($sql);
}
echo "insert success";
$mysqli->close();
?>
6.分别执行t7和t8,查看sql语句执行结果:
作者:杍劼 链接:http://www.jianshu.com/p/e110359bd29a 來源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
肯定会有人问:既然一开始是利用索引的,为什么不先沿着索引叶子节点查询到最后需要的5个节点,然后再去聚簇索引中查询实际数据。这样只需要5次随机I/O,类似于下面图片的过程
对呀,为什么mysql要做这300000次无意义的随机I/O,好奇葩
你好 总感觉不应该这样啊 现在mysql版本都这么高了 还没有修复 early row lookup的问题吗 ? https://explainextended.com/2009/10/23/mysql-order-by-limit-performance-late-row-lookups/
这是09年写的帖子 而且用的不是innodb的引擎
但是你用的5.7版本 而且是 innodb引擎 接近10年的时间了 mysql 还没有修复 early row lookup的问题吗?总感觉不对呢
你好 总感觉不应该这样啊 现在mysql版本都这么高了 还没有修复 early row lookup的问题吗 ? https://explainextended.com/2009/10/23/mysql-order-by-limit-performance-late-row-lookups/ 这是09年写的帖子 而且用的不是innodb的引擎 但是你用的5.7版本 而且是 innodb引擎 接近10年的时间了 mysql 还没有修复 early row lookup的问题吗?总感觉不对呢
可是貌似真的是这样,,, @javakinglzh
楼主能想到查看information_schema下的innodb_buffer表真的很赞。 但是有一个问题没明白: 这是第一次查询的val索引读取了208个page,但是第二次查询的val索引读取了390个page 这个两个数值不应该是一样的吗?为什么第二次val索引读取的索引页还多了呢,是因为第一次查询的时候buffer_pool中存在了一些page的缓存吗?
@zhangyachen 我按你的步骤测试了一下,可结果和你的不同,感觉其实还是能用到索引的
version 5.7.16-enterprise-commercial-advanced

select count(*) from test; 5000001 select * from test where val=4 limit 300000,5
OK Time: 0.034s
explain:
id select_type table type key key_len ref row filtered 1 SIMPLE test ref val val 5 const 1 100.00
