Why using validation in DIS and not in U2Net
Hello ! Thank you for the paper, really liked it :)
I'm wondering why you decided to monitor validation metrics while training DIS since you didn't do it for U2Net ? Is there a specific reason to that ?
Thanks
Hi, thanks for your email.
That is a good question. The reason of "not using validation" in U^2-Net is that the datasets, e.g., DUTS, SOD, ECSSD, DUT-OMRON, PASCAL and so on, are created by other different teams and they didn't provide the validation set, e.g., DUTS. We actually did try using MSRA2K as the validation set of our U^2-Net, but we found better validation accuracy doesn't necessarily lead to better test accuracy on different testing datasets probably because the distributions of the datasets created by different teams are very different. In our DIS paper, we created a new dataset from scratch and we do have the opportunities to balance the subsets for training, validation and testing. So we use the valid set there. Actually, to my experience, the dense prediction task on large dataset are usually ok with validation direction on your testing (ALTHOUGH which may be blamed by some one). Because we found that the models which perform better on these close datasets are usually also perform better on the open application scenarios as well. So it is better to have a comprehensive validation set. But without using that doesn't necessaries lead to BAD OVERFITTING because all most every deep model is "overfitting" on the training set nowadays. The difference for causing the performance variations are their "WAY" of "OVERFITTING".
BR, Xuebin
On Thu, Nov 24, 2022 at 7:32 AM AurelMR @.***> wrote:
Hello ! Thank you for the paper, really liked it :)
I'm wondering why you decided to monitor validation metrics while training DIS since you didn't do it for U2Net ? Is there a specific reason to that ?
Thanks
— Reply to this email directly, view it on GitHub https://github.com/xuebinqin/DIS/issues/60, or unsubscribe https://github.com/notifications/unsubscribe-auth/ADSGORKKCHIYQ76VJOGBLWLWJ6C7VANCNFSM6AAAAAASKQUOAA . You are receiving this because you are subscribed to this thread.Message ID: @.***>
-- Xuebin Qin PhD Department of Computing Science University of Alberta, Edmonton, AB, Canada Homepage: https://xuebinqin.github.io/
Thanks a lot for your answer !
I implemented the validation step for U2Net and I end up with something like that:
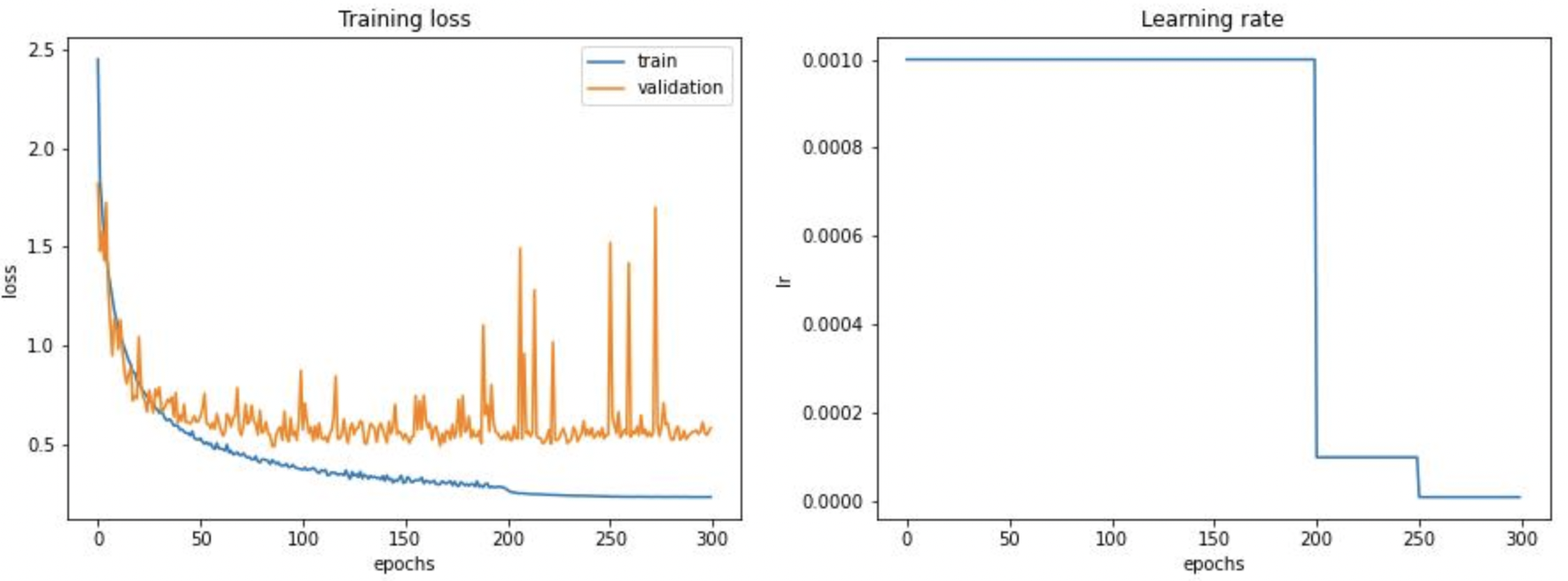
The training set size is 18K images and the validation size is only 400 images. I wonders if the validation loss curve looks this way because of the very small size of the dataset or if there is other reasons behind this.
Also I use Adam optimizer like you did in your experiments except that I decreased the learning rate to 1e-4 after 200 epochs and to 1e-5 after 250 epochs.
If anyone has an idea of why the validation loss curve looks the way it does, I'm all ears :)
Thank you again @xuebinqin for your answer and happy new Year !