articles
 articles copied to clipboard
articles copied to clipboard
基于protobuf构建fuzzer(libpng)
基于protobuf构建fuzzer(libpng)
前段时间谷歌出了个文章Structure-Aware Fuzzing with libFuzzer,其中说到了利用protobuf来构建fuzzer来fuzzing libpng库,并且给出了现成的libpng-proto的测试样例代码。
中文目前没有搜到如何利用这种方式来写fuzzer的文章,
所以自己就分析一下这种构建fuzzer的方法,作为一个fuzzing小白就当学习了
文章主要通过三步来完成整个fuzzing过程
1. protobuf简单介绍
2. 利用protobuf构建png数据
3. 利用libfuzzer引擎测试生成的数据
protobuf简介
Protocol Buffers(简称Protobuf) ,是Google出品的序列化框架,与开发语言无关,和平台无关,具有良好的可扩展性。Protobuf和所有的序列化框架一样,都可以用于数据存储、通讯协议。
废话不多说,直接上测试案例,简化一下官方给的例子测试一下test.proto,其中定义了一个Person的数据结构
syntax = "proto2";
package tutorial;
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
}
编译
protoc --cpp_out=./ ./test.proto
生成
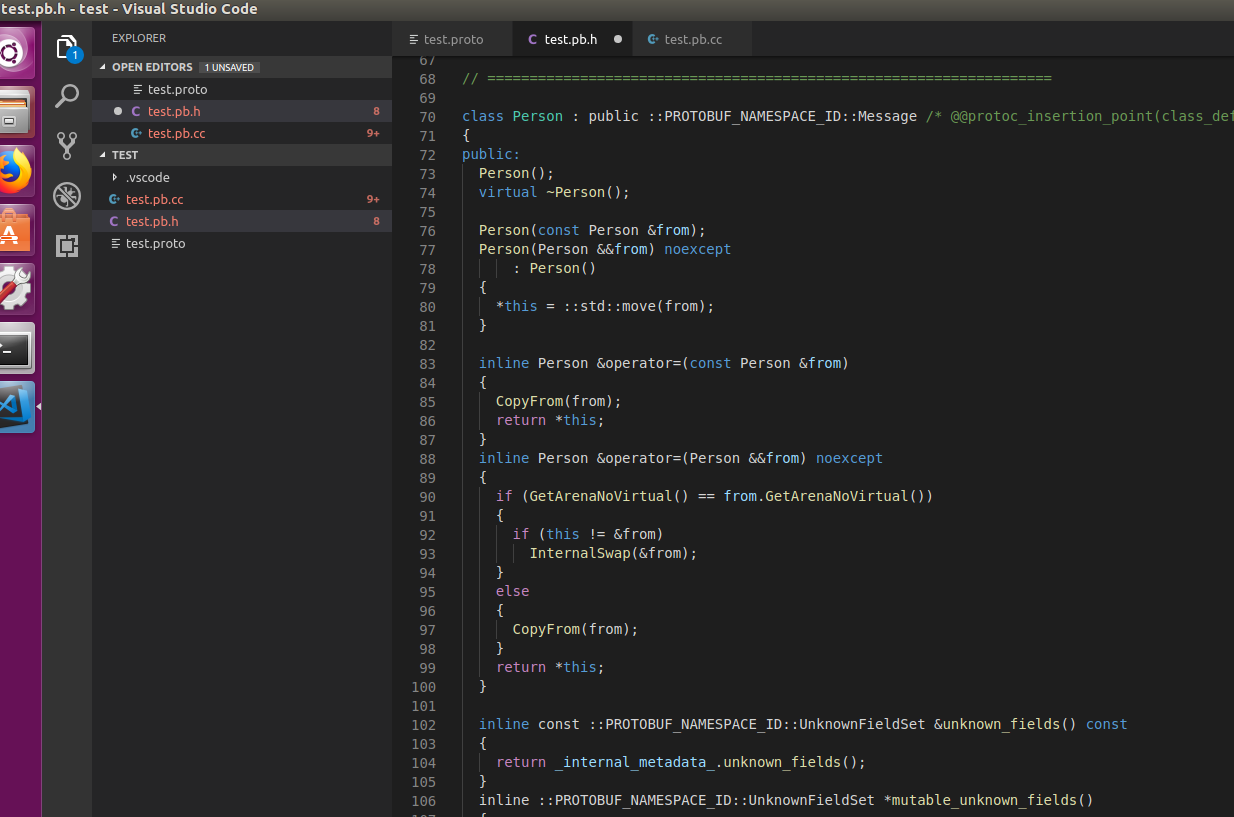
其实就是protobuf定义数据结构,之后通过编译器生成特定类型数据结构比如c++/python/php等
利用protobuf构建png数据结构
首先来看一下png图片的数据结构
+------------+
| 署名域 |
+------------+
| IHDR |
+------------+
| IDATs/other|
+------------+
| IEND |
+------------+
来看一下官方文档给的结构
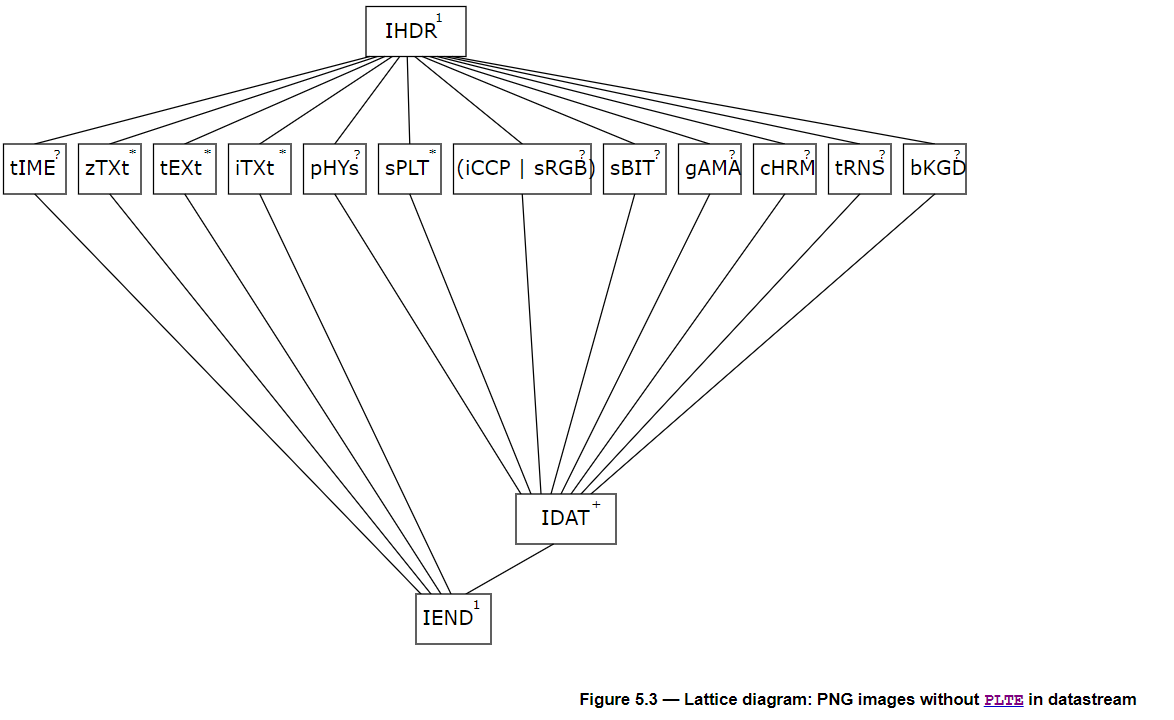
结构1
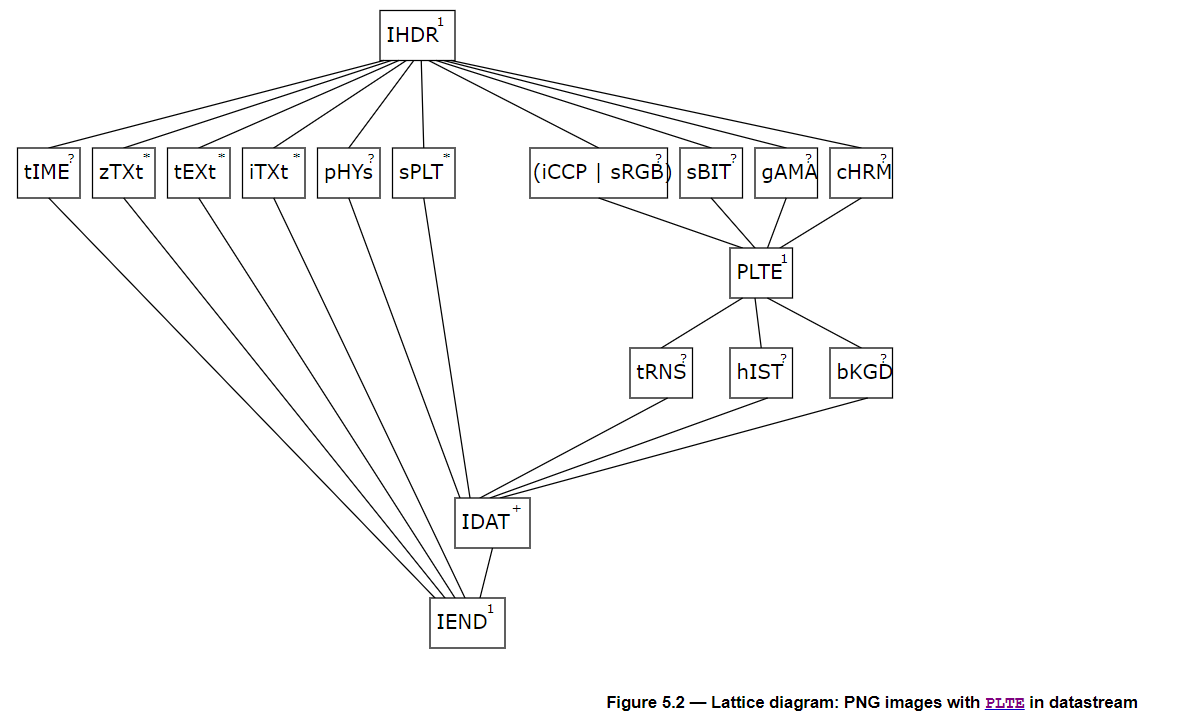
结构2
再来看看谷歌给出的proto
syntax = "proto2";
// Very simple proto description of the PNG format,
// described at https://en.wikipedia.org/wiki/Portable_Network_Graphics
message IHDR {
required uint32 width = 1;
required uint32 height = 2;
required uint32 other1 = 3;
required uint32 other2 = 4; // Only 1 byte used.
}
message PLTE {
required bytes data = 1;
}
message IDAT {
required bytes data = 1;
}
message iCCP {
required bytes data = 2;
}
message OtherChunk {
oneof type {
uint32 known_type = 1;
uint32 unknown_type = 2;
}
required bytes data = 3;
}
message PngChunk {
oneof chunk {
PLTE plte = 1;
IDAT idat = 2;
iCCP iccp = 3;
OtherChunk other_chunk = 10000;
}
}
message PngProto {
required IHDR ihdr = 1;
repeated PngChunk chunks = 2;
}
// package fuzzer_examples;
基本简单囊括了两种结构,现在来编译生成
protoc --cpp_out=./ ./png_fuzz_proto.proto
结果
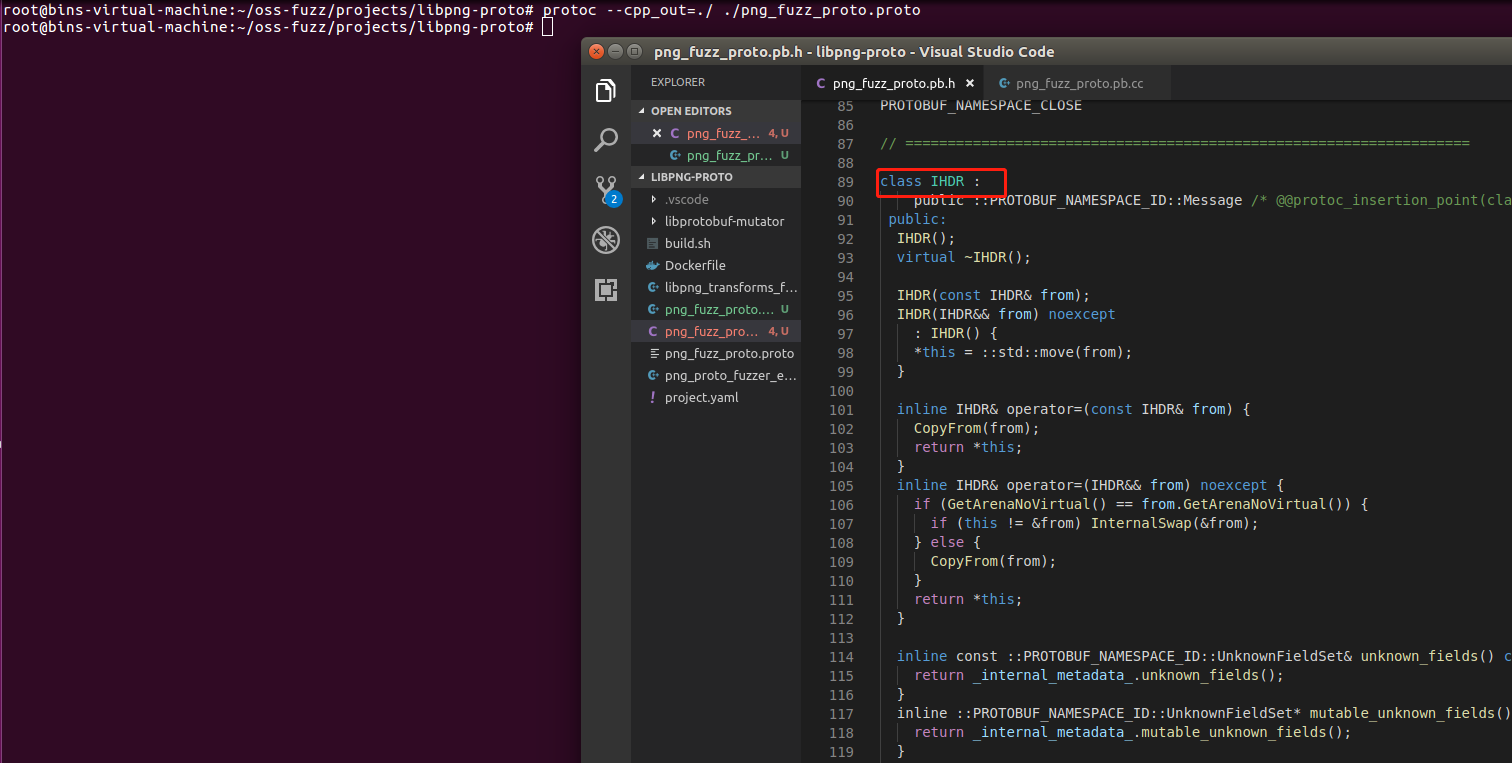
使用libfuzzer+protobuf进行fuzzing
现在利用protobuf生成了png构成的数据结构,现在需要做的大概可以分为两部分
1. 读取png数据并利用protobuf读取并做更改
2. 利用libfuzzer引擎做fuzzing测试
其实第一部分,我个人理解就是在自己写一个整套fuzzer了,来看看具体操作
// Chunk is written as:
// * 4-byte length
// * 4-byte type
// * the data itself
// * 4-byte crc (of type and data)
static void WriteChunk(std::stringstream &out, const char *type,
const std::string &chunk, bool compress = false)
{
std::string compressed;
const std::string *s = &chunk;
if (compress)
{
compressed = Compress(chunk);
s = &compressed;
}
uint32_t len = s->size();
uint32_t crc = crc32(crc32(0, (const unsigned char *)type, 4),
(const unsigned char *)s->data(), s->size());
WriteInt(out, len);
out.write(type, 4);
out.write(s->data(), s->size());
WriteInt(out, crc);
}
// 将proto 做更改后转化为png数据
std::string ProtoToPng(const PngProto &png_proto)
{
std::stringstream all;
const unsigned char header[] = {0x89, 0x50, 0x4e, 0x47, 0x0d, 0x0a, 0x1a, 0x0a};
all.write((const char *)header, sizeof(header));
std::stringstream ihdr_str;
auto &ihdr = png_proto.ihdr();
// Avoid large images.
// They may have interesting bugs, but OOMs are going to kill fuzzing.
uint32_t w = std::min(ihdr.width(), 4096U);
uint32_t h = std::min(ihdr.height(), 4096U);
WriteInt(ihdr_str, w);
WriteInt(ihdr_str, h);
WriteInt(ihdr_str, ihdr.other1());
WriteByte(ihdr_str, ihdr.other2());
WriteChunk(all, "IHDR", ihdr_str.str());
// 写入各个chunk
for (size_t i = 0, n = png_proto.chunks_size(); i < n; i++)
{
auto &chunk = png_proto.chunks(i);
if (chunk.has_plte())
{
WriteChunk(all, "PLTE", chunk.plte().data());
}
else if (chunk.has_idat())
{
WriteChunk(all, "IDAT", chunk.idat().data(), true);
}
else if (chunk.has_iccp())
{
std::stringstream iccp_str;
iccp_str << "xyz"; // don't fuzz iCCP name field.
WriteByte(iccp_str, 0);
WriteByte(iccp_str, 0);
auto compressed_data = Compress(chunk.iccp().data());
iccp_str.write(compressed_data.data(), compressed_data.size());
WriteChunk(all, "iCCP", iccp_str.str());
}
else if (chunk.has_other_chunk())
{
auto &other_chunk = chunk.other_chunk();
char type[5] = {0};
if (other_chunk.has_known_type())
{
static const char *known_chunks[] = {
"bKGD",
"cHRM",
"dSIG",
"eXIf",
"gAMA",
"hIST",
"iCCP",
"iTXt",
"pHYs",
"sBIT",
"sPLT",
"sRGB",
"sTER",
"tEXt",
"tIME",
"tRNS",
"zTXt",
"sCAL",
"pCAL",
"oFFs",
};
size_t known_chunks_size =
sizeof(known_chunks) / sizeof(known_chunks[0]);
size_t chunk_idx = other_chunk.known_type() % known_chunks_size;
memcpy(type, known_chunks[chunk_idx], 4);
}
else if (other_chunk.has_unknown_type())
{
uint32_t unknown_type_int = other_chunk.unknown_type();
memcpy(type, &unknown_type_int, 4);
}
else
{
continue;
}
type[4] = 0;
WriteChunk(all, type, other_chunk.data());
}
}
WriteChunk(all, "IEND", "");
std::string res = all.str();
if (const char *dump_path = getenv("PROTO_FUZZER_DUMP_PATH"))
{
// With libFuzzer binary run this to generate a PNG file x.png:
// PROTO_FUZZER_DUMP_PATH=x.png ./a.out proto-input
std::ofstream of(dump_path);
of.write(res.data(), res.size());
}
return res;
}
到这里第一部分,即fuzzer部分算是完成了,现在缺少的是使用libfuzzer进行fuzzing的代码
#define PNG_INTERNAL
#include "png.h"
#define PNG_CLEANUP \
if(png_handler.png_ptr) \
{ \
if (png_handler.row_ptr) \
png_free(png_handler.png_ptr, png_handler.row_ptr); \
if (png_handler.end_info_ptr) \
png_destroy_read_struct(&png_handler.png_ptr, &png_handler.info_ptr,\
&png_handler.end_info_ptr); \
else if (png_handler.info_ptr) \
png_destroy_read_struct(&png_handler.png_ptr, &png_handler.info_ptr,\
nullptr); \
else \
png_destroy_read_struct(&png_handler.png_ptr, nullptr, nullptr); \
png_handler.png_ptr = nullptr; \
png_handler.row_ptr = nullptr; \
png_handler.info_ptr = nullptr; \
png_handler.end_info_ptr = nullptr; \
}
struct BufState {
const uint8_t* data;
size_t bytes_left;
};
struct PngObjectHandler {
png_infop info_ptr = nullptr;
png_structp png_ptr = nullptr;
png_infop end_info_ptr = nullptr;
png_voidp row_ptr = nullptr;
BufState* buf_state = nullptr;
~PngObjectHandler() {
if (row_ptr)
png_free(png_ptr, row_ptr);
if (end_info_ptr)
png_destroy_read_struct(&png_ptr, &info_ptr, &end_info_ptr);
else if (info_ptr)
png_destroy_read_struct(&png_ptr, &info_ptr, nullptr);
else
png_destroy_read_struct(&png_ptr, nullptr, nullptr);
delete buf_state;
}
};
void user_read_data(png_structp png_ptr, png_bytep data, size_t length) {
BufState* buf_state = static_cast<BufState*>(png_get_io_ptr(png_ptr));
if (length > buf_state->bytes_left) {
png_error(png_ptr, "read error");
}
memcpy(data, buf_state->data, length);
buf_state->bytes_left -= length;
buf_state->data += length;
}
static const int kPngHeaderSize = 8;
// Entry point for LibFuzzer.
// Roughly follows the libpng book example:
// http://www.libpng.org/pub/png/book/chapter13.html
extern "C" int LLVMFuzzerTestOneInput(const uint8_t* data, size_t size) {
if (size < kPngHeaderSize) {
return 0;
}
std::vector<unsigned char> v(data, data + size);
if (png_sig_cmp(v.data(), 0, kPngHeaderSize)) {
// not a PNG.
return 0;
}
PngObjectHandler png_handler;
png_handler.png_ptr = nullptr;
png_handler.row_ptr = nullptr;
png_handler.info_ptr = nullptr;
png_handler.end_info_ptr = nullptr;
png_handler.png_ptr = png_create_read_struct
(PNG_LIBPNG_VER_STRING, nullptr, nullptr, nullptr);
if (!png_handler.png_ptr) {
return 0;
}
png_handler.info_ptr = png_create_info_struct(png_handler.png_ptr);
if (!png_handler.info_ptr) {
PNG_CLEANUP
return 0;
}
png_handler.end_info_ptr = png_create_info_struct(png_handler.png_ptr);
if (!png_handler.end_info_ptr) {
PNG_CLEANUP
return 0;
}
png_set_crc_action(png_handler.png_ptr, PNG_CRC_QUIET_USE, PNG_CRC_QUIET_USE);
#ifdef PNG_IGNORE_ADLER32
png_set_option(png_handler.png_ptr, PNG_IGNORE_ADLER32, PNG_OPTION_ON);
#endif
// Setting up reading from buffer.
png_handler.buf_state = new BufState();
png_handler.buf_state->data = data + kPngHeaderSize;
png_handler.buf_state->bytes_left = size - kPngHeaderSize;
png_set_read_fn(png_handler.png_ptr, png_handler.buf_state, user_read_data);
png_set_sig_bytes(png_handler.png_ptr, kPngHeaderSize);
if (setjmp(png_jmpbuf(png_handler.png_ptr))) {
PNG_CLEANUP
return 0;
}
// Reading.
png_read_info(png_handler.png_ptr, png_handler.info_ptr);
// reset error handler to put png_deleter into scope.
if (setjmp(png_jmpbuf(png_handler.png_ptr))) {
PNG_CLEANUP
return 0;
}
png_uint_32 width, height;
int bit_depth, color_type, interlace_type, compression_type;
int filter_type;
if (!png_get_IHDR(png_handler.png_ptr, png_handler.info_ptr, &width,
&height, &bit_depth, &color_type, &interlace_type,
&compression_type, &filter_type)) {
PNG_CLEANUP
return 0;
}
// This is going to be too slow.
if (width && height > 100000000 / width) {
PNG_CLEANUP
return 0;
}
// Set several transforms that browsers typically use:
png_set_gray_to_rgb(png_handler.png_ptr);
png_set_expand(png_handler.png_ptr);
png_set_packing(png_handler.png_ptr);
png_set_scale_16(png_handler.png_ptr);
png_set_tRNS_to_alpha(png_handler.png_ptr);
int passes = png_set_interlace_handling(png_handler.png_ptr);
png_read_update_info(png_handler.png_ptr, png_handler.info_ptr);
png_handler.row_ptr = png_malloc(
png_handler.png_ptr, png_get_rowbytes(png_handler.png_ptr,
png_handler.info_ptr));
for (int pass = 0; pass < passes; ++pass) {
for (png_uint_32 y = 0; y < height; ++y) {
png_read_row(png_handler.png_ptr,
static_cast<png_bytep>(png_handler.row_ptr), nullptr);
}
}
png_read_end(png_handler.png_ptr, png_handler.end_info_ptr);
PNG_CLEANUP
return 0;
}
利用Makefile,尝试编译执行
CXX=clang++
HEADERS= -I oss-fuzz/projects/libpng-proto -I ./libprotobuf-mutator
all: libpng_read_fuzzer.o png_proto_fuzzer_example.o png_fuzz_proto.pb.o
$(CXX) -g $^ \
build/src/libfuzzer/libprotobuf-mutator-libfuzzer.a \
build/src/libprotobuf-mutator.a \
protobuf/src/.libs/libprotobuf.a \
libpng/libpng16.a \
-fsanitize=fuzzer \
-lz \
-o proto_fuzzer_test
libpng_read_fuzzer.o: libpng/contrib/oss-fuzz/libpng_read_fuzzer.cc
$(CXX) -g -c $(HEADERS) -DLLVMFuzzerTestOneInput=FuzzPNG $^
png_proto_fuzzer_example.o: oss-fuzz/projects/libpng-proto/png_proto_fuzzer_example.cc
$(CXX) -g -c $(HEADERS) $^
png_fuzz_proto.pb.o: oss-fuzz/projects/libpng-proto/png_fuzz_proto.pb.cc
$(CXX) -g -c $(HEADERS) $^
但是会遇到错误
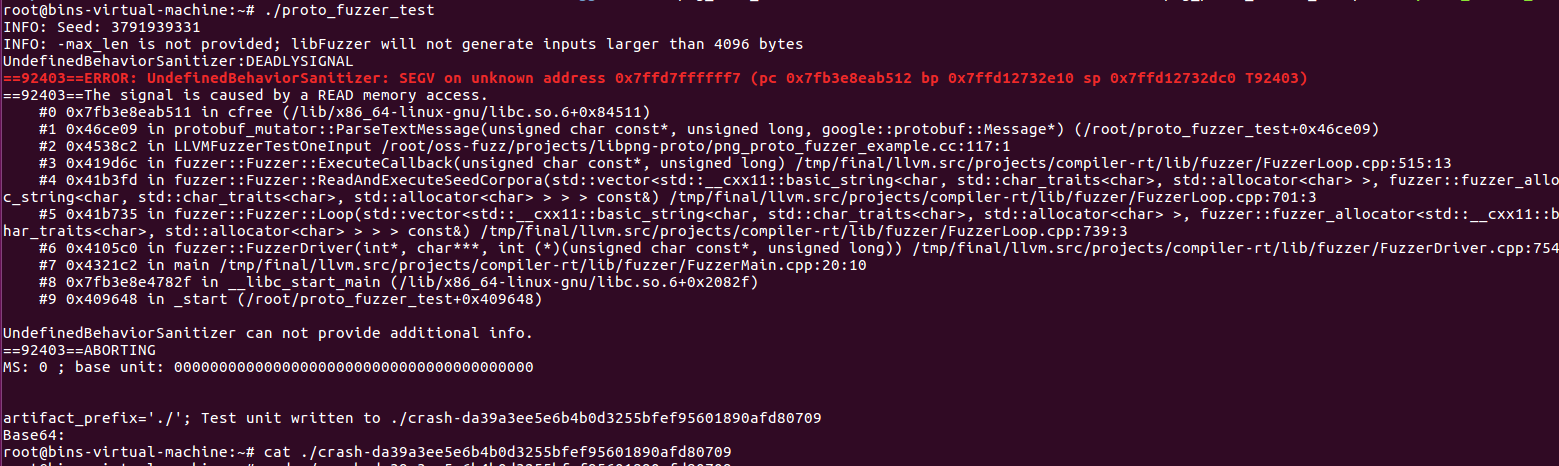
为了解决这个问题,把oss-fuzz的docs都过了一遍,发现我这么构建确实存在问题,而且官方也不推荐使用这种方式构建,建议使用
python infra/helper.py脚本构建,整个过程更加的顺畅。
git clone https://github.com/google/oss-fuzz
cd oss-fuzz
python infra/helper.py build_image libpng-proto
python infra/helper.py build_fuzzers libpng-proto
python infra/helper.py run_fuzzer libpng-proto png_proto_fuzzer_example
效果
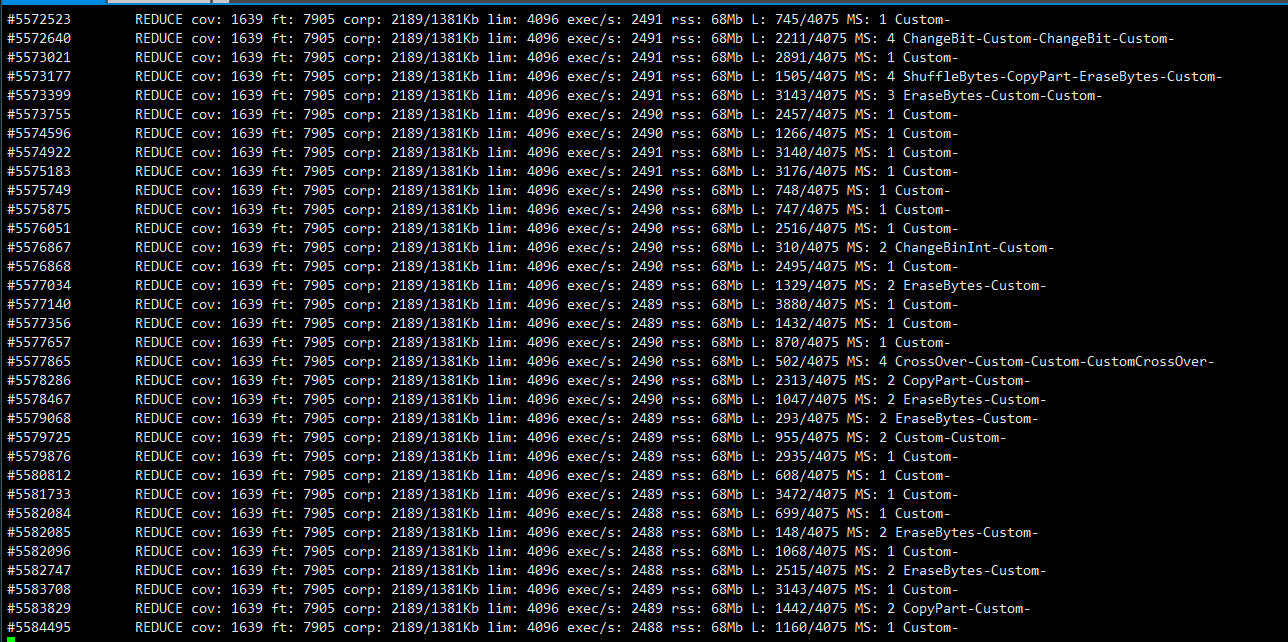
总结
首先,为什么png适合使用protobuf来构建fuzzer呢?
理由,我总结应该主要有
1. png结构相对简单
2. fuzzing更加高效
png各个chunk的数据在处理过程中有个crc校验,我们直接使用libfuzzer进行fuzzing,不是不可以,只是可能会比较低效甚至无用,因为更改某个chunk数据之后,libpng在使用crc校验会过不了,导致后面我们想fuzz的很多函数根本不会执行
3. 构造fuzzer难度降低
谷歌提供了一种比较特别的方式来构建fuzzer,即使用protobuf为基础来构建fuzzer。我个人感觉,fuzzer一般在整个fuzzing过程中,是最难的部分,但是利用protobuf,理论上只要数据结构能用protobuf表示,那么就可以利用该方法进行fuzzing,这种方式极大的降低了自己写一整套fuzzer的难度。
最后,第一次接触这类的fuzzer构建方法,对fuzzing的理解也不是很全面,难免会出现各种各样的错误,欢迎批评指正。