【node 源码学习笔记】cluster 集群
Table of Contents
-
- 前言
-
- 例子
-
- cluster
- 3.1. cluster.isMaster
- 3.2. cluster.fork
- 3.3. primary-child
- 3.3.1. 与 nginx 类似
- 3.3.2. 与 nginx 的细微区别
- 3.3.3. 选择方法1还是方法2
- 3.3.4. 还有方法3
- 3.3.5. createServer 与 listen
- 3.4. fd 的传递
- 3.4.1. ipc
- 3.4.2. uv__write
- 3.4.3. uv__read
- 3.4.4. uv__stream_recv_cmsg
- 3.4.5. OnUvRead
- 3.4.6. AcceptHandle
- 3.4.7. setupChannel
- 3.5. exit
-
- 小结
1. 前言
开始写一些博客主要是在看完代码后再温故总结一遍, 也是为了后面回头也能查阅。本系列会从官网的例子出发, 尽可能以链路追踪的方式记录其中源码核心模块的实现, 本篇例子来源
涉及的知识点
- nginx 多进程机制
- node - cluster 原理简析
- UNIX 域协议使用! 在进程间传递“文件描述符” 实例
- egg-cluster
- accept
- unix(7) — Linux manual page
- 从内核看SO_REUSEPORT的实现(基于5.9.9)
- 使用socket so_reuseport提高服务端性能
2. 例子
cluster 使用的例子分析
- isMaster 判断当前进程是主进程还是子进程
- 如果是主进程则根据 cpus 的数量衍生同等数量的子进程
- 如果是子进程则调用 createServer, 并且调用 listen 方法
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`主进程 ${process.pid} 正在运行`);
// 衍生工作进程。
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 已退出`);
});
} else {
// 工作进程可以共享任何 TCP 连接。
// 在本例子中,共享的是 HTTP 服务器。
http.createServer((req, res) => {
res.writeHead(200);
res.end('你好世界\n');
}).listen(8000);
console.log(`工作进程 ${process.pid} 已启动`);
}
3. cluster
Node.js 的单个实例在单个线程中运行。 为了利用多核系统,用户有时会想要启动 Node.js 进程的集群来处理负载。
3.1. cluster.isMaster
知识回顾: 在 ipc 通信的实现中如果判断是否是子进程就检查环境变量里面是否写入了 NODE_CHANNEL_FD, 其实就已经给了我们启发, 在 cluster 中的实现其实是类似的, 每 fork 一个子进程其环境变量中都会写入一个 NODE_UNIQUE_ID, 其值是一个自增长的整数值, 在进程中判断该环境变量有无来判断当前是否为子进程
Tips: process.env 的 value 类型皆为字符串, 即 0 为 "0", true 为 "true"。
通过代码的实现可发现主进程和子进程 require 的 cluster 文件其实是不一样的, 那么主进程 internal/cluster/primary module.exports.isMaster = true, 子进程 internal/cluster/child module.exports.isMaster = false 即可。
// lib/cluster.js
'use strict';
const childOrPrimary = 'NODE_UNIQUE_ID' in process.env ? 'child' : 'primary';
module.exports = require(`internal/cluster/${childOrPrimary}`);
3.2. cluster.fork
其也只是简单的封装了 child_process.fork
为了充分利用多核系统, 可以的做法是主进程作为了一个反向代理服务器监听用户传入的端口, 然后启动若干个子进程继续监听不同的端口, 主进程把请求转发到子进程即可。
- 优点: 没有语言限制, 进程间耦合程度低
- 缺点: 每个进程都需要生成一个 socketFd
进程间解耦也是非常重要的, 如 Service Mesh 提出的 Sidecar 模式轻松无耦合的处理服务发现、负载均衡、请求熔断等, Service Mesh, Dapr 等知识后面可以好好学习一下
// lib/internal/cluster/primary.js
function createWorkerProcess(id, env) {
const workerEnv = { ...process.env, ...env, NODE_UNIQUE_ID: `${id}` };
const execArgv = [...cluster.settings.execArgv];
const debugArgRegex = /--inspect(?:-brk|-port)?|--debug-port/;
const nodeOptions = process.env.NODE_OPTIONS || '';
...
return fork(cluster.settings.exec, cluster.settings.args, {
cwd: cluster.settings.cwd,
env: workerEnv,
serialization: cluster.settings.serialization,
silent: cluster.settings.silent,
windowsHide: cluster.settings.windowsHide,
execArgv: execArgv,
stdio: cluster.settings.stdio,
gid: cluster.settings.gid,
uid: cluster.settings.uid
});
}
那么 node 集群是怎么做的了 ?
3.3. primary-child
- 方法1:(也是除 Windows 外所有平台的默认方法)是循环法,由主进程负责监听端口,接收新连接后再将连接循环分发给工作进程,在分发中使用了一些内置技巧防止工作进程任务过载。
- 方法2: 主进程创建监听 socket 后发送给感兴趣的工作进程,由工作进程负责直接接收连接。
用 【libuv 源码学习笔记】网络与流 篇讲到知识翻译一遍上面的话即是
- 方法1: 主进程监听了端口, 当接受到新连接时调用 accept 拿到的 acceptFd 传给子进程去处理
- 方法2: 主进程不监听端口了, 只调用 socket 方法拿到 socketFd 传给子进程去处理, 这样子进程分别去监听 socketFd, 当有新连接时自行去处理。
3.3.1. 与 nginx 类似
先说一下方法2的完整实现过程, 因为其实现与 nginx 多进程机制 “雷同”
- nginx 在启动后,会有一个 master 进程和多个相互独立的 worker 进程。
- master 接收来自外界的信号,先建立好需要 listen 的 socket(listenfd) 之后,然后再 fork 出多个 worker 进程,然后向各worker进程发送信号,每个进程都有可能来处理这个连接。
- 所有 worker 进程的 listenfd 会在新连接到来时变得可读 ,为保证只有一个进程处理该连接,所有 worker 进程在注册 listenfd 读事件前抢占 accept_mutex ,抢到互斥锁的那个进程注册 listenfd 读事件 ,在读事件里调用 accept 接受该连接。
- 当一个 worker 进程在 accept 这个连接之后,就开始读取请求、解析请求、处理请求,产生数据后,再返回给客户端 ,最后才断开连接。
3.3.2. 与 nginx 的细微区别
-
不同点: 在 node 中不同的是步骤 3, 在 libuv 中没有找到互斥锁的使用, 我们先看 uv__server_io 函数, 其为 tcp 流的 i/o 观察者回调, 具体 i/o 相关可参考 【libuv 源码学习笔记】线程池与i/o
-
问题: 如果若干个子进程都监听的是同一个 socketFd, 故 uv__server_io 会在不同的进程里面在极短的时间内同时被调用, 没有互斥锁如何控制 ?
-
解决方案: 当被其中一个子进程率先处理后, 通过看下面的代码 err 此时是 < 0, 出现了 UV_EAGAIN, EWOULDBLOCK 错误, 紧接着错误后面的注释为 /* Not an error. */, 关于这两个错误的解释是套接字文件描述符设置了O_NONBLOCK,并且没有连接可以接受, 即如果一个子进程抢占失败则静默即可。
[EAGAIN] or [EWOULDBLOCK]: O_NONBLOCK is set for the socket file descriptor and no connections are present to be accepted .
// deps/uv/src/unix/stream.c
void uv__server_io(uv_loop_t* loop, uv__io_t* w, unsigned int events) {
...
err = uv__accept(uv__stream_fd(stream));
if (err < 0) {
if (err == UV_EAGAIN || err == UV__ERR(EWOULDBLOCK))
return; /* Not an error. */
if (err == UV_ECONNABORTED)
continue; /* Ignore. Nothing we can do about that. */
if (err == UV_EMFILE || err == UV_ENFILE) {
err = uv__emfile_trick(loop, uv__stream_fd(stream));
if (err == UV_EAGAIN || err == UV__ERR(EWOULDBLOCK))
break;
}
stream->connection_cb(stream, err);
continue;
}
...
}
3.3.3. 选择方法1还是方法2
来自 node 官网 的解释: 理论上方法2 应该是效率最佳的。 但在实际情况下,由于操作系统调度机制的难以捉摸,会使分发变得不稳定。 可能会出现八个进程中有两个分担了 70% 的负载。所以即使方法1 主进程做的事情比较多, 也会默认采用。
个人感觉可能是 uv__server_io 函数中到底哪个进程能够抢先调用 uv__accept 去处理一个连接的不确定性造成的上面说的问题。
3.3.4. 还有方法3
node 暂未支持的特性,了解到方法3是从 theanarkh 大佬的从内核看SO_REUSEPORT的实现(基于5.9.9)这篇文章,其主要出现的原因为方法2会造成惊群现象,即一有新连接来了,所以进程都被唤醒了,然而成功的只有一个。SO_REUSEPORT 特性的实现主要是在内核层面去做一个负载均衡的调度。如果 SO_REUSEPORT 能被普遍兼容的话, node 集群就可以完全交给内核去做了。阅读更多推荐 使用socket so_reuseport提高服务端性能
如果 node 基于方法2模拟类似的功能的话,就需要方法2的 uv__server_io 函数中去维护一个队列,逐个去分配连接达到同样的效果,防止多线程竞争访问造成的问题。

3.3.5. createServer 与 listen
在方法1与方法2中也提到了并不是所有的进程都需要真正的调用 listen 方法, 其原理与实现流程推荐阅读 Node.js:cluster原理简析。
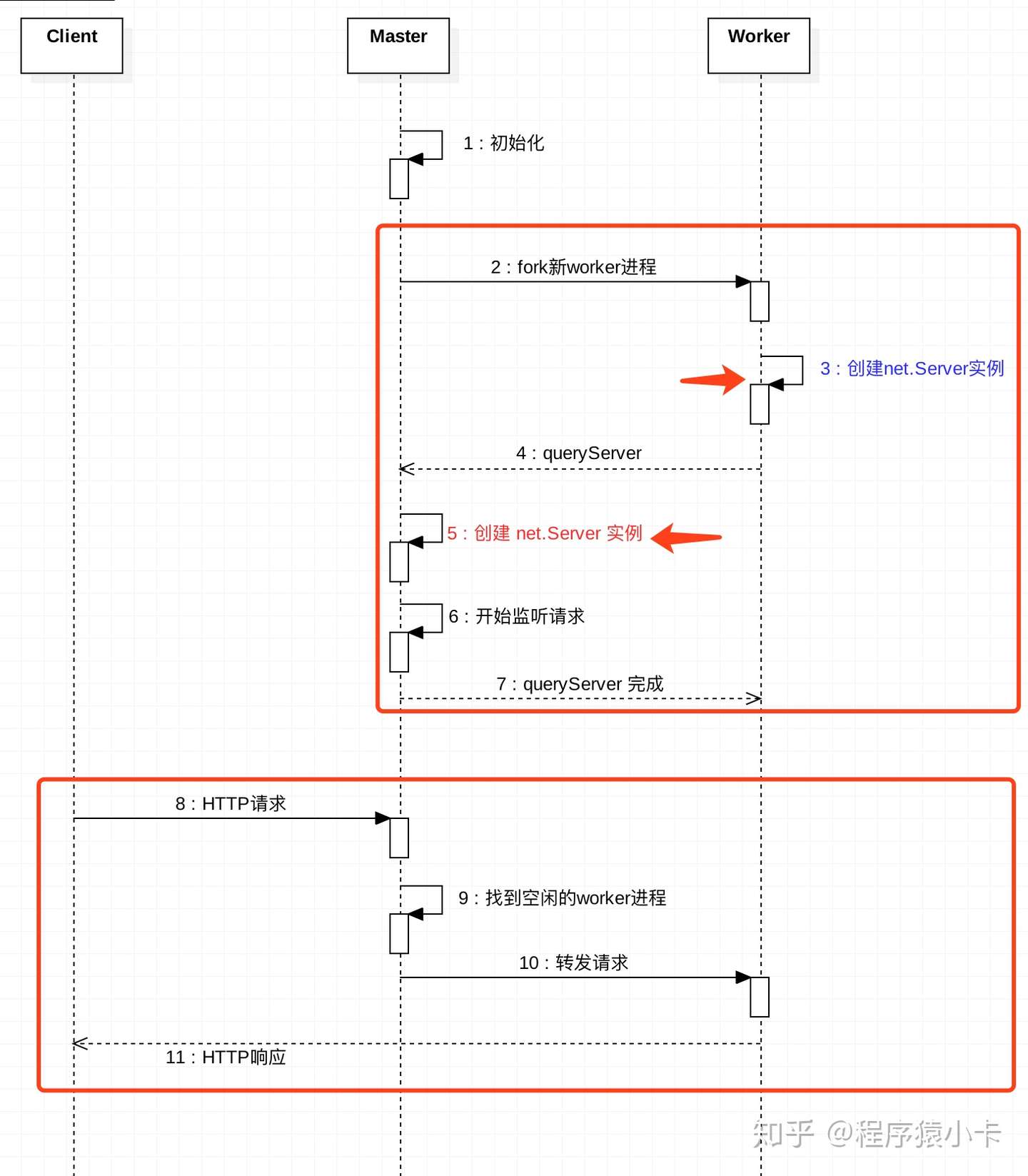
3.4. fd 的传递
核心的实现上面的文章大佬已经分析得很透彻了, 这里我就讲一下偏门一点的知识。
无论是方法1还是方法2都涉及到进程间如何更好的传递 fd。
3.4.1. ipc
回顾一下 【libuv 源码学习笔记】子进程与ipc 的实现
- 在子进程写入了一个 NODE_CHANNEL_FD 的环境变量, 如值为 5
- 调用 socketpair 拿到进程通信的 fd
- 调用 dup2 把子进程文件指针数组第 5 项重定向到 fd[1]
那么当方法1, 每当有一个新连接来时, 传递一个 acceptFd 到子进程按 ipc 的实现的话, 这里子进程已经生成就不能继续通过写入环境变量的方法, 可以通过 process.send {acceptFd: xxx}, 然后在走 ipc 一套也太麻烦了。
让我们看看 node 中 fd 的传递的实现。
3.4.2. uv__write
如父进程向子进程发送一个 fd
- js 代码:
- 方法1 worker.process.send(msg, new TCP(TCPConstants.SOCKET))
- 方法2 worker.process.send(msg, new TCP(TCPConstants.SERVER))
- c++ 代码: 通过 uv__handle_fd 方法获取 TCP 实例里面的 fd, 挂载在 msg.msg_control 上面
- c++ 代码: 调用 sendmsg 方法写入数据
如果 req->send_handle ( 为步骤1中的 new TCP(TCPConstants.SERVER)) 存在, 即代表此次是有 fd 传递的任务
- 当通信方式为 ipc 时的读写方法为 recvmsg 与 sendmsg
- 当通信方式为 pipe 时的读写方法为 read 与 write
其一个主要原因的 ipc 通信时, recvmsg 能够写入的数据可包含 cmsg 字段, 在文章 UNIX 域协议使用! 在进程间传递“文件描述符” 实例 中有清楚的例子讲解。
在 unix(7) — Linux manual page 中指出传递的其实是文件的引用描述, 直接省去了手动重定向等一批麻烦的事。
通常,此操作称为“传递文件描述符”到另一个进程。但是,更准确地说,传递的是对打开文件的引用描述(参见open(2)),并在接收过程中可能会有不同的文件描述符编号用过的。在语义上,这个操作等价于将(dup(2))文件描述符复制到文件中另一个进程的描述符表。
// deps/uv/src/unix/stream.c
static void uv__write(uv_stream_t* stream) {
...
if (req->send_handle) {
int fd_to_send;
struct msghdr msg;
struct cmsghdr *cmsg;
union {
char data[64];
struct cmsghdr alias;
} scratch;
if (uv__is_closing(req->send_handle)) {
err = UV_EBADF;
goto error;
}
fd_to_send = uv__handle_fd((uv_handle_t*) req->send_handle);
memset(&scratch, 0, sizeof(scratch));
assert(fd_to_send >= 0);
msg.msg_name = NULL;
msg.msg_namelen = 0;
msg.msg_iov = iov;
msg.msg_iovlen = iovcnt;
msg.msg_flags = 0;
msg.msg_control = &scratch.alias;
msg.msg_controllen = CMSG_SPACE(sizeof(fd_to_send));
cmsg = CMSG_FIRSTHDR(&msg);
cmsg->cmsg_level = SOL_SOCKET;
cmsg->cmsg_type = SCM_RIGHTS;
cmsg->cmsg_len = CMSG_LEN(sizeof(fd_to_send));
/* silence aliasing warning */
{
void* pv = CMSG_DATA(cmsg);
int* pi = pv;
*pi = fd_to_send;
}
do
n = sendmsg(uv__stream_fd(stream), &msg, 0);
while (n == -1 && RETRY_ON_WRITE_ERROR(errno));
/* Ensure the handle isn't sent again in case this is a partial write. */
if (n >= 0)
req->send_handle = NULL;
} else {
do
n = uv__writev(uv__stream_fd(stream), iov, iovcnt);
while (n == -1 && RETRY_ON_WRITE_ERROR(errno));
}
...
}
3.4.3. uv__read
当主进程调用 uv__write 在 socketpair 一端写入数据后, 子进程通过 uv__read 读取
通过 uv__recvmsg 读取普通数据, 通过 uv__stream_recv_cmsg 方法读取 fd。
// deps/uv/src/unix/stream.c
static void uv__read(uv_stream_t* stream) {
...
is_ipc = stream->type == UV_NAMED_PIPE && ((uv_pipe_t*) stream)->ipc;
...
if (!is_ipc) {
do {
nread = read(uv__stream_fd(stream), buf.base, buf.len);
}
while (nread < 0 && errno == EINTR);
} else {
/* ipc uses recvmsg */
msg.msg_flags = 0;
msg.msg_iov = (struct iovec*) &buf;
msg.msg_iovlen = 1;
msg.msg_name = NULL;
msg.msg_namelen = 0;
/* Set up to receive a descriptor even if one isn't in the message */
msg.msg_controllen = sizeof(cmsg_space);
msg.msg_control = cmsg_space;
do {
nread = uv__recvmsg(uv__stream_fd(stream), &msg, 0);
}
while (nread < 0 && errno == EINTR);
}
if (nread < 0) {
...
} else {
/* Successful read */
ssize_t buflen = buf.len;
if (is_ipc) {
err = uv__stream_recv_cmsg(stream, &msg);
if (err != 0) {
stream->read_cb(stream, err, &buf);
return;
}
}
...
}
3.4.4. uv__stream_recv_cmsg
- 如果是方法1: 主进程分发若干个 acceptFd 给子进程, 则该子进程可能会收到多个, 会调用 uv__stream_queue_fd 存入 stream->queued_fds 中等待处理
- 如果是方法2: 主进程只会发送一个 socketFd 给子进程, 此时保存在 stream->accepted_fd 中
static int uv__stream_recv_cmsg(uv_stream_t* stream, struct msghdr* msg) {
struct cmsghdr* cmsg;
for (cmsg = CMSG_FIRSTHDR(msg); cmsg != NULL; cmsg = CMSG_NXTHDR(msg, cmsg)) {
char* start;
char* end;
int err;
void* pv;
int* pi;
unsigned int i;
unsigned int count;
if (cmsg->cmsg_type != SCM_RIGHTS) {
fprintf(stderr, "ignoring non-SCM_RIGHTS ancillary data: %d\n",
cmsg->cmsg_type);
continue;
}
/* silence aliasing warning */
pv = CMSG_DATA(cmsg);
pi = pv;
/* Count available fds */
start = (char*) cmsg;
end = (char*) cmsg + cmsg->cmsg_len;
count = 0;
while (start + CMSG_LEN(count * sizeof(*pi)) < end)
count++;
assert(start + CMSG_LEN(count * sizeof(*pi)) == end);
for (i = 0; i < count; i++) {
/* Already has accepted fd, queue now */
if (stream->accepted_fd != -1) {
err = uv__stream_queue_fd(stream, pi[i]);
if (err != 0) {
/* Close rest */
for (; i < count; i++)
uv__close(pi[i]);
return err;
}
} else {
stream->accepted_fd = pi[i];
}
}
}
return 0;
}
3.4.5. OnUvRead
承接上面的 uv__stream_recv_cmsg 方法子进程读取到的 fd, 子进程接下来的处理
当上一个连接的数据被读取时, 通过 uv_pipe_pending_count 方法判断当前是否有 stream->queued_fds 或者 stream->accepted_fd, 如果有的话调用 AcceptHandle 去接受连接继续去处理。
值得关注的点: pending_obj 接收到了 AcceptHandle 方法返回的结果, 并且通过 object()->Set 写入了 context 中。
// src/stream_wrap.cc
void LibuvStreamWrap::OnUvRead(ssize_t nread, const uv_buf_t* buf) {
HandleScope scope(env()->isolate());
Context::Scope context_scope(env()->context());
uv_handle_type type = UV_UNKNOWN_HANDLE;
if (is_named_pipe_ipc() &&
uv_pipe_pending_count(reinterpret_cast<uv_pipe_t*>(stream())) > 0) {
type = uv_pipe_pending_type(reinterpret_cast<uv_pipe_t*>(stream()));
}
// We should not be getting this callback if someone has already called
// uv_close() on the handle.
CHECK_EQ(persistent().IsEmpty(), false);
if (nread > 0) {
MaybeLocal<Object> pending_obj;
if (type == UV_TCP) {
pending_obj = AcceptHandle<TCPWrap>(env(), this);
} else if (type == UV_NAMED_PIPE) {
pending_obj = AcceptHandle<PipeWrap>(env(), this);
} else if (type == UV_UDP) {
pending_obj = AcceptHandle<UDPWrap>(env(), this);
} else {
CHECK_EQ(type, UV_UNKNOWN_HANDLE);
}
if (!pending_obj.IsEmpty()) {
object()
->Set(env()->context(),
env()->pending_handle_string(),
pending_obj.ToLocalChecked())
.Check();
}
}
EmitRead(nread, *buf);
}
3.4.6. AcceptHandle
- 如果是方法1: 子进程就会把 stream->queued_fds 中调用 uv_accept 逐个去处理完这些连接
- 如果是方法2: 子进程则会把 wrap_obj 的值返回给 OnUvRead 中提到的 pending_obj, wrap_obj 是一个 tcp 流对象, 其通过 uv_accept > uv__stream_open 的调用链路把自己的 io_watcher.fd 设置为了从父进程写入的 stream->accepted_fd 完成接收任务, 这个实现比较绕, 找了好久才发现是这里注入 ...
通过上面的方法至此子进程已经成功接收的自己所需的 fd, 然后子进程生成对应的 Handle 对象传给 js
- 方法1 生成 new TCP(TCPConstants.SOCKET)
- 方法2 生成 new TCP(TCPConstants.SERVER)
template <class WrapType>
static MaybeLocal<Object> AcceptHandle(Environment* env,
LibuvStreamWrap* parent) {
static_assert(std::is_base_of<LibuvStreamWrap, WrapType>::value ||
std::is_base_of<UDPWrap, WrapType>::value,
"Can only accept stream handles");
EscapableHandleScope scope(env->isolate());
Local<Object> wrap_obj;
if (!WrapType::Instantiate(env, parent, WrapType::SOCKET).ToLocal(&wrap_obj))
return Local<Object>();
HandleWrap* wrap = Unwrap<HandleWrap>(wrap_obj);
CHECK_NOT_NULL(wrap);
uv_stream_t* stream = reinterpret_cast<uv_stream_t*>(wrap->GetHandle());
CHECK_NOT_NULL(stream);
if (uv_accept(parent->stream(), stream))
ABORT();
return scope.Escape(wrap_obj);
}
3.4.7. setupChannel
js 中的参数 pendingHandle 即是上面 AcceptHandle 生成的 TCP 实例对象。
pending_obj > pending_handle_string > pendingHandle
// lib/internal/child_process.js
channel.onread = function(arrayBuffer) {
const recvHandle = channel.pendingHandle;
channel.pendingHandle = null;
if (arrayBuffer) {
const nread = streamBaseState[kReadBytesOrError];
const offset = streamBaseState[kArrayBufferOffset];
const pool = new Uint8Array(arrayBuffer, offset, nread);
if (recvHandle)
pendingHandle = recvHandle;
for (const message of parseChannelMessages(channel, pool)) {
if (isInternal(message)) {
if (message.cmd === 'NODE_HANDLE') {
handleMessage(message, pendingHandle, true);
pendingHandle = null;
} else {
handleMessage(message, undefined, true);
}
} else {
handleMessage(message, undefined, false);
}
...
};
剩下的步骤
- 方法1: 每来一个新连接走上面的一套流程, 然后手动调用 server.onconnection(0, handle) 处理当前的连接
- 方法2: 只接受一次, 然后调用 listen 开始监听, 有连接来了走默认的逻辑即会自动调用 onconnection 处理
3.5. exit
当看到某一个子进程退出时, 代码里面好像啥事也没干, 心想这不就瘸腿了吗 ...
// lib/internal/cluster/primary.js
worker.process.once('exit', (exitCode, signalCode) => {
/*
* Remove the worker from the workers list only
* if it has disconnected, otherwise we might
* still want to access it.
*/
if (!worker.isConnected()) {
removeHandlesForWorker(worker);
removeWorker(worker);
}
worker.exitedAfterDisconnect = !!worker.exitedAfterDisconnect;
worker.state = 'dead';
worker.emit('exit', exitCode, signalCode);
cluster.emit('exit', worker, exitCode, signalCode);
});
又仔细查阅了一下文档, 这文档 'exit' 事件 这有了说明, 需要把如下代码手动监听一下 exit 事件, 感觉是个比较隐秘的坑 ...
cluster.on('exit', (worker, code, signal) => {
console.log('工作进程 %d 关闭 (%s). 重启中...',
worker.process.pid, signal || code);
cluster.fork();
});
最后去 egg-cluster 也确认了一下, 有个 refork 选项看上去是我想查的, 接着去 cfork 即如果生产环境如果意外退出默认会通过 cluster.fork() 重启子进程, 大佬们还是都考虑到了 ~
// egg-cluster
cfork({
exec: this.getAppWorkerFile(),
args,
silent: false,
count: this.options.workers,
// don't refork in local env
refork: this.isProduction,
windowsHide: process.platform === 'win32',
});
// cfork
if (allow()) {
newWorker = forkWorker(worker._clusterSettings);
newWorker._clusterSettings = worker._clusterSettings;
log('[%s] [cfork:master:%s] new worker:%s fork (state: %s)',
utility.logDate(), process.pid, newWorker.process.pid, newWorker.state);
}
function allow() {
if (!refork) {
return false;
}
...
}
function forkWorker(settings) {
if (settings) {
cluster.settings = settings;
cluster.setupMaster();
}
return cluster.fork(attachedEnv);
}
4. 小结
cluster 集群的原理不少大佬已经讲得非常清楚了, 本篇就主要讲了一下冷门的 acceptFd, socketFd 进程间的传递的实现过程。