deploy-microservices-to-a-Kubernetes-cluster
 deploy-microservices-to-a-Kubernetes-cluster copied to clipboard
deploy-microservices-to-a-Kubernetes-cluster copied to clipboard
如何将微服务部署在kubernetes集群之上
deploy-microservices-to-a-Kubernetes-cluster
如何将微服务部署在kubernetes集群之上
微服务 + Kubernetes 入门宝典上卷
随着互联网的发展,后端服务和容器编排技术的日益成熟,微服务成为了后端服务的首选,Kubernetes 也已经成为目前容器编排的事实标准, 微服务拥抱容器时代已经来临。笔者结合自己的经验,写了这篇 微服务+ Kubernetes 入门宝典,希望能够抛砖引玉。能让大家了解 微服务和 Kubernetes如何配合。上卷主要描述 微服务设计,项目实现,kubernetes 部署,微服务的部署 高可用和监控 这几个部分。下卷计划讨论服务化网格和数据持久化, 有状态服务,operator 这几部分。 本文由我独立完成(ppmsn2005#gmail.com) 如有任何错误,是我个人原因,请直接和我联系,谢谢!您可以在 https://github.com/xiaojiaqi/deploy-microservices-to-a-Kubernetes-cluster 找到本文的全文和相关资料.
本卷要义:
本文会从设计开始,设计一个简单的前后端分离的项目,并将它部署在kubernetes集群上,期间我们将关注微服务和 kubernetes 配合的各个方面,并且从 系统的可用性,可靠性 强壮性 可扩展进行讨论,最终设计一个可以真正实用的系统。
整体上我们从4个章节描述这个目标,分别是
第一章:微服务项目的设计,
第二章:微服务项目的具体实现
第三章:kubernetes的部署
第四章:微服务高可用部署及验证
注: 微服务是一种设计思想,它并不局限于任何开发语言,在本例中我们选择java的spring boot 框架来实现微服务。微服务之间的RPC方案也很多,我们这里选择RESTFUL 这种最常见的方案。为了项目的简洁,项目也没有涉及数据库和缓存,配置中心相关的内容。我们主要注重项目的设计思想实践和项目改进。
第一章:微服务项目的设计
1.1 微服务设计的思想
首先我们简单地回顾一下微服务,微服务的定义当来自Martin flowerler https://martinfowler.com/articles/microservices.html 一文,借用大佬的一张图 描述了微服务最本质的东西。
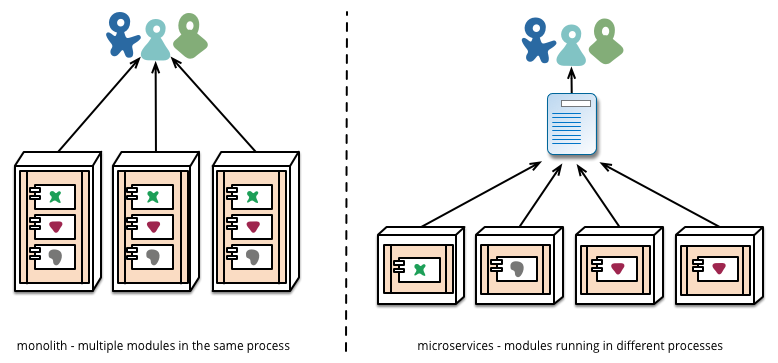
微服务把各个功能拆开了,每个模块的功能更加独立,也更加单一。每个模块都独立发展,可以说做到了功能的高内聚,低偶合。
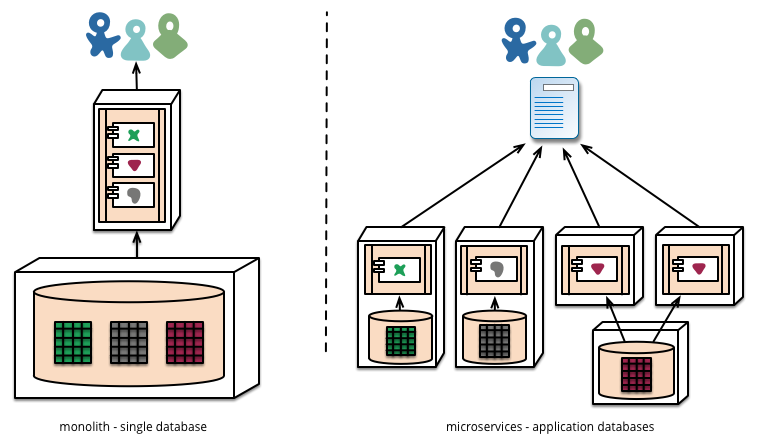
再借一张,这样数据库也被彻底拆分开了。一个巨大复杂的单体数据库也按照功能拆成了小的独立数据库。
微服务就是这么简单吗? 当然不是,里面有很多细节需要考虑,纸上得来终觉浅,绝知此事要躬行。 这次让我们开始从0开始真正的设计整套系统。
1.2 实践设计和改进
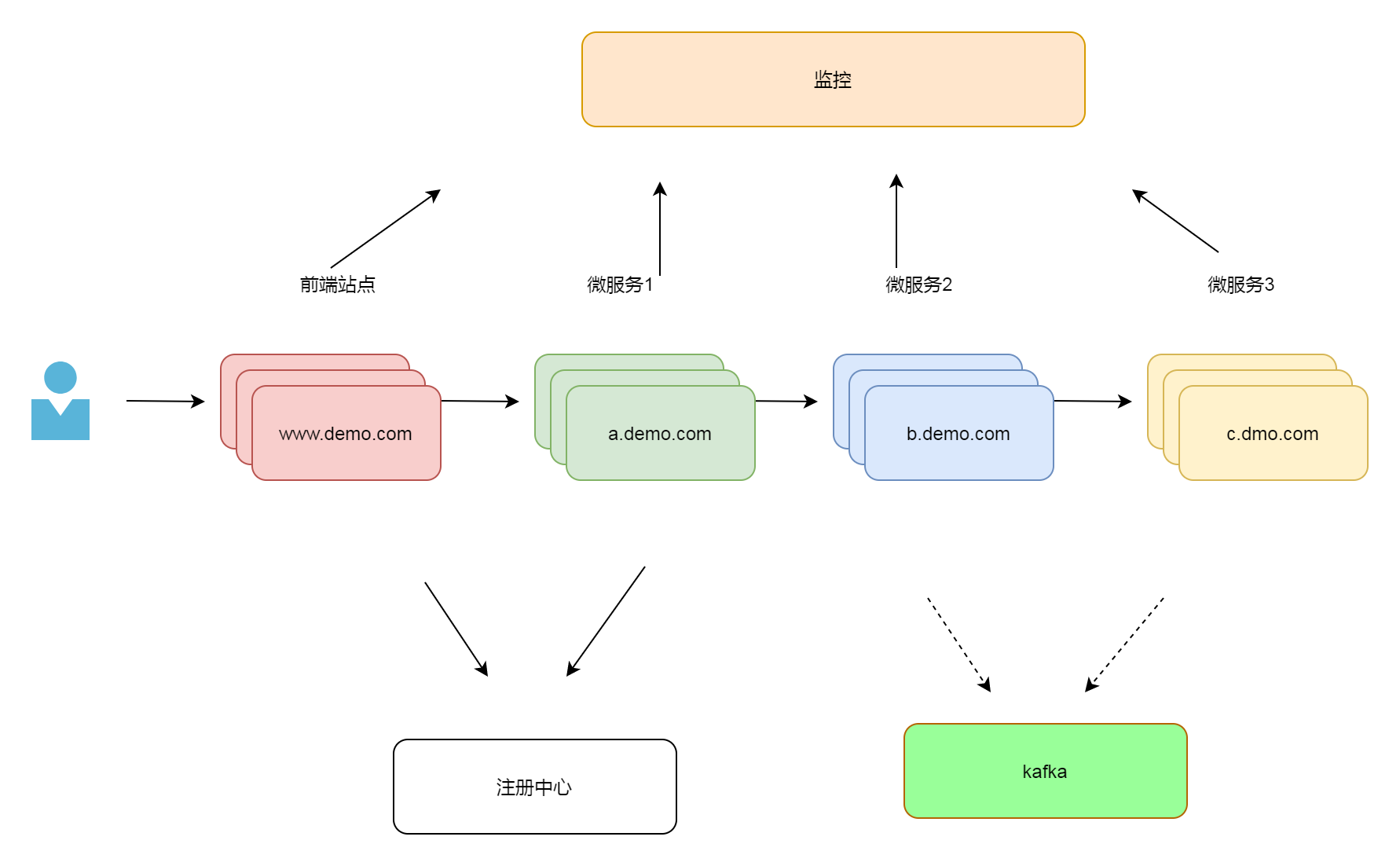
现在我们要设计一个最简单的微服务架构。为了更贴近真实的业务。我们假设这个系统是这样的。

整个系统的前端是一个有着前后端分离站点,用户访问了www.demo.com 这个前端站点,通过前端页面发起请求,www.demo.com 服务器将请求发往a.demo.com. 然后a.demo.com 再请求b.demo.com ,b.demo.com 再请求 c.demo.com。c.demo.com 将结果返回后,不断返回,最终显示在前端站点,完成微服务的全套调用流程。[ 一般业务系统 在前端和微服务直接还存在一个网关部分,网关一般用于鉴权,请求分类,监控等功能, 这里因为比较简单,所以省略了这个部分]
最终我们将这套架构将部署在kubernetes 上,开始真正的服务用户。
1.3 改进项目
从图一我们可以看到这是一个非常简单而单薄的架构,存在很多问题,我们需要不断地解决它们。下面我们开始改进项目。
首先,我们要解决节点的可靠性。在图一所有的节点都只有一个实例,任何节点的崩溃都将造成项目无法运行,在真正的项目中这是不可接受的。怎么解决呢?当然是多个实例
1.3.1 加入多实例及注册中心
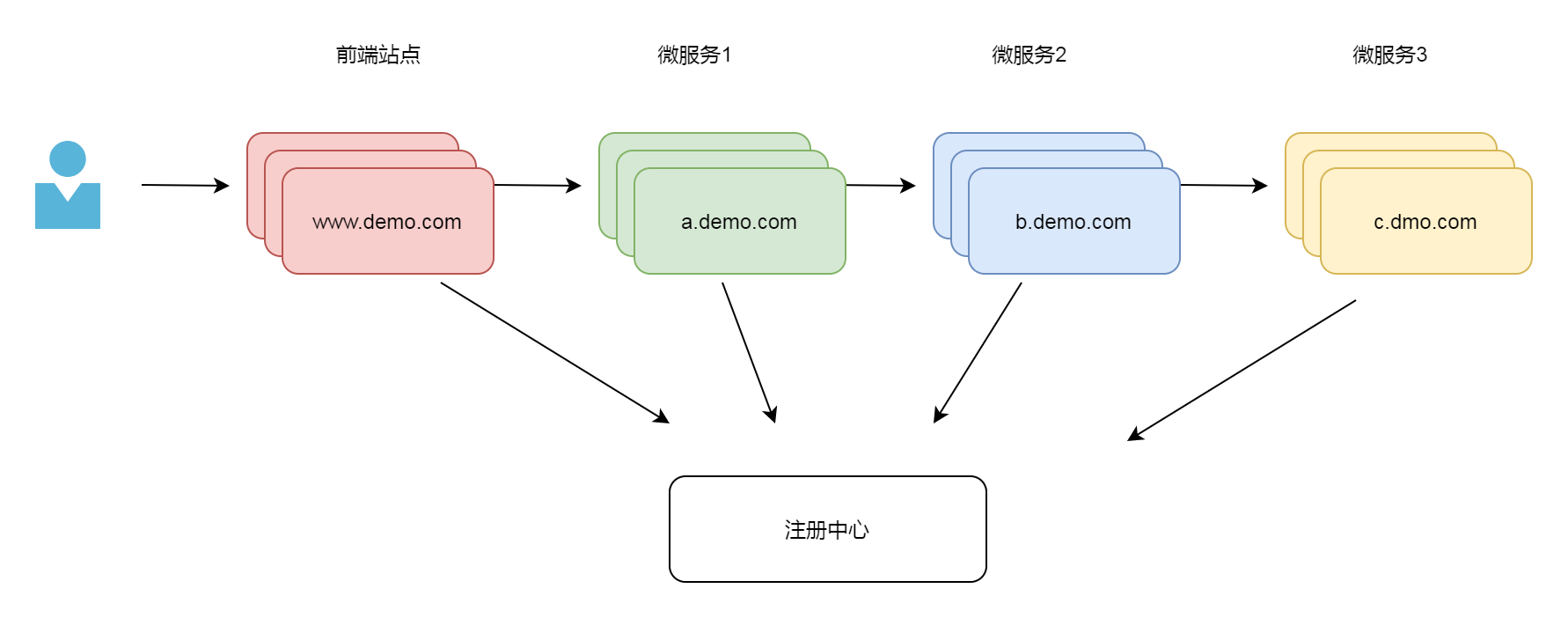
我们将各个模块的实例数目增加,多个实例才能保证整个系统的可靠性。 如果一个实例有问题,我们还是可以其他相同的实例进行服务。
但是多个实例又带来一个问题,各个组件之间如何定位呢?如果有10个b.demo.com 实例,它的上下游又该如何找到它们呢? 解决方案之一是注册中心。注册中心解决的是应用之间的寻址问题。有了它,上下游之间的应用可以相互寻址,并且获知那些实例是可用的,应用挑选可用的实例进行工作。注册中心的方案很多,有eureka,zookeeper, consul, Nacos 等等,关于讨论各种注册中心是AP、CP的区别,优劣的文章很多,这篇文章不是一篇微服务的开发教程,我们选择比较常见的eureka为演示的注册中心。
注: 在kubernetes 中部署微服务,对注册中心是没有任何限制的。所以不要被某些文章误导,按照这篇文章做,你完全可以做到代码零修改,直接在kubernetes 上运行。
1.3.2 监控系统 Metrics
在完成了注册中心的功能后,虽然整个系统可以运行了,我们会发现没有应用监控的情况下,我们对系统运转状态是完全摸黑的,这样相当于盲人骑马,非常危险。我们需要知道所有微服务运行的状态,必须将各个微服务的状态监控起来,只有这样才能做到 运筹帷幄,决胜千里。
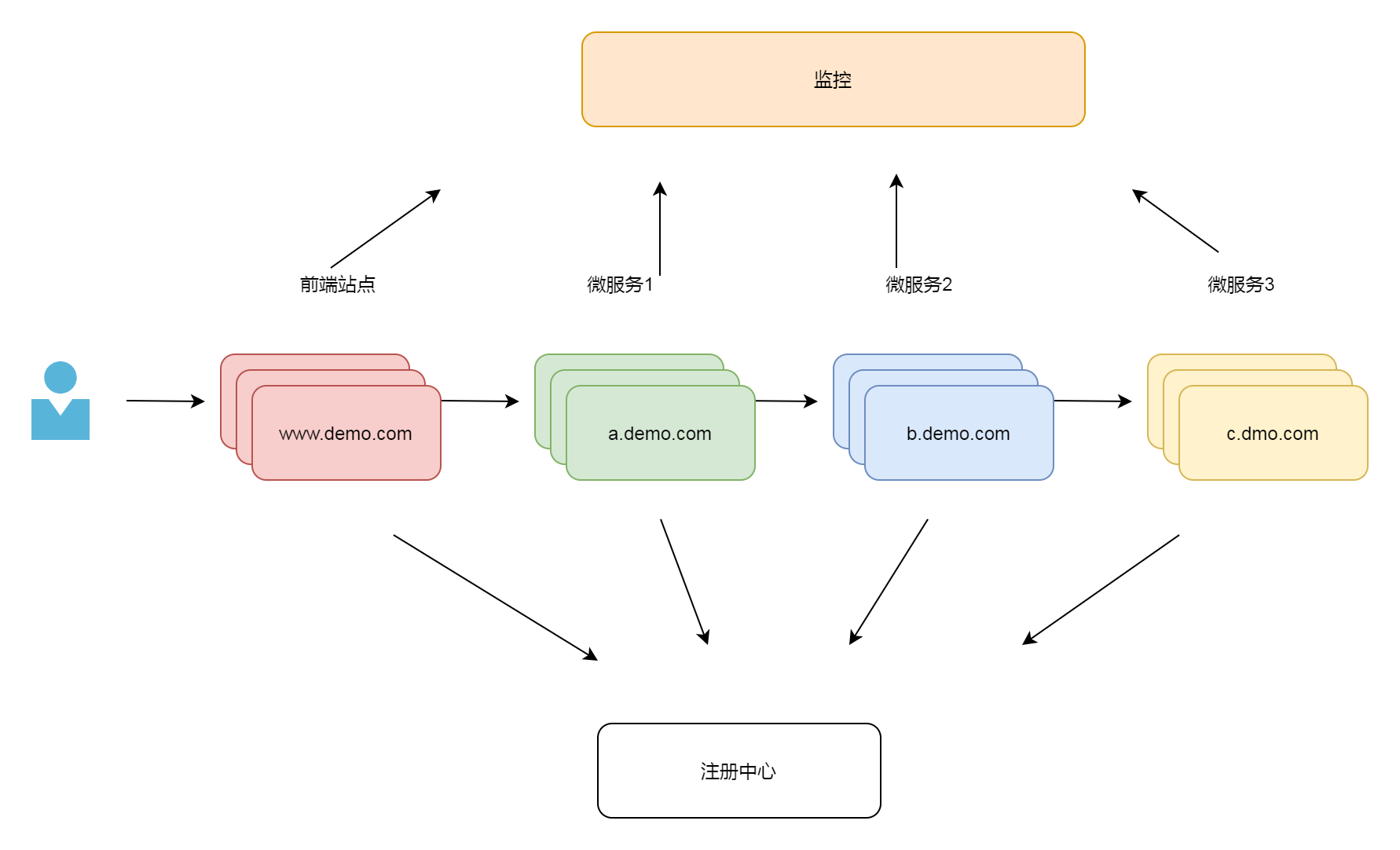
在这里,我们选择使用Prometheus和Grafana这套监控组合。Prometheus + Grafana是一个比较常见的组合, 基本是现在容器监控的标准配置。
在kubernetes 上,我们需要每个微服务的实例里开启监控数据到导出功能。同时利用启Prometheus 的自动发现功能, 这样Prometheus 可以将数据收集存储起来。这里的数据包括每个应用的各项指标比如内存大小,200错误数目,500错误数目, JVM里线程数量,GC时间大小。配合granfana的聚合显示能力,我们可以直观地对整个系统有完整把控。在应用开发过程中,我们只需要在代码里加入一个类库就可以实现信息的导出,不需要专门写代码。
1.3.3 日志系统 logging
目前已经有了监控,日志还有存在的必要吗? 当然 下面这个图就反应监控的3个维度。
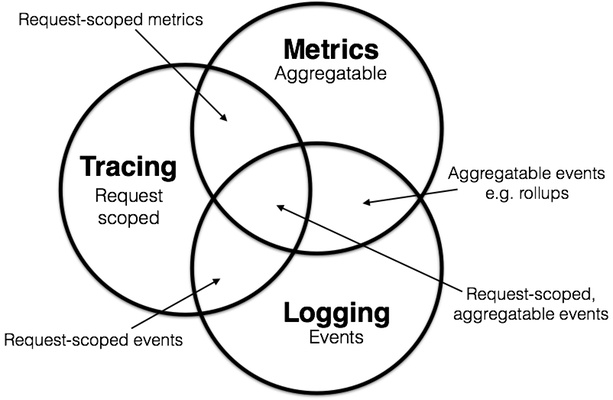
这3个维度分别是Mertics Tracing 和logging
Metrics 主要就是指刚才说的监控,它主要反应的就是一个聚合的数据,比如今天200错误是多少,QPS是多少? 它指的是一段时间内的数据聚合。
Logging 就是我们现在讨论的日志。的它描述一些离散的(不连续的)事件。比如各个系统里的错误,告警。所以我们需要将日志收集起来。
Tracing 则关注单次请求中信息。我们关注请求的质量和服务可行性,是我们优化系统,排查问题的工具。
说到了日志,在一个分布式系统,日志是非常重要的一环。因为微服务和容器的缘故,导致日志收集不是这么简单了。因为在kubernetes 里 容器的销毁和重启都是经常可能出现的,我们需要第一时间就把日志收集起来。
日志收集的方案有很多,有些方案是在本地启动一个收集进程,将落地的日志转发到kakfa组件再转发日志中心,也有的方案是直接写到kafka组件直接进入日志中心。两者各有优劣。
在这里,我们的方案选择了后者。我们简单地利用一个组件将日志直接打入kafka 组件。这种方案的好处是我们日志不再落地,日志IO被消除了,日志的存储也和容器做到了分离。我们再也不用担心日志IO对宿主机造成的系统压力了。
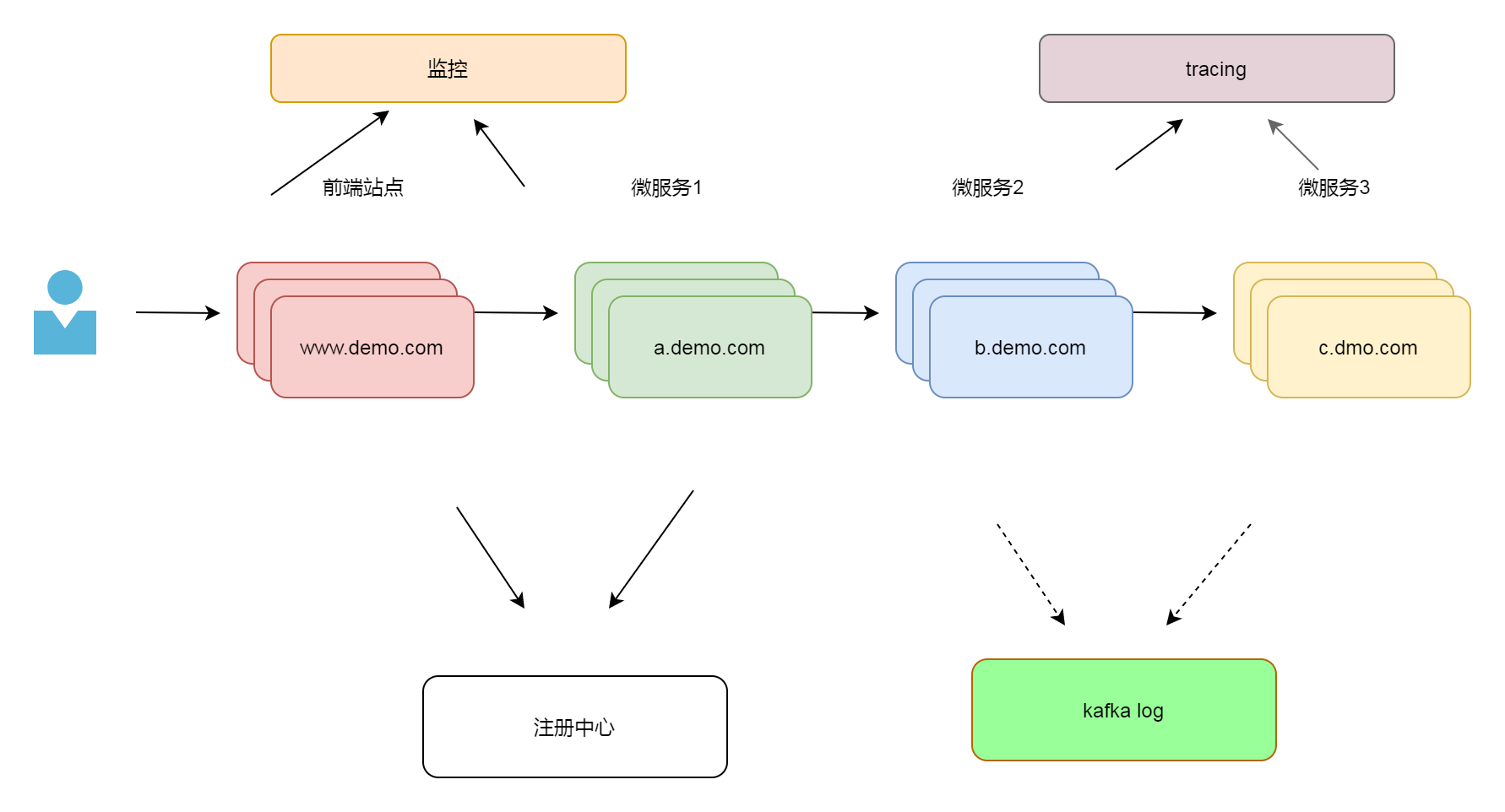
1.3.4 追踪系统 Tracing
刚才我们讨论了监控 (Metric)和日志(Logging),还有一个维度就是追踪(Tracing).
随着微服务的实例越来越多,有一个很现实的问题出现了,当大规模分布式集群出现了,应用构建在不同的容器集群里、有可能布在了几千台容器里,横跨多个不同的数据中心。因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具。这该怎么解决呢? 可以看看google的论文 google dapper
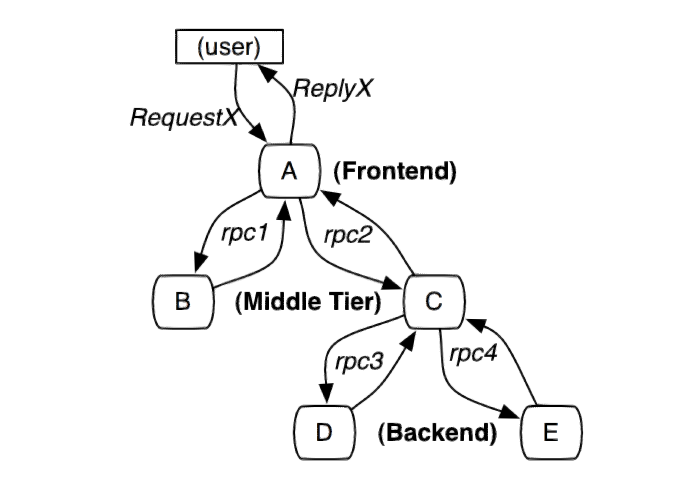
Google 的论文描述一种解决办法,我们一般称作APM(Application Performance Monitor). 它把一次调用加入一个独立无二的标记,并且在各个系统里透传标记,从而达到追踪整个消息处理过程的能力。市面上大多数实现都是基于这一思想,可选方案的有很多,如 cat pip, zipkin, skywalkin。它们有需要代码注入的,有无注入的。 关于他们的优劣也有很多文章评述。在这里我们选用zipkin 。 Zipkin 需要在项目中加入一个库,并不需要写代码,这对业务的入侵做到了很少,非常方便。
1.3.5 流量控制
你认为这一切就完了吗?当然不是,微服务里还有一项非常重要的功能:流量控制,我们还没有做。
当海量的请求来临的时候,我们可以用增加容器数量的办法来提高我们的服务能力,但是简单地添加实例是很危险的,因为整个系统的服务能力是被系统短板所限制的,简单地添加实例,并不是总能起到提高服务能力的作用。反而可能引起反作用,最终导致整个系统的崩溃。
我们对整个系统的负载容量是有一个设计的,当超出我们设计的能力时,我们需要对多余的请求说No。 相应的方案分别是熔断、限流和降级。目前java领域的这方面的hystrix,sentinel 在这方面都做得很好。Sentinel 在阿里接受了考验,并且使用起来也很简单,所以我们选它。现在我们在整个系统里加上一个流量控中心。这样一个基本完整的 可靠的 高可靠的系统就基本完成了。
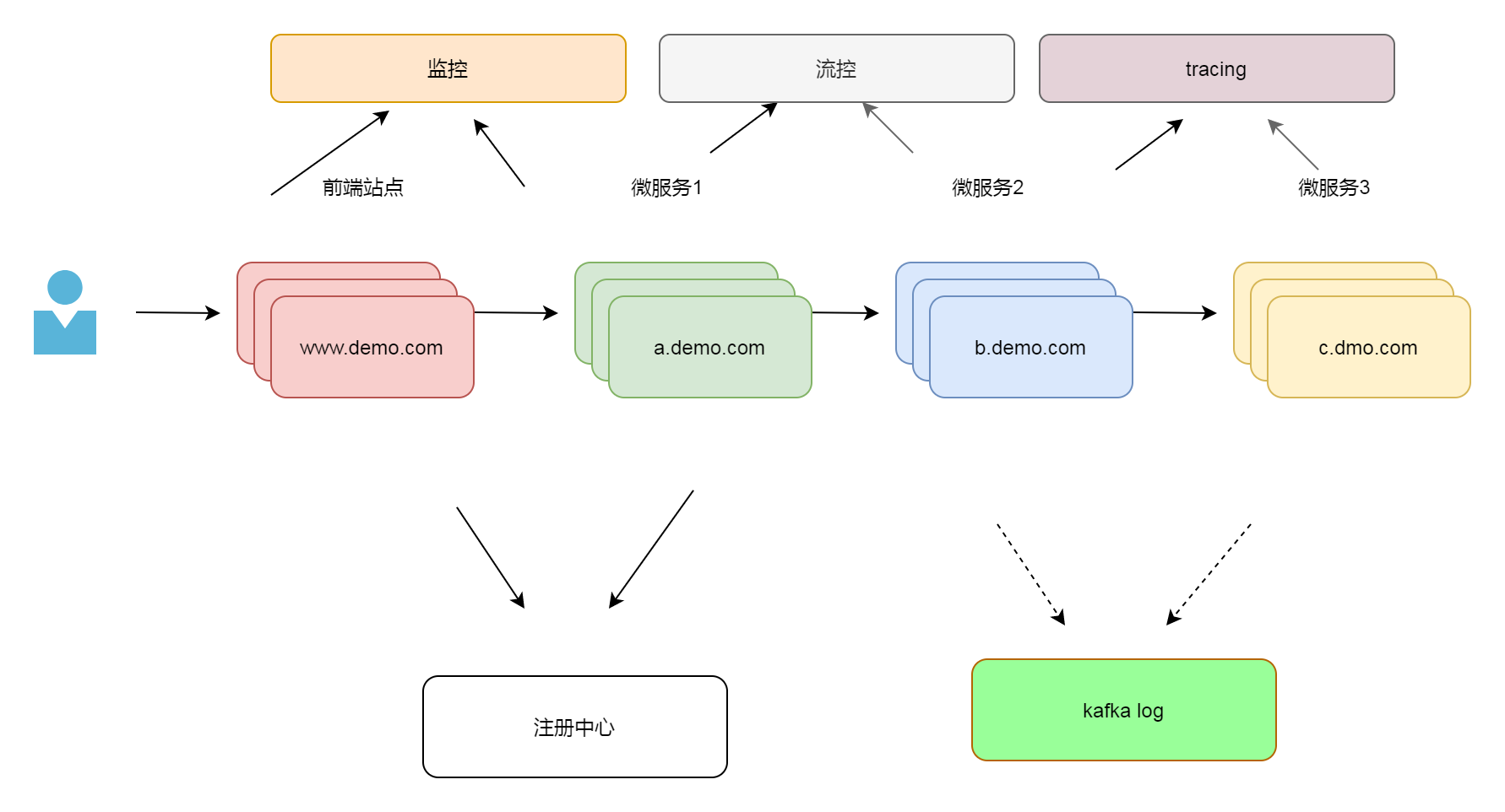
(在实际开发中,其实还有最关键的配置中心(apollo),数据库(db),缓存(redis) 等组件, 服务化网格, 我们可以把这些组件暂时放在kubernetes 之外,仍然是可以起到同样的效果)
好了设计部分,先到这里,开始实现。
第二章:微服务项目的具体实现
从 前端向后端开始实现
2.1 前端站点
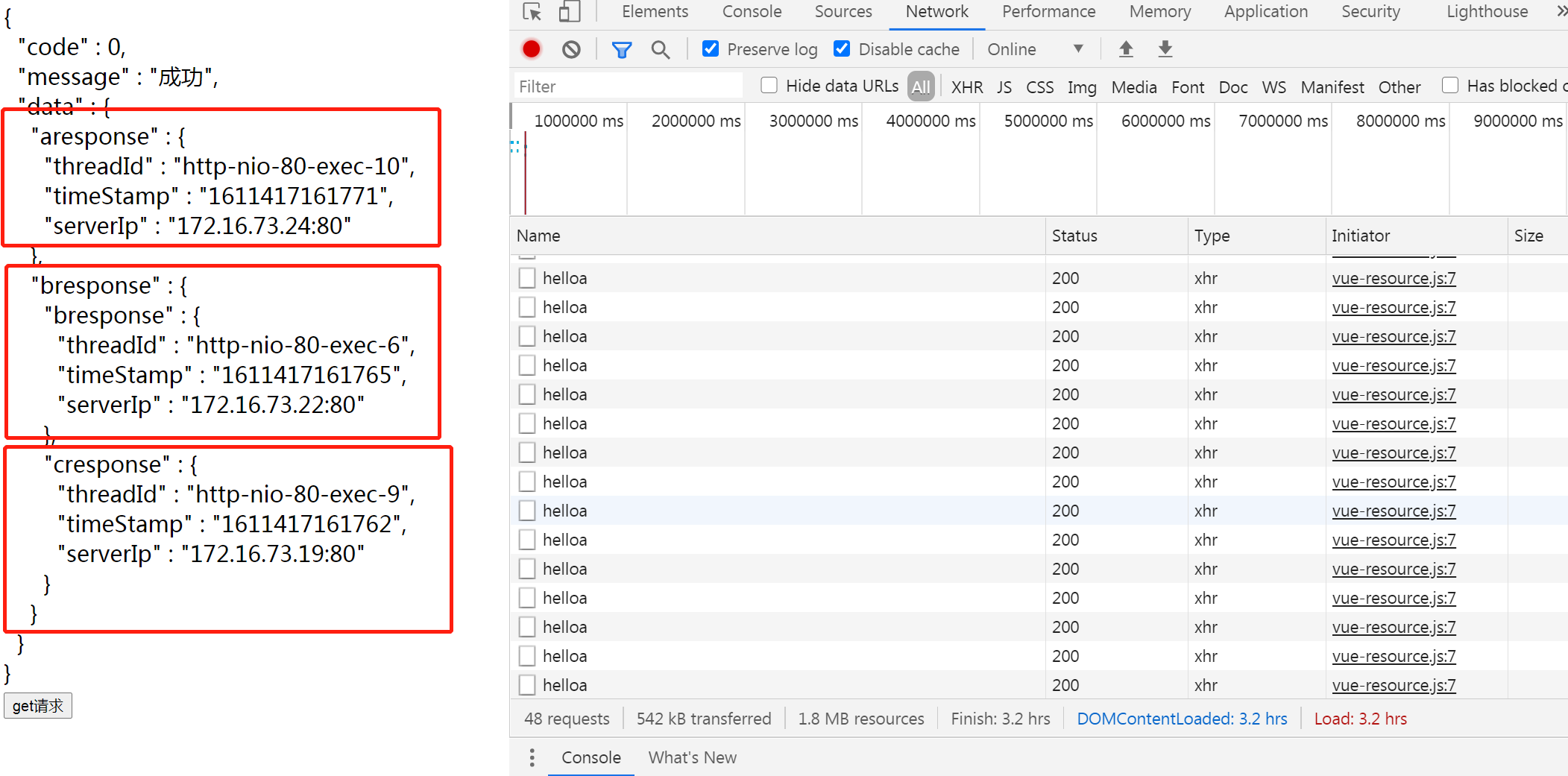
前端站点的逻辑很简单,就是显示一个页面,页面中有一个按键。当你点击按键的时候,前端页面发起ajax请求,访问前端站点本身的一个接口,这个接口被nginx代理,转发到a.demo.com 微服务上,a. demo.com 微服务再将请求转发到b. demo.com, b. demo.com 再将请求转发到c. demo.com. 最终将结果返回给前端。前端站点再将结果显示在页面上。我们通过结果显示,就能知道 这次请求通过了那些服务器,每台服务器的服务运行时间大概是多少。
前端站点代码 大体如下:
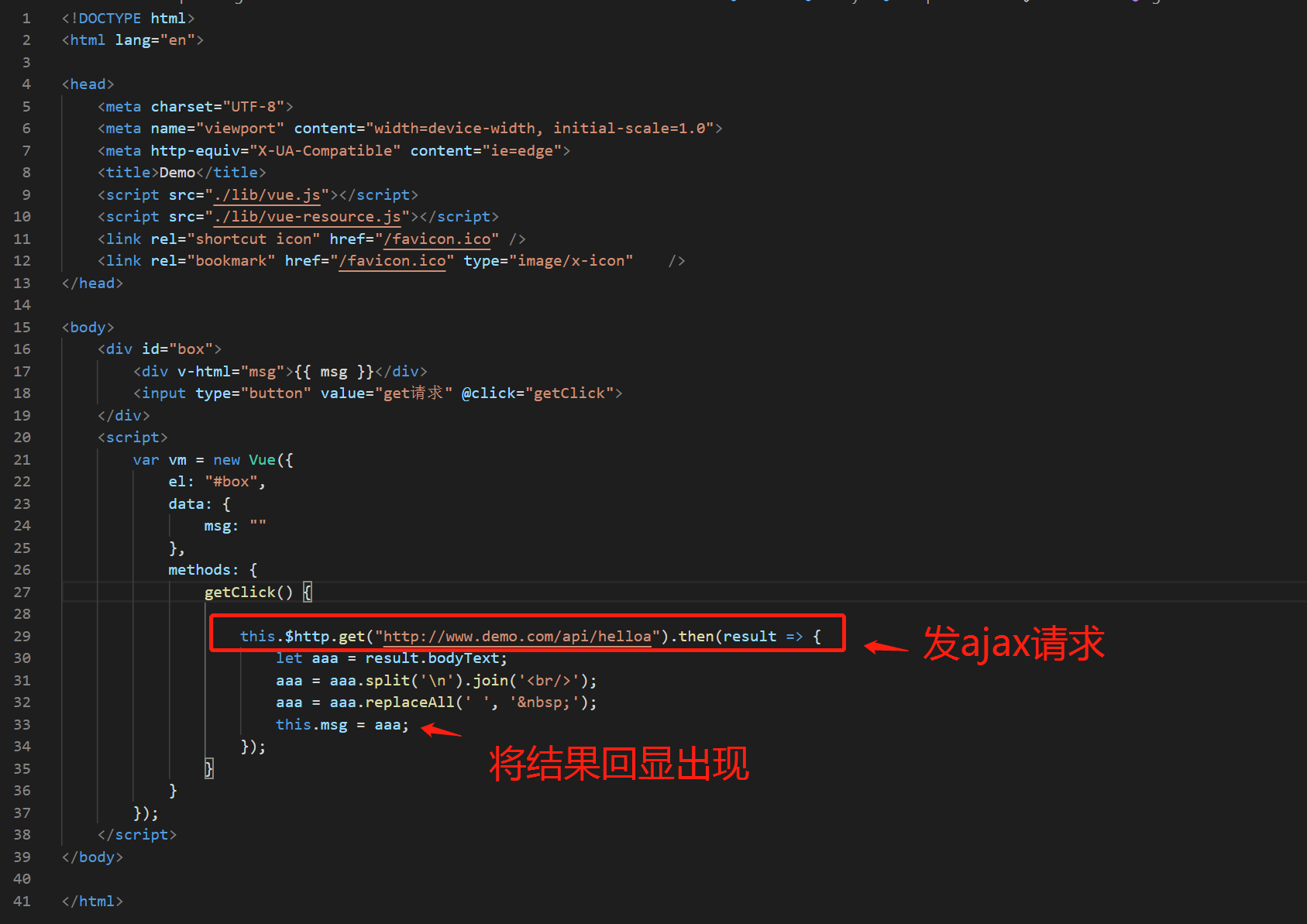
然后看a、b、 c 应用部分的java代码,这就是个普通的多模块Maven项目。
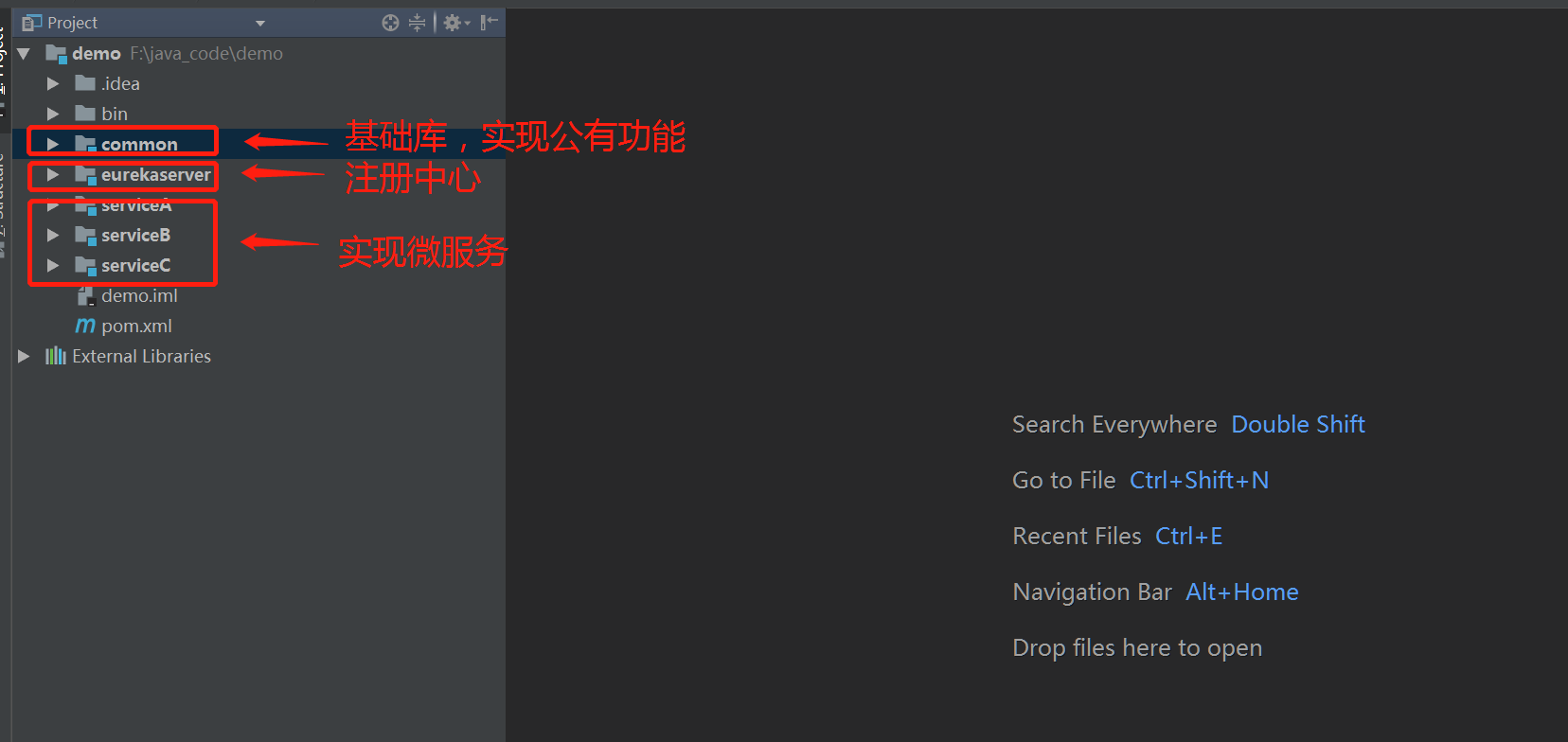
项目很简单,分成了3个部分,一个是注册中心,也就是利用eureka实现注册中心服务,另一个则是基础库项目,大部分功能都在这里实现,最后则是各个微服务项目,微服务项目只需要简单调用基础库就能完成。
2.2 注册中心
注册中心的代码非常简单,只需要加一个简单的声明
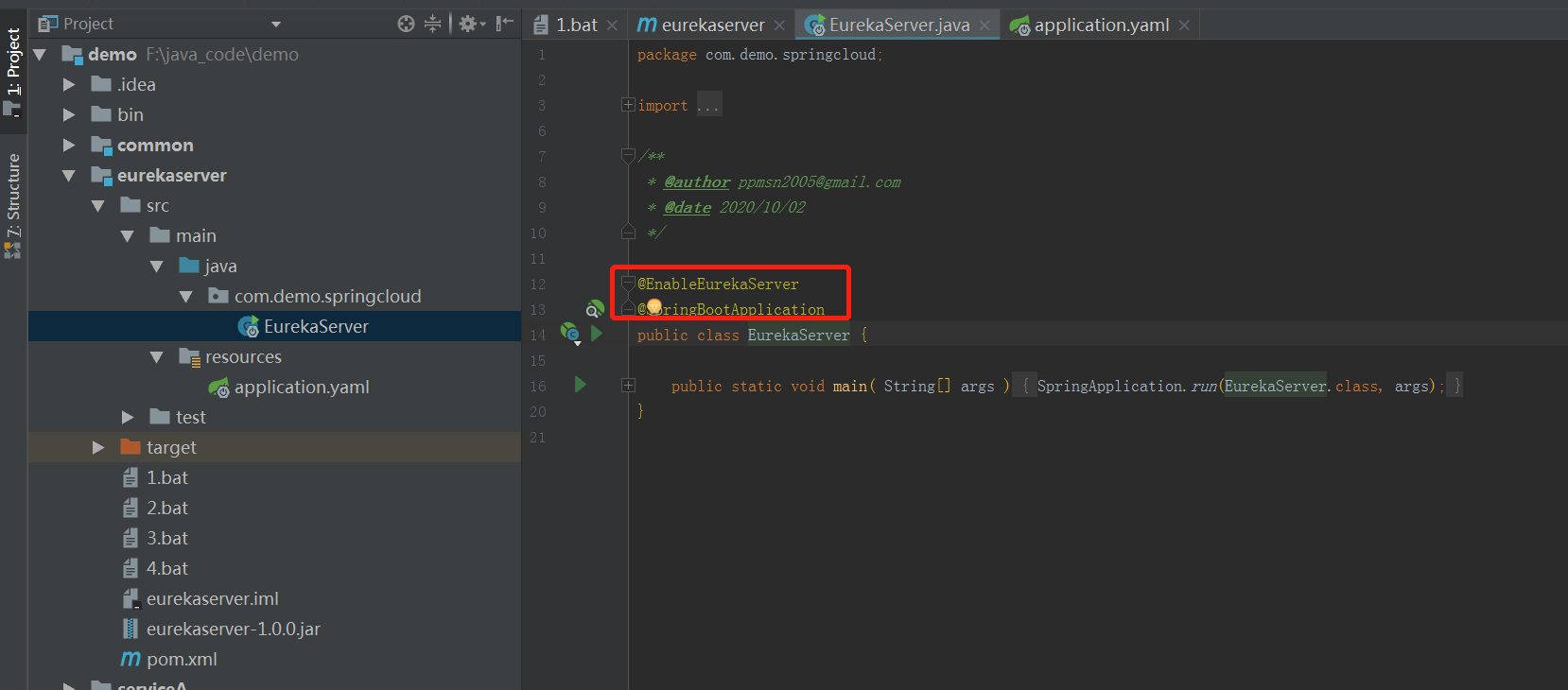
这是注册中心的配置文件,在kubernetes集群里运行时,我们会运行3个节点组成高可用的注册中心集群。这时 这个配置项需要相应的修改。
2.3 基础库
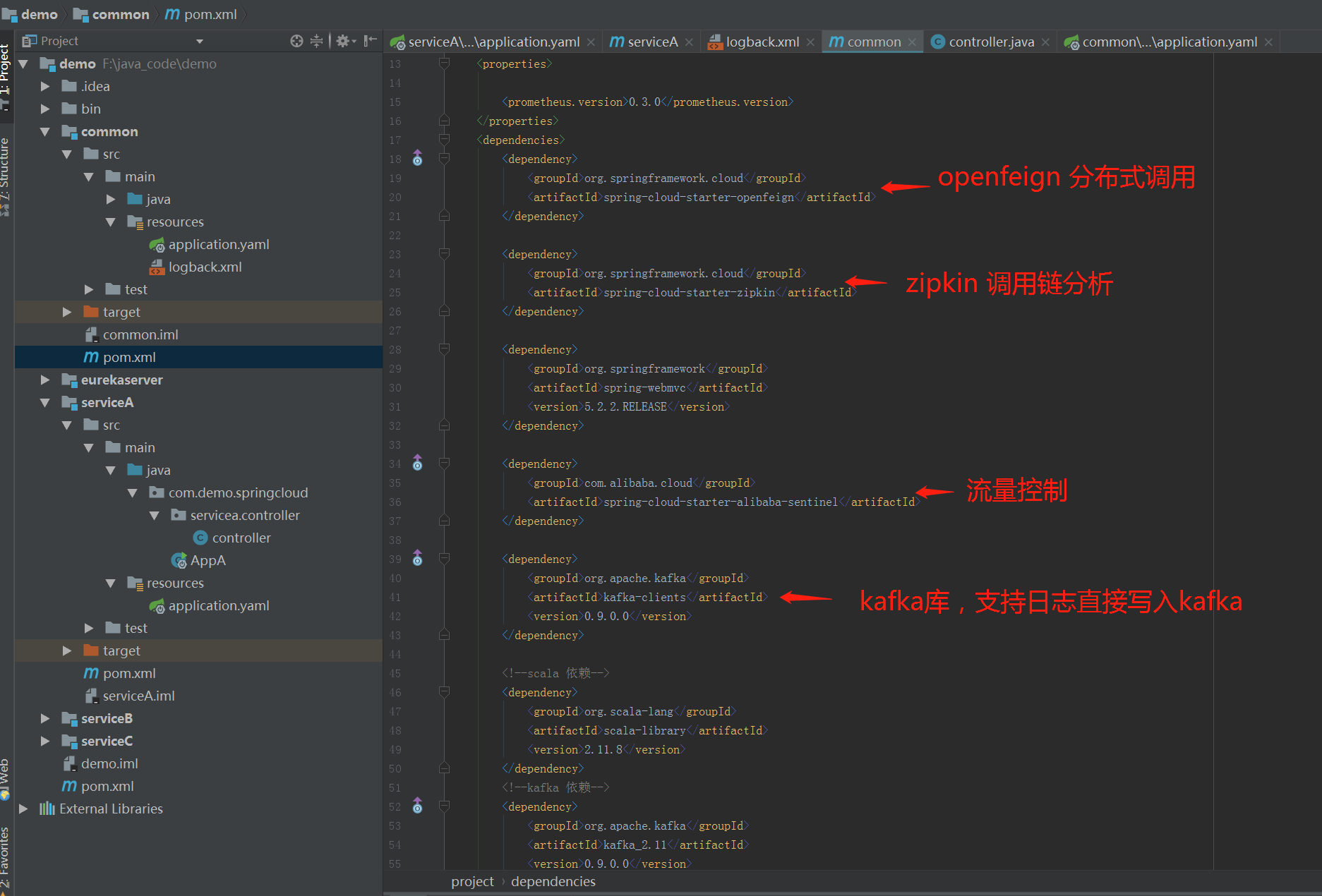
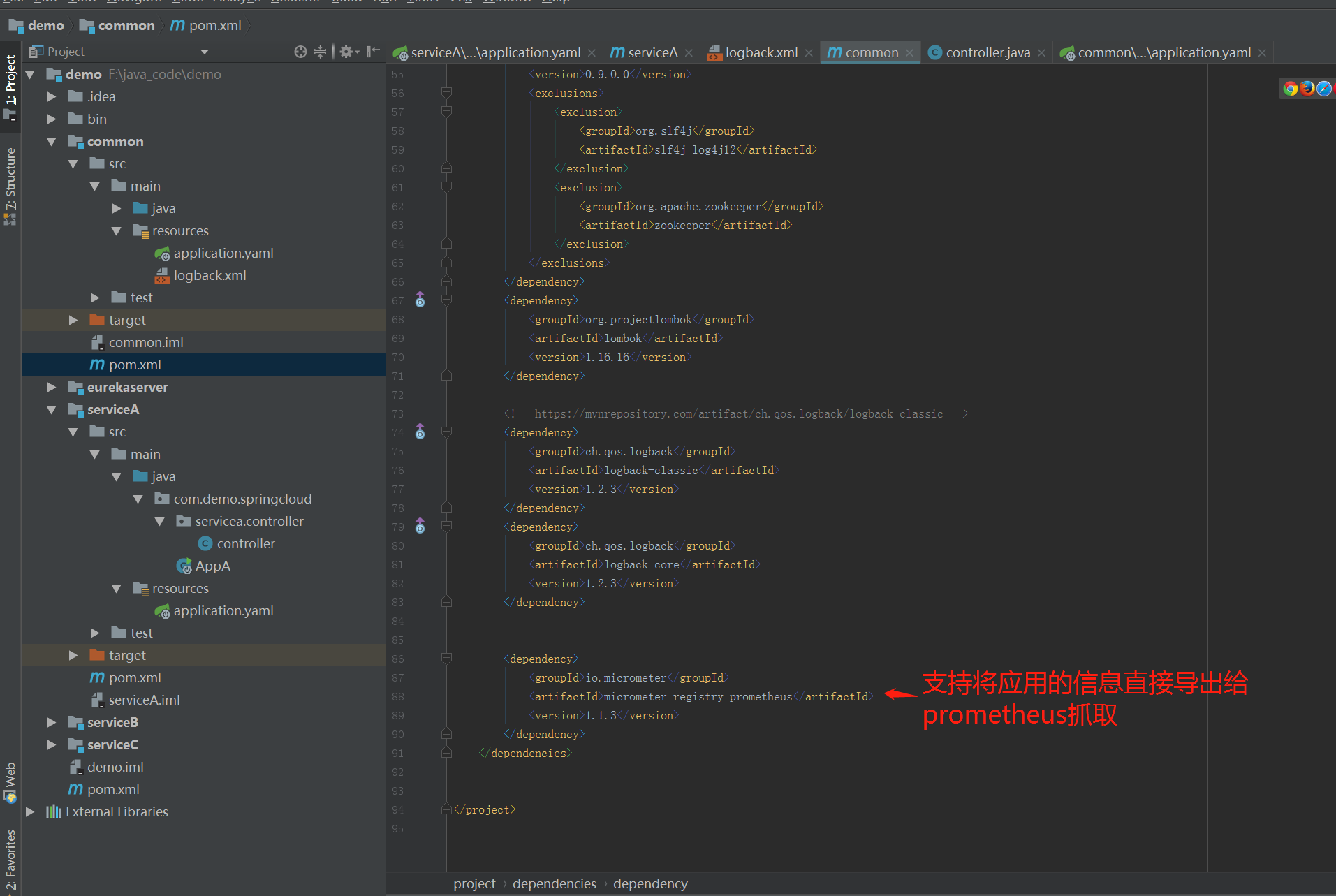
在基础库项目里,我们将很多的依赖都放在里面,这样应用项目只需要简单依赖基础库就可以,能够做到统一修改。
同时我们也可以看到大部分依赖库只需要加入就可以,并不需编写代码就可以工作,这让开发工作变得轻松。
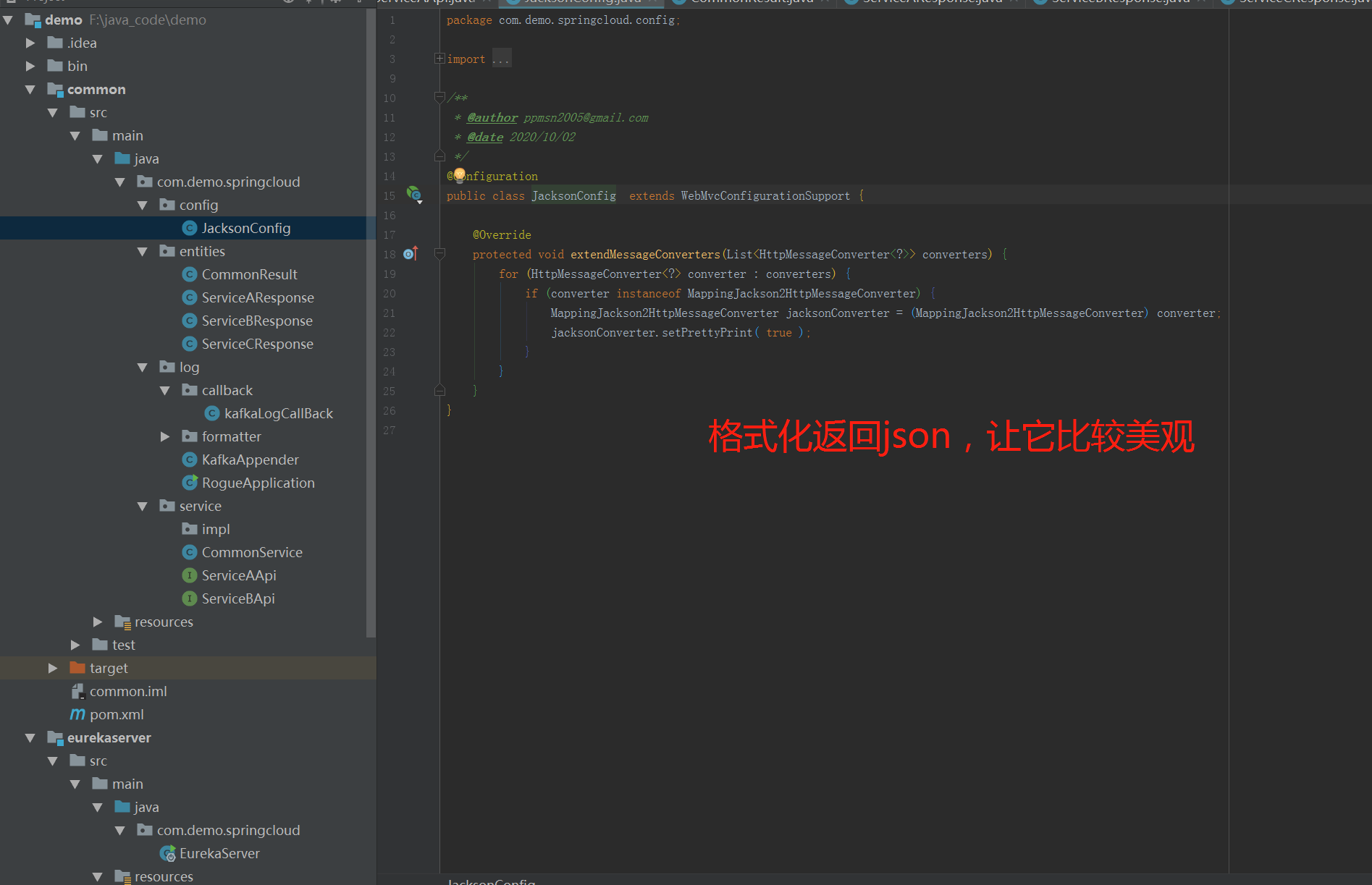
对于微服务的返回结果,我们做了一些美化格式。这样可以在检查结果时,比较容易。
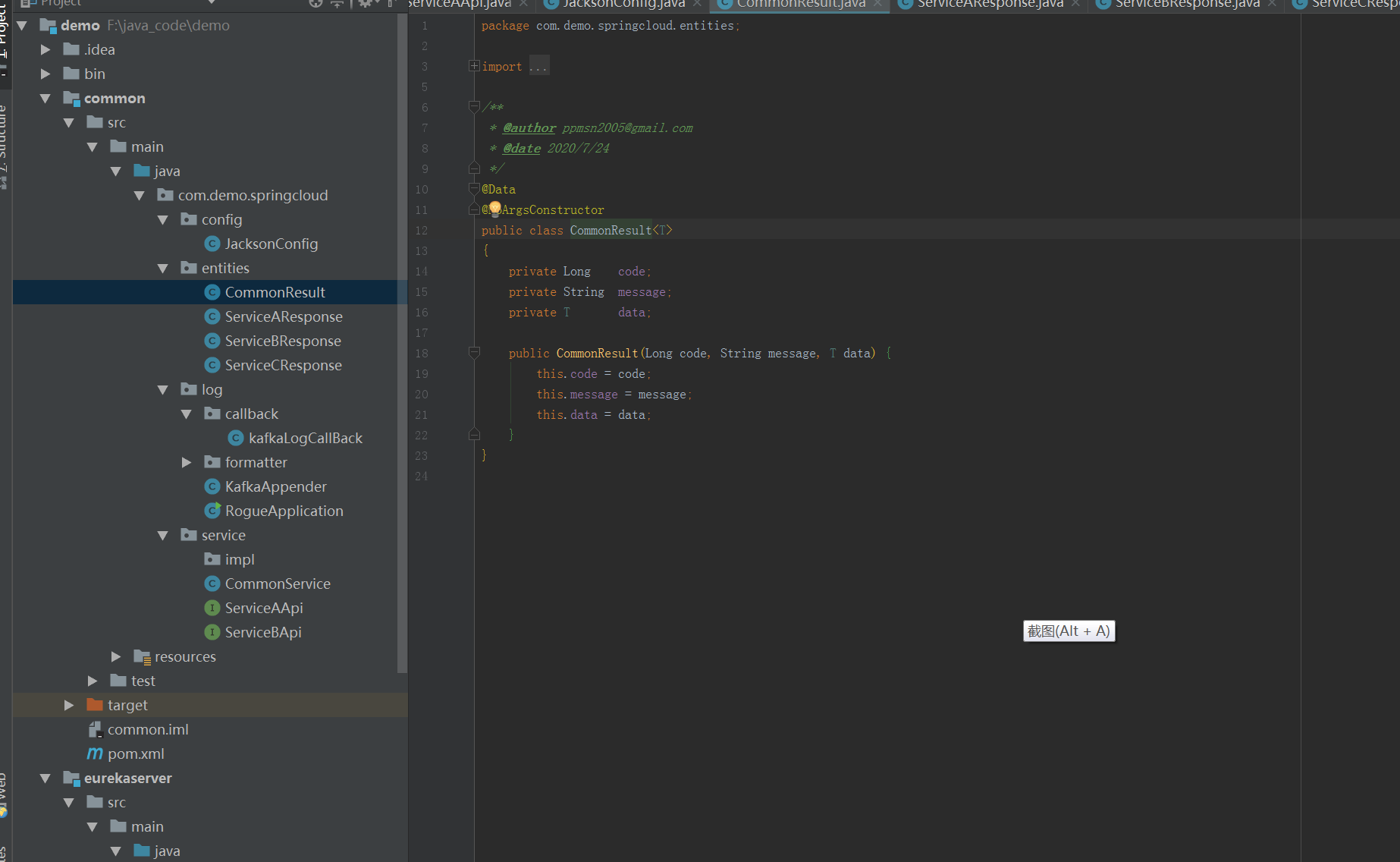
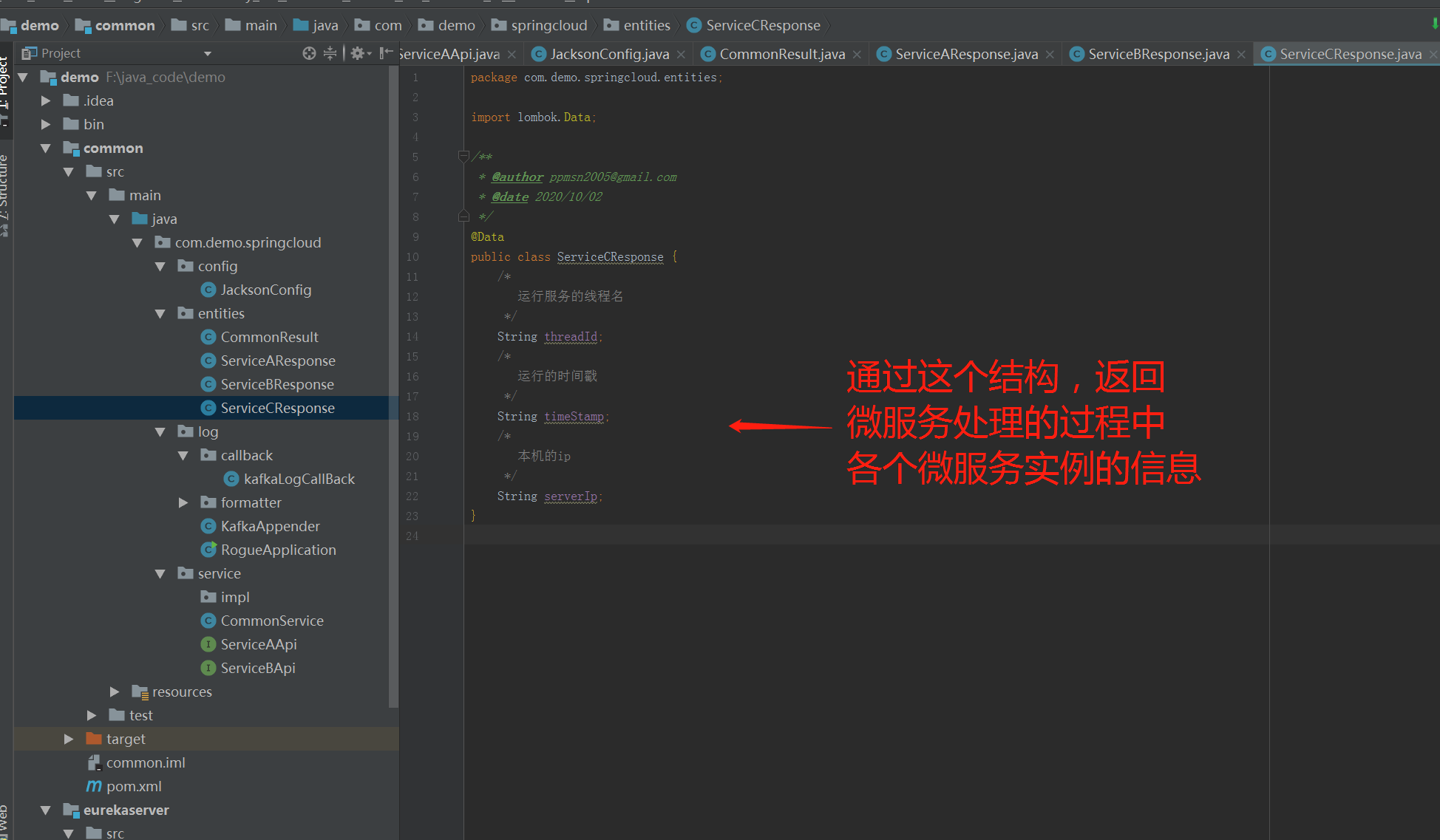
简单的定义了一些返回的结构,可以通过这些结构,微服务可以把处理时的时间戳,线程号,实例ip这些信息返回出来。
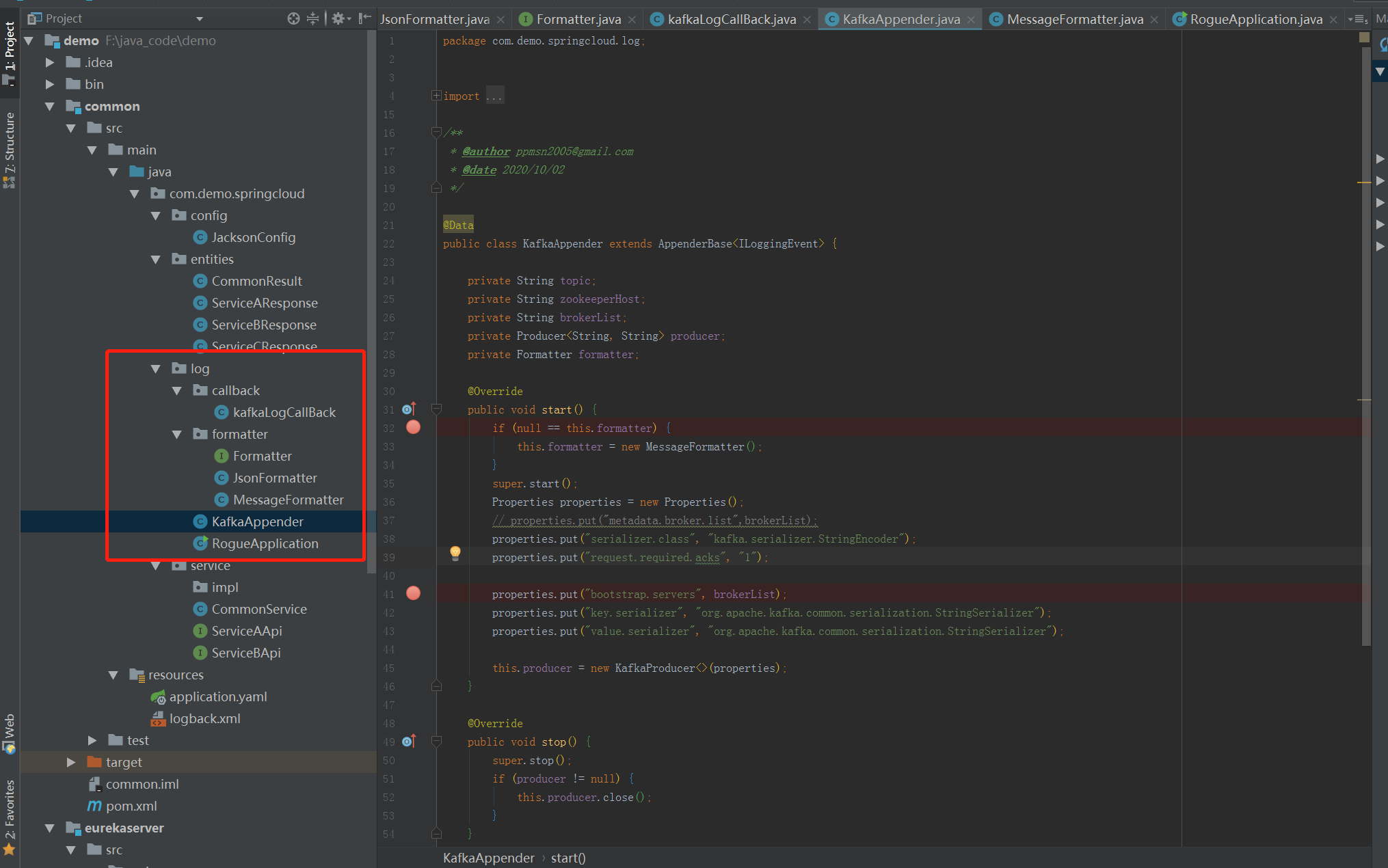
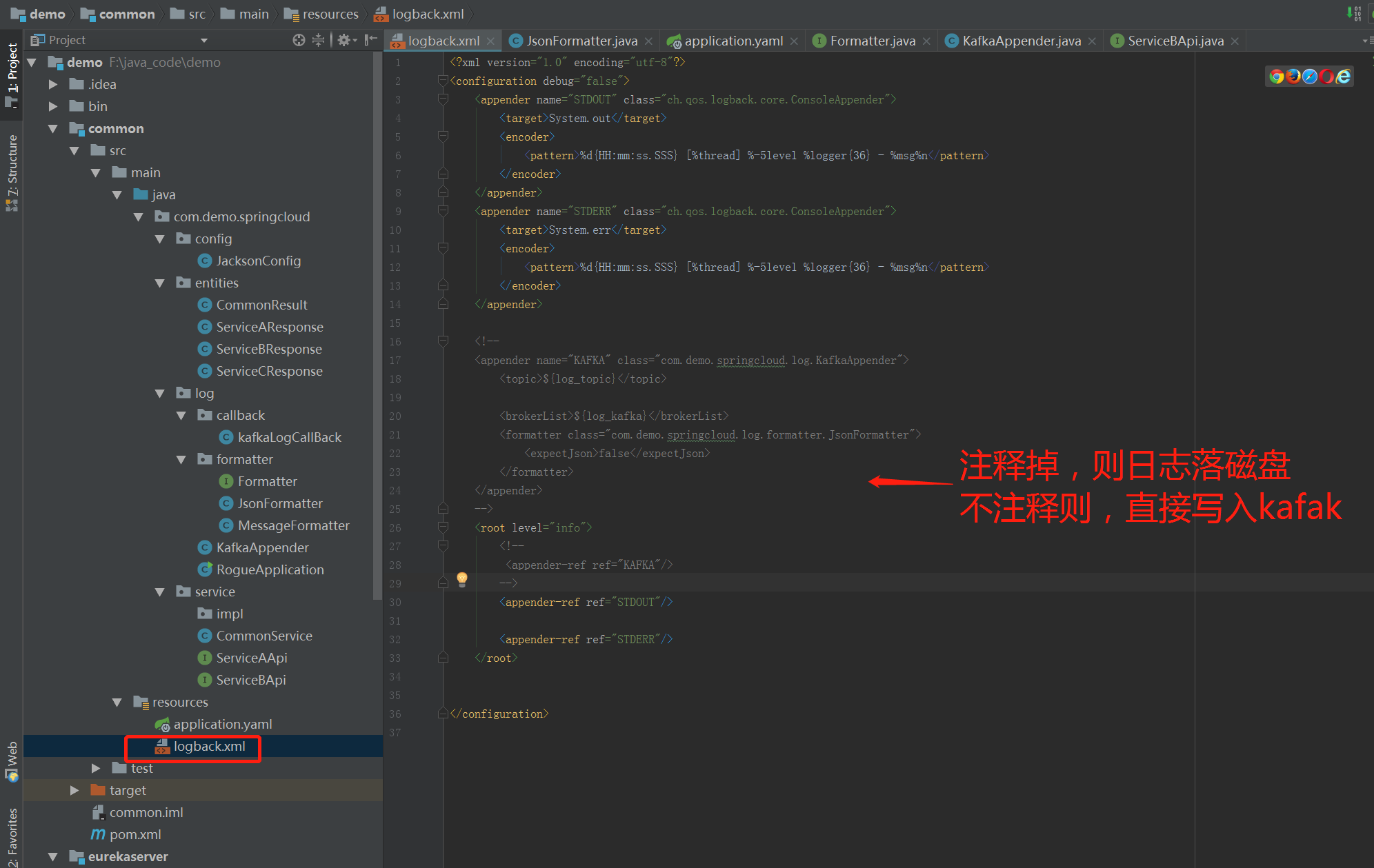
基础模块的日志实现,从github 找的例子简单地进行了修改。(简单实现,不要用于生产)这时我们利用logback.xml 的配置,可以选择我们是把日志写入本地磁盘还是直接写入kafka.
2.4 a.demo.com b.demo.com c.demo.com 应用实现
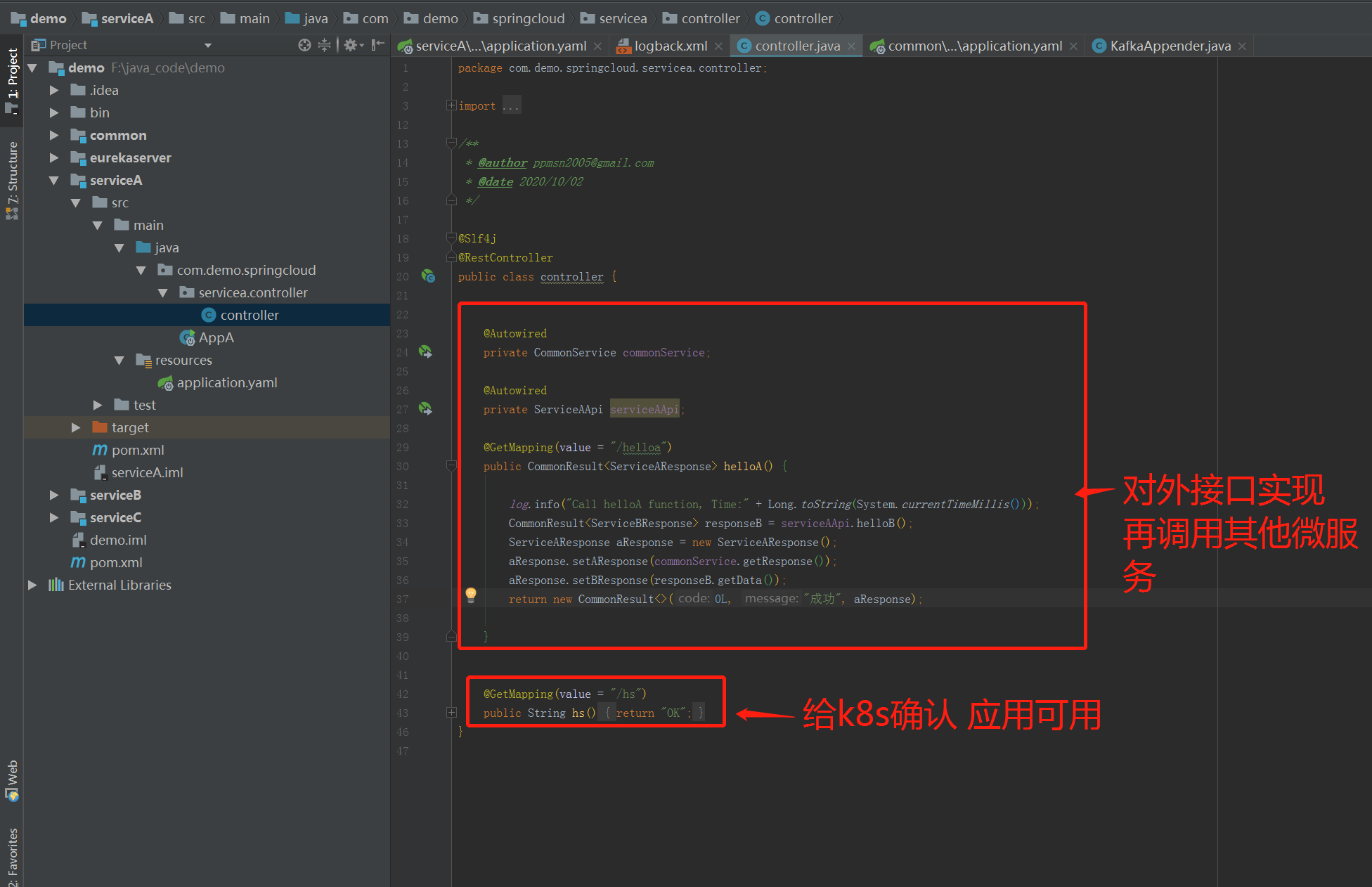
实现很简单,只是简单地调用基础库就可以了。注意 每个应用需要实现一个探活接口 /hs. 这样kubernetes 系统可以通过这个接口来探活,获知你这个应用是不是准备好了,能不能接入流量。否则 你这个应用可能还在启动过程中,但是流量已经接入了,那么肯定会出问题。
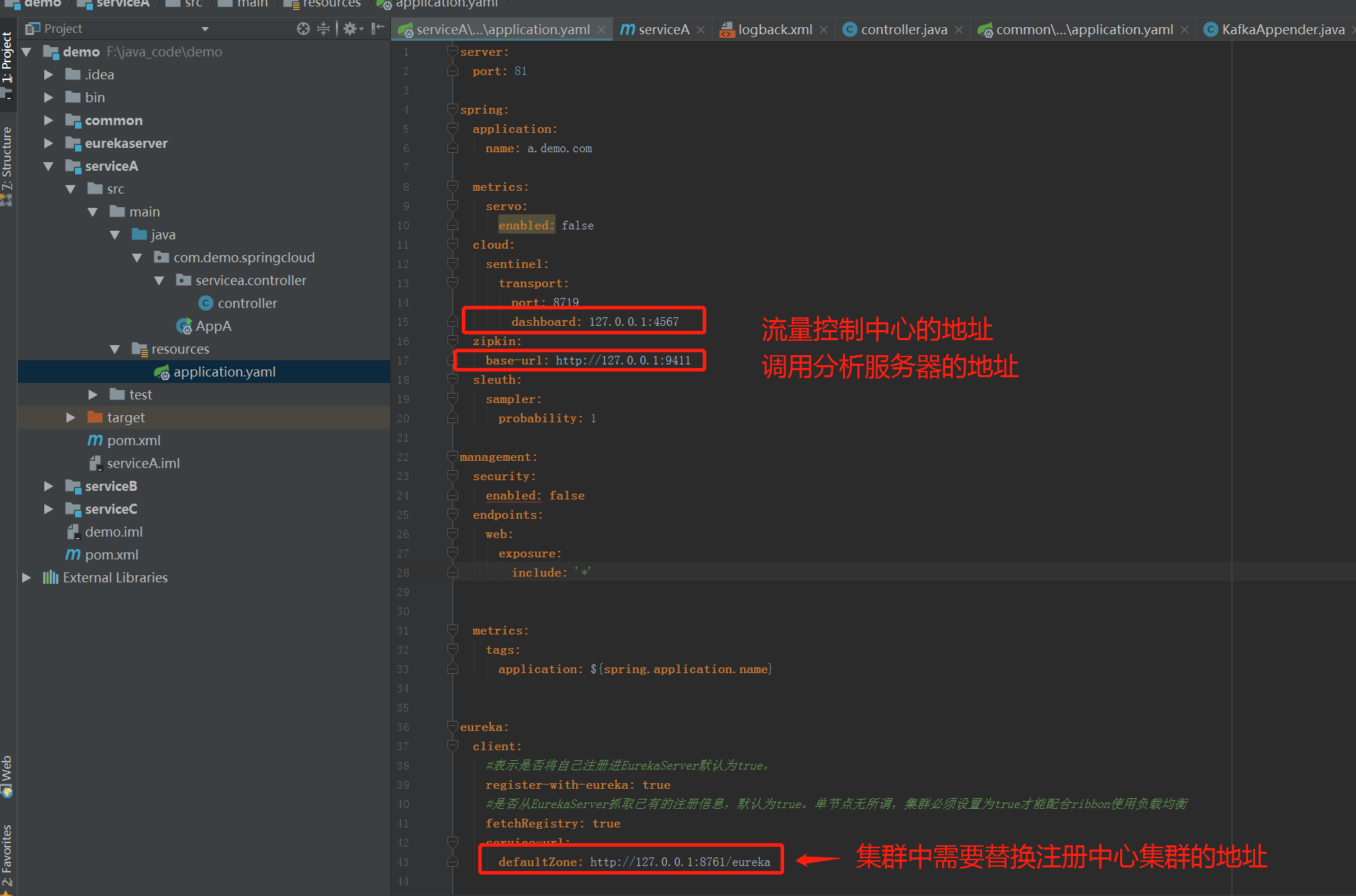
在每个应用的配置里,我们都预置了各个配置的项目,在本地运行的时候,我们可以填注入本地的配置,在kubernetes 里 以容器形式进行运行,我们可以利用yaml来动态地修改它们,做到2种情况下完全兼容。
第三章:kubernetes的部署
在完成应用的编写后,我们需要安装kubernetes系统了,如果已经有kubernetes 集群的,就可以直接跳过这个部分了,请看下一章。除了kubernetes 集群以外,你还需要Prometheus and Grafana这样的监控组件。所以这里我推荐一个牛逼的安装工具,和所有现有的Kubernetes 安装工具比,它是最好的,没有之一。
它的名字是 K8seasy, 它的优点在于
\1. 可以一键安装整体kubernetes 系统,无需了解任何背景知识
\2. 所有的镜像都已经内置,不会因为下载镜像失败而导致失败
\3. 安装支持各种不同版本kubernetes版本
\4. 安装的服务是二进制版本的,非容器版本, 稳定高效
\5. 支持安装3节点 高可用的生产环境集群
3.1 安装过程
下载K8seasy
官方主页
https://github.com/xiaojiaqi/K8seasy_release_page
演示的安装动画,安装就是这么简单

安装下载页
http://dl.K8seasy.com/
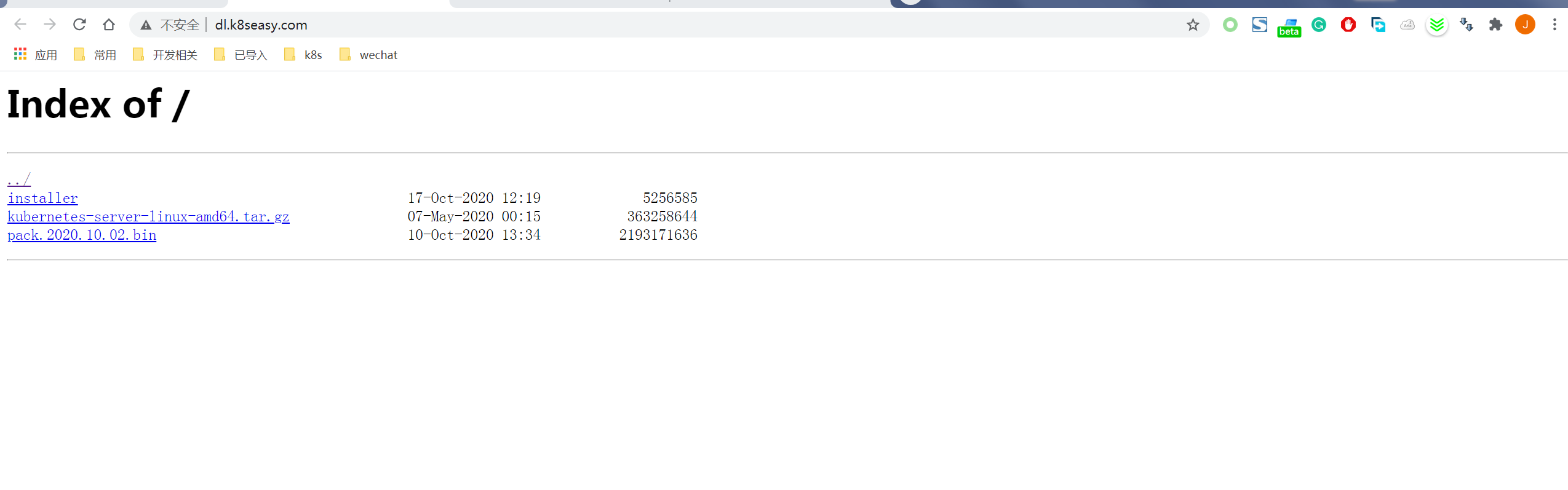
将3个安装文件都下载下来, 其中 pack.2020.10.02.bin 和installer 都是安装文件, kubernetes-server-linux-amd64.tar.gz 是kubernetes 的官方软件包,你可以自己选择一个最新的版本。
如果要选择一个其他版本的kubernetes
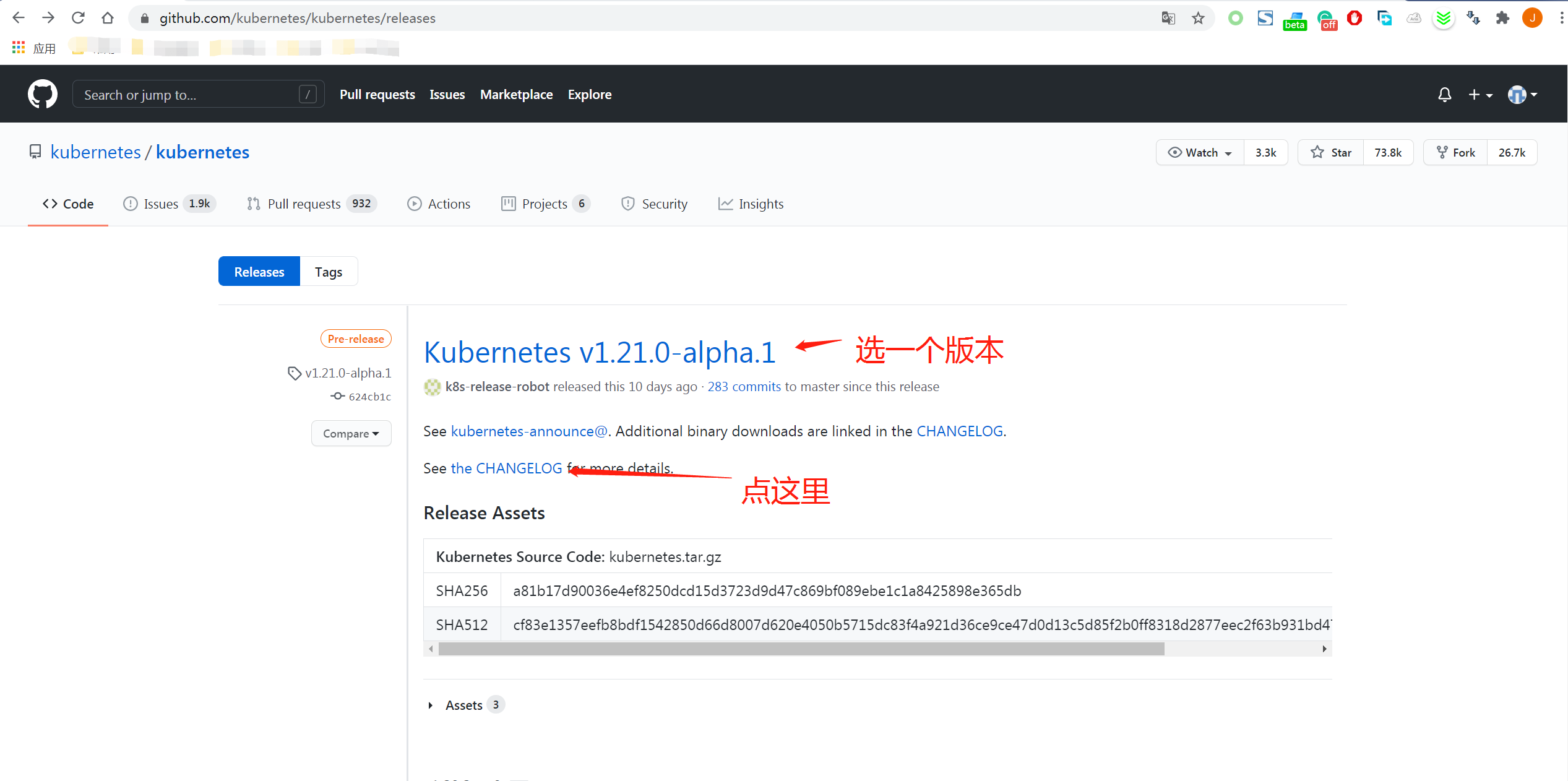
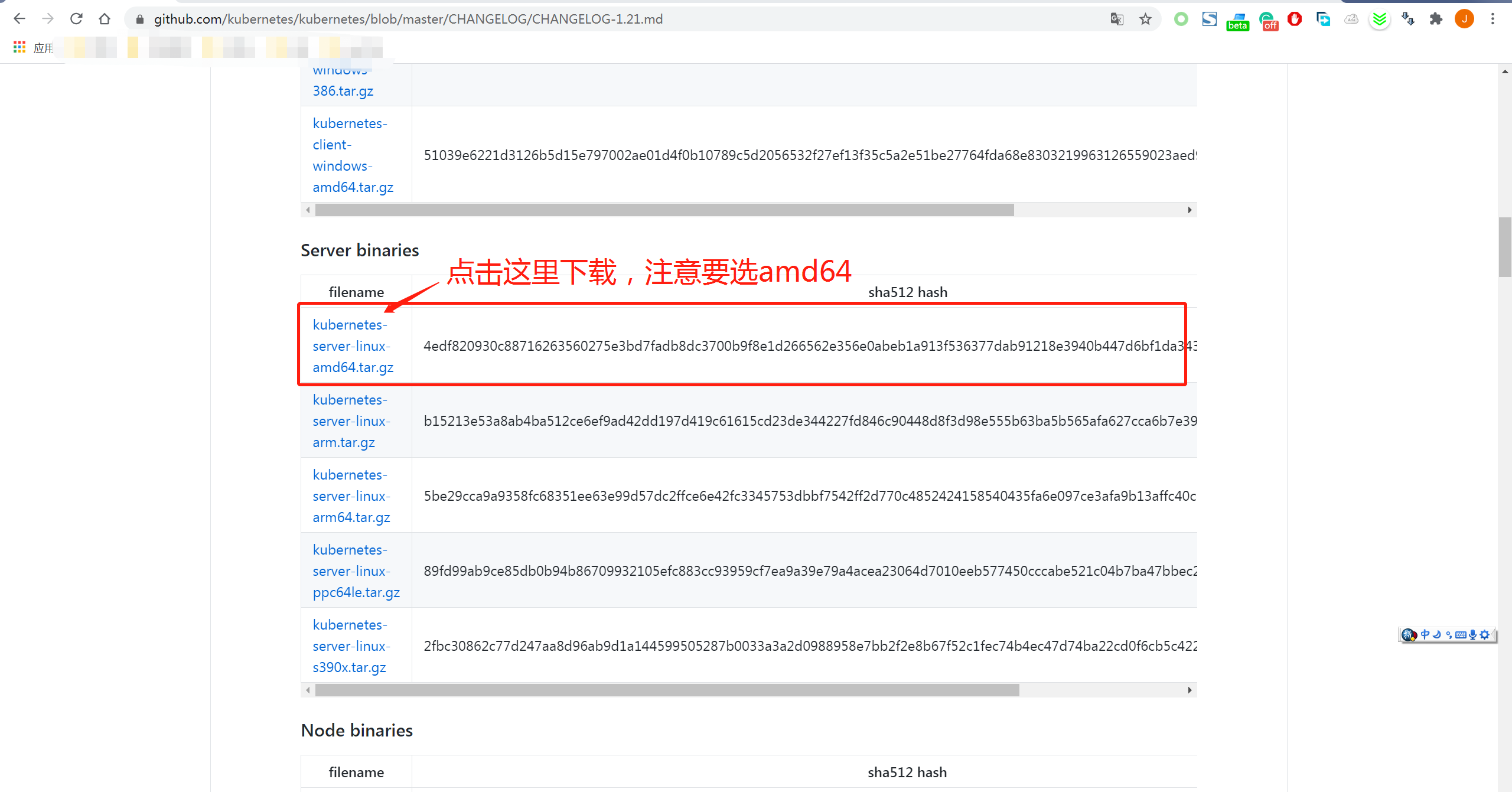
安装的过程很简单,2条命令即可
这里我们假设 需要安装Kubernetes的网络为 192.168.2.0, master 主机为192.168.2.50
1 创建密钥
sudo ./installer --genkey -hostlist=192.168.2.1
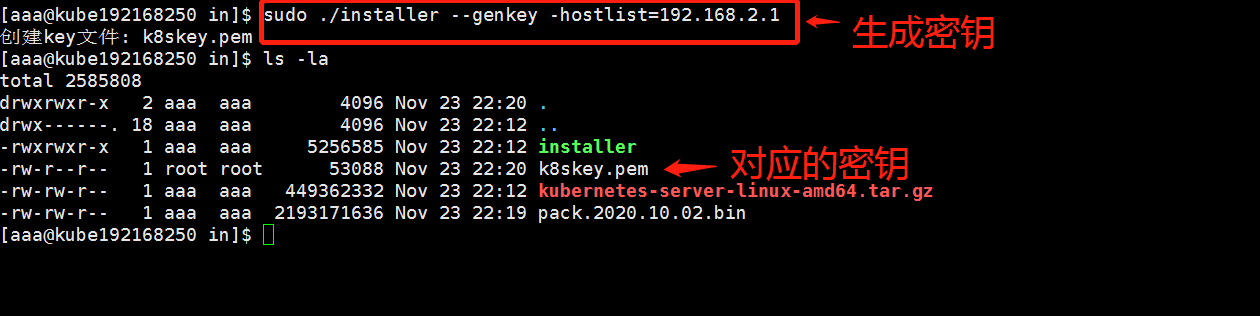
2 创建集群
sudo ./installer -kubernetestarfile kubernetes-server-linux-amd64v1.18.2.tar.gz -masterip 192.168.2.50
稍等一会儿 就能看到类似如下输出
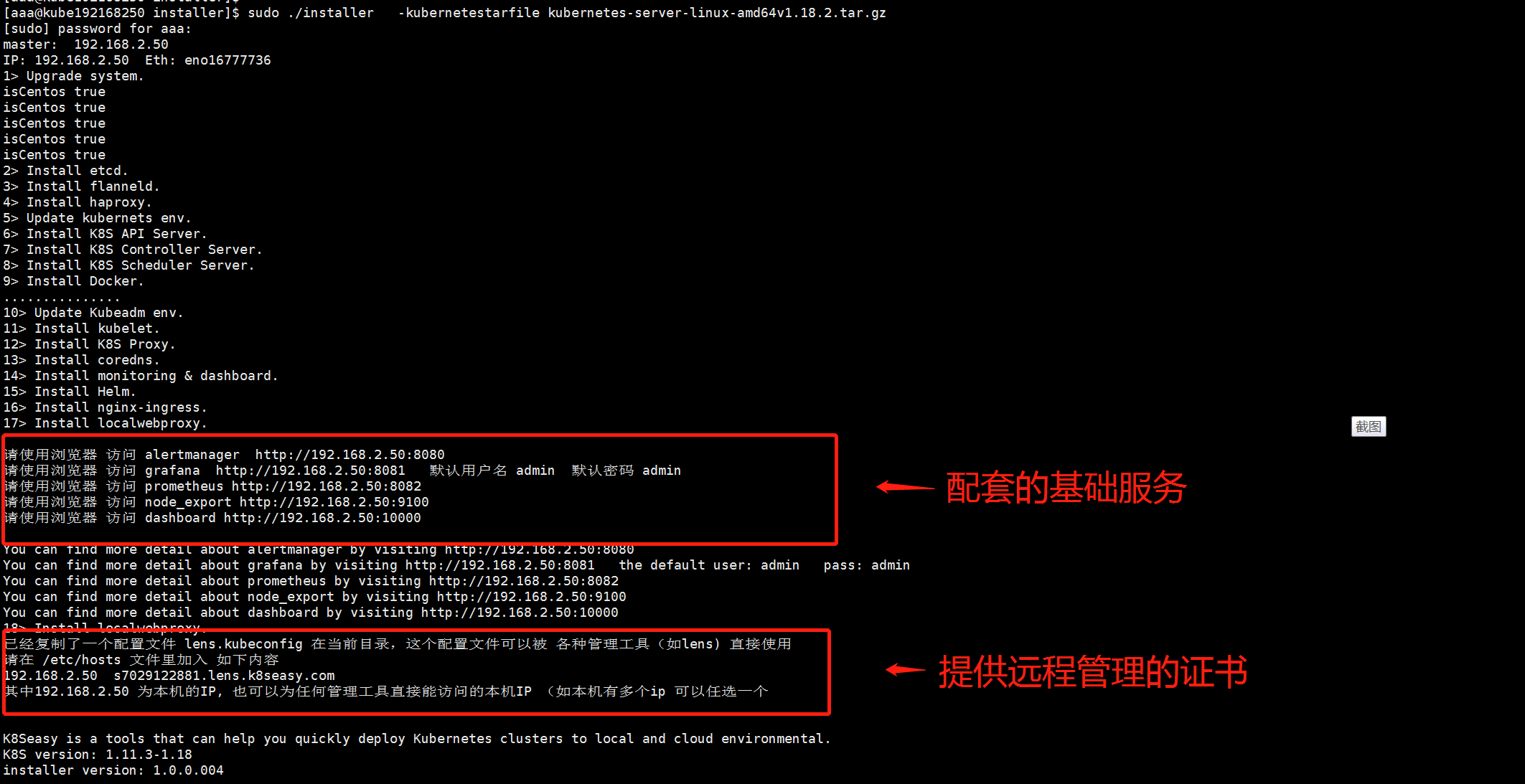
就这么简单,一个Kubernetes已经装好了。
此时相关的所有监控已经被完全安装好了。
3. 各项监控
\1. 以master 节点为 192.168.2.50 为例子
http://192.168.2.50:10000 可以直接打开dashboard, 对整个集群有一个全面了解
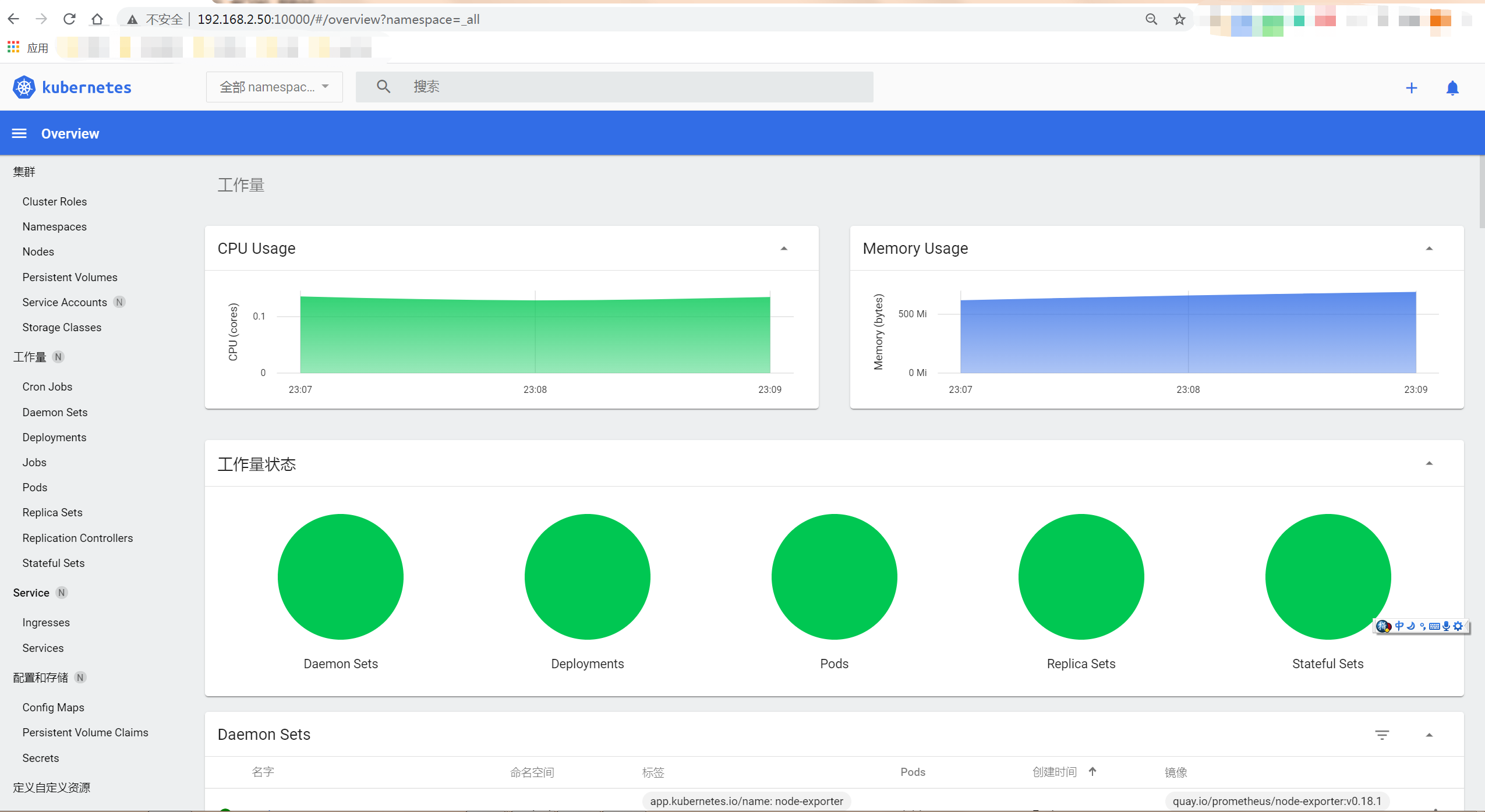
打开 http://192.168.2.50:8080 可以直接访问alertmanager
打开 http://192.168.2.50:8081 你可以直接使用 Grafana (用户 admin, 密码admin)

打开 http://192.168.2.50:8082 你可以访问 Prometheus.
所有的配套都已经安装好了。
4. 多套环境监控
这一切就完了吗?当然不是,为了支持多集群管理,再推荐一个工具。刚才我们说到直接使用 http://192.168.2.50:1000 这个页面可以直接管理整个集群,但是在公司里如果有多个集群,该如何管理呢? 别担心,K8seasy 已经有对应的解决方案
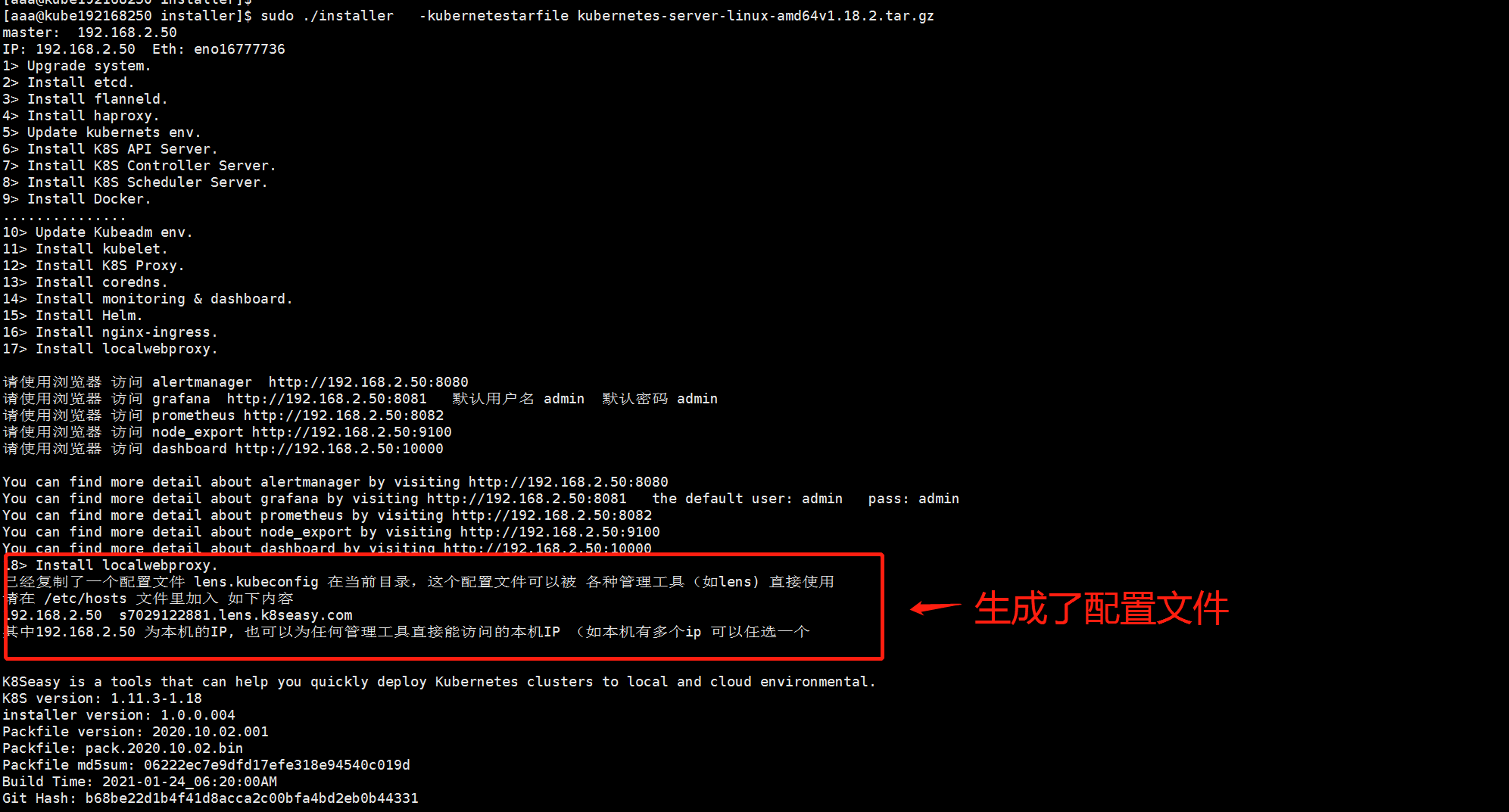
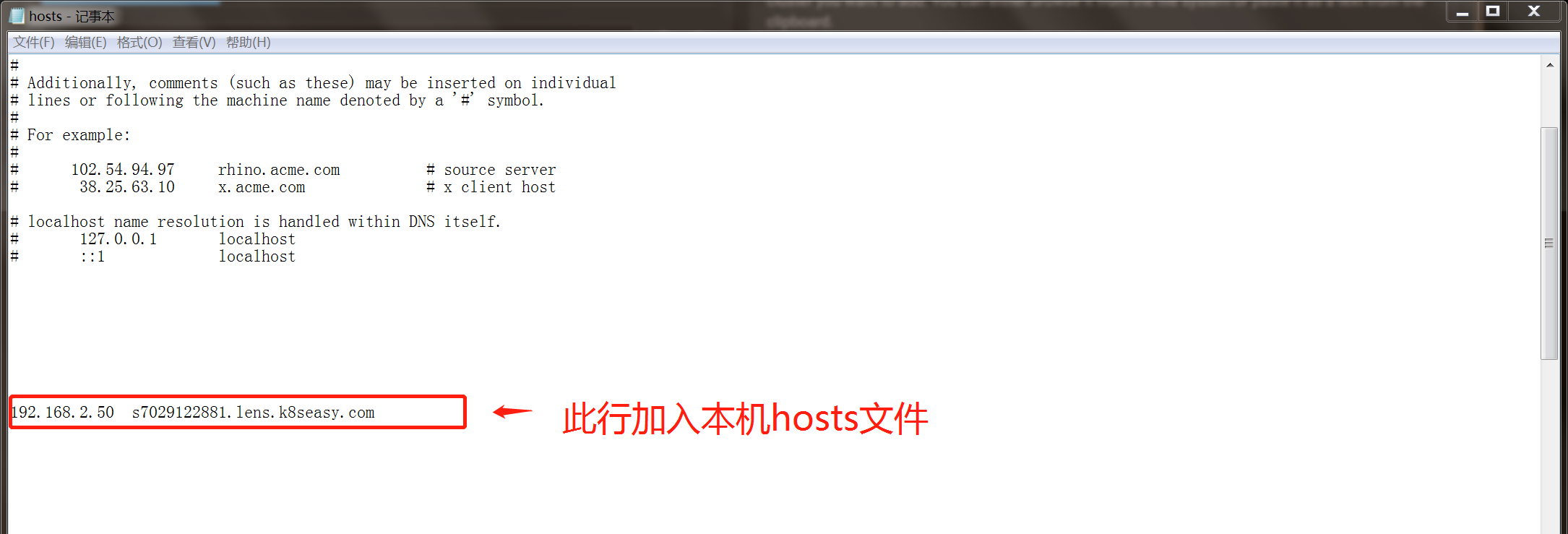
仔细看刚才的安装好的日志,里面提示你 专门生产了一个 lens.kubeconfig 的配置文件, 并且有一个 域名和 ip 的对应表。 这时候,你只需要 首先在本地Host 文件里加入 这个对应
然后去 Lens | The Kubernetes IDE (Kuberneteslens.dev) http:// https://Kuberneteslens.dev/
下载一个lens的安装包。安装lens以后,你只需要将lens.kubeconfig 导入到lens里,
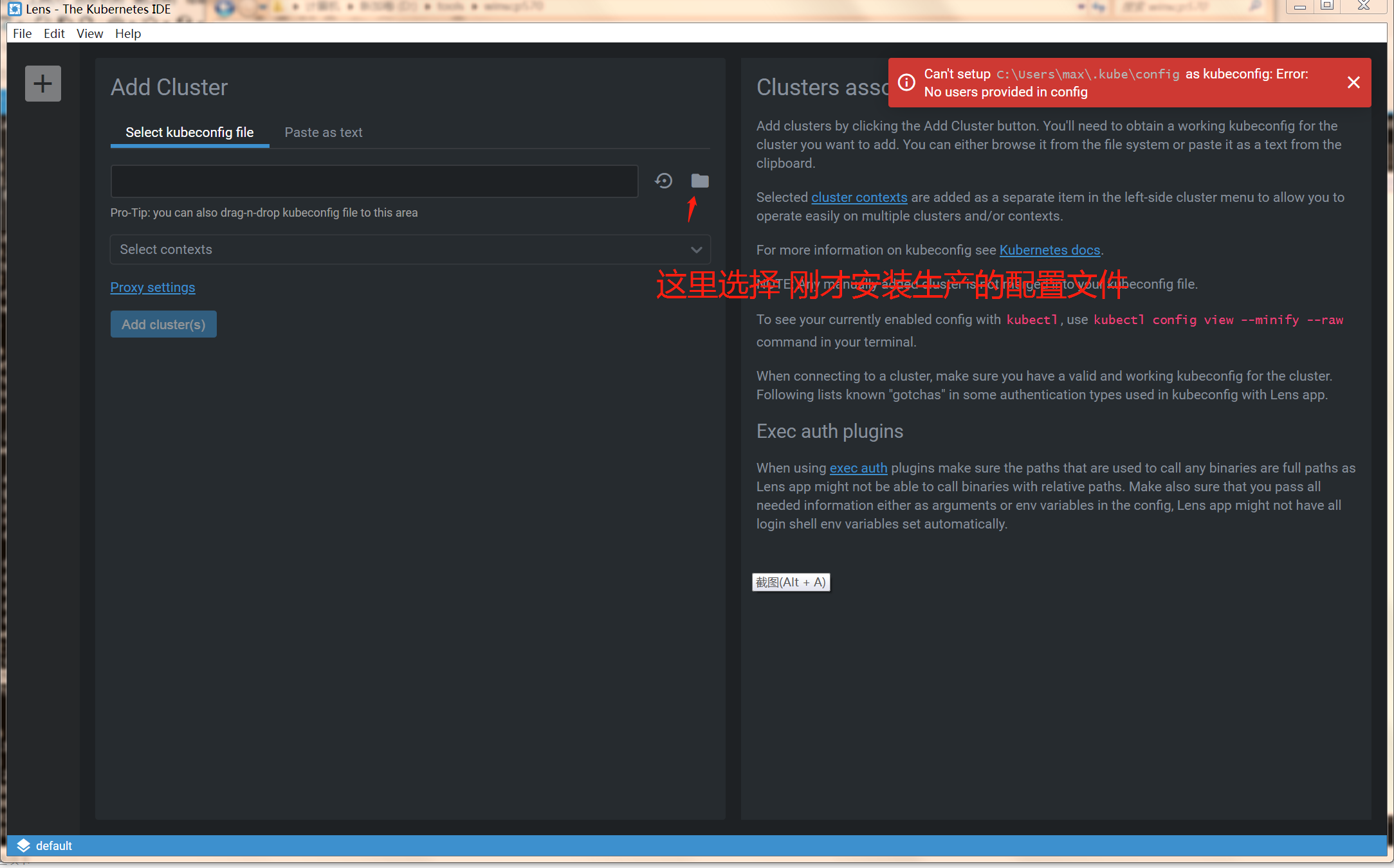
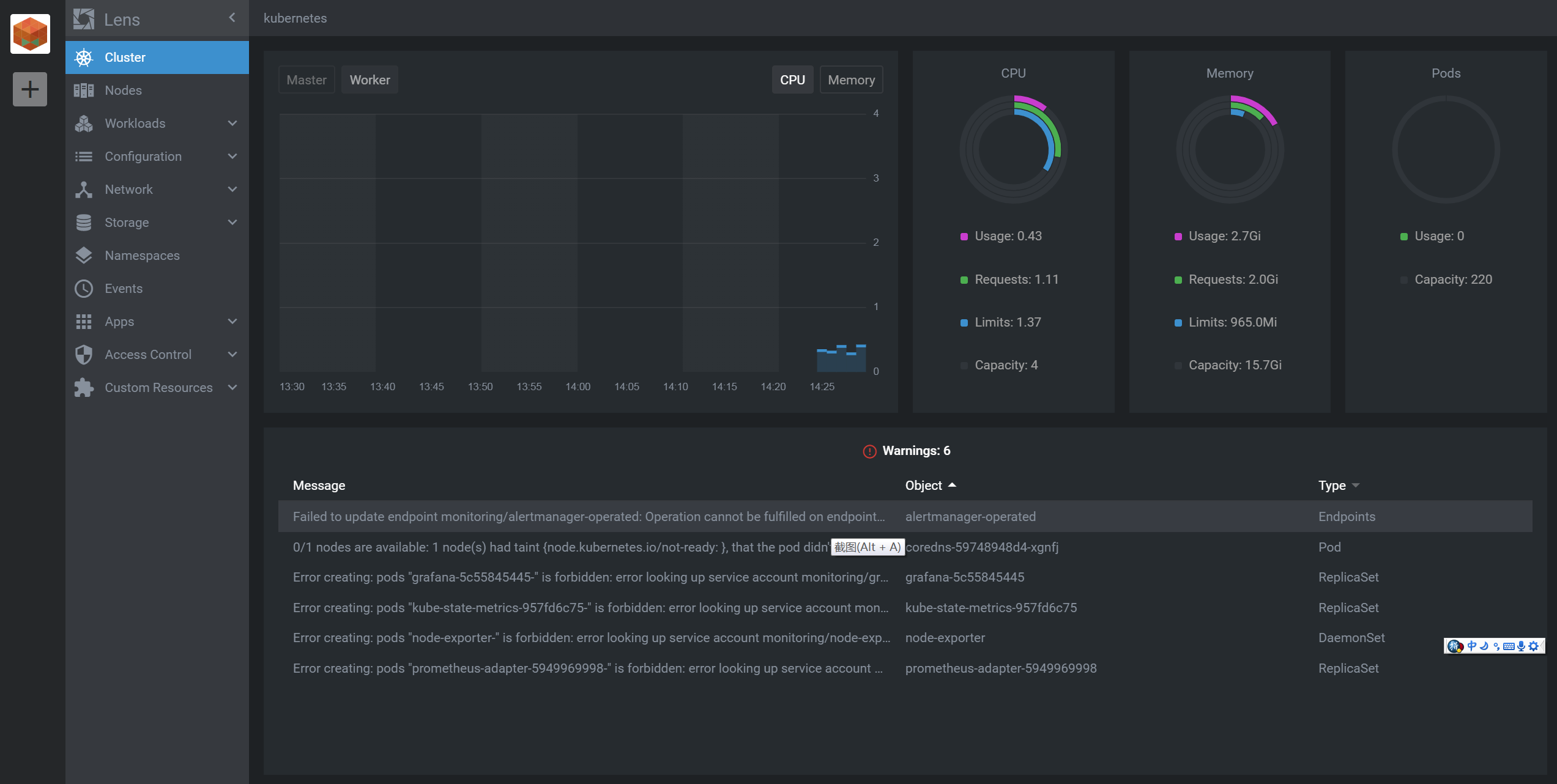
导入完成后,你就可以远程管理这个集群了。这样有多个集群,你也可以只用一套lens 进行管理了。
Lens的界面优美,使用方便,快试试吧。
好了 Kubernetes 的安装完成了。当然了K8seasy 的功能是非常强大的,你可以用 sudo ./installer -h 查看帮助, 也可以使用 sudo ./installer -demo 查看各种场景的安装帮助。
第四章:微服务高可用部署及验证
Kubernetes 装好了,现在开始将微服务部署上去了。我们刚才的代码只是Java 源码,我们还需要将它们编译成Jar包,然后再打成docker 镜像才能部署,这部分比较简单,所以我不演示如何完成了,我将相关的Dockerfile 和 最终Yaml 都放在Github 里了,在开始开发时,我提到将日志写入Kafka, 所以有2套配置,一套使用了Kafak 一套没有使用Kafka。 请注意区别,有因为没有Kafka 比较容易实施,我这里就演示没有Kafak的版本。这样所有只要有一台Linux 就可以保证将整个流程实施成功。
4.1 服务部署上去。
依次运行每条部署Yaml的命令即可,不需要做其他的操作。
注意,镜像在Docker-Hub, 可能需要一定时间能下载。
运行后在 Dashboard 查看,你可以看到类似的信息,所有的服务都已经成功运行。
查看Dashboard
此时修改你本地的Hosts
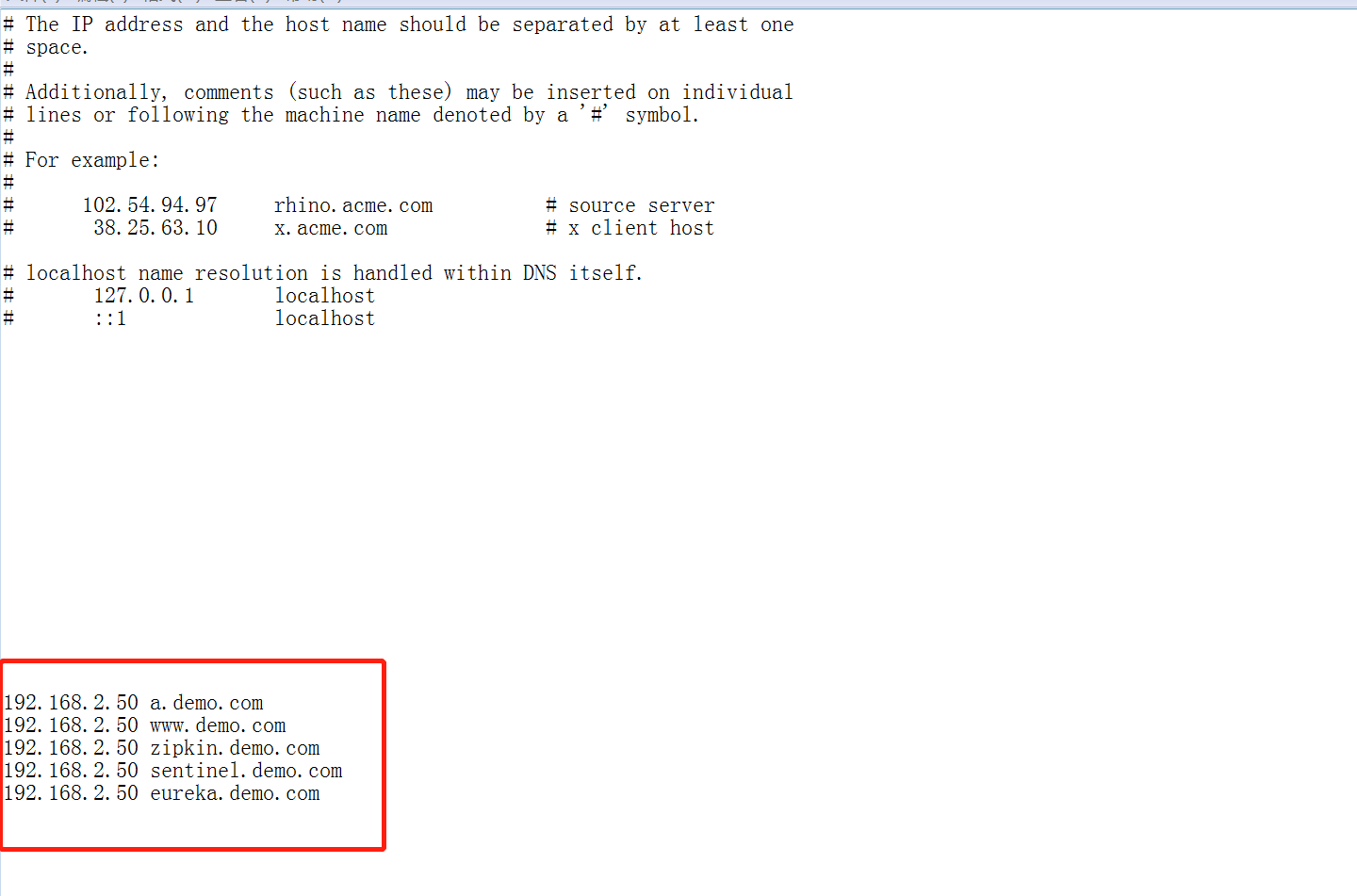
这样的话,因为我们的Kubernetes 是支持 nginx-ingress的,所以你可以直接访问Master的物理IP来访问这些服务,不需要做任何转换。
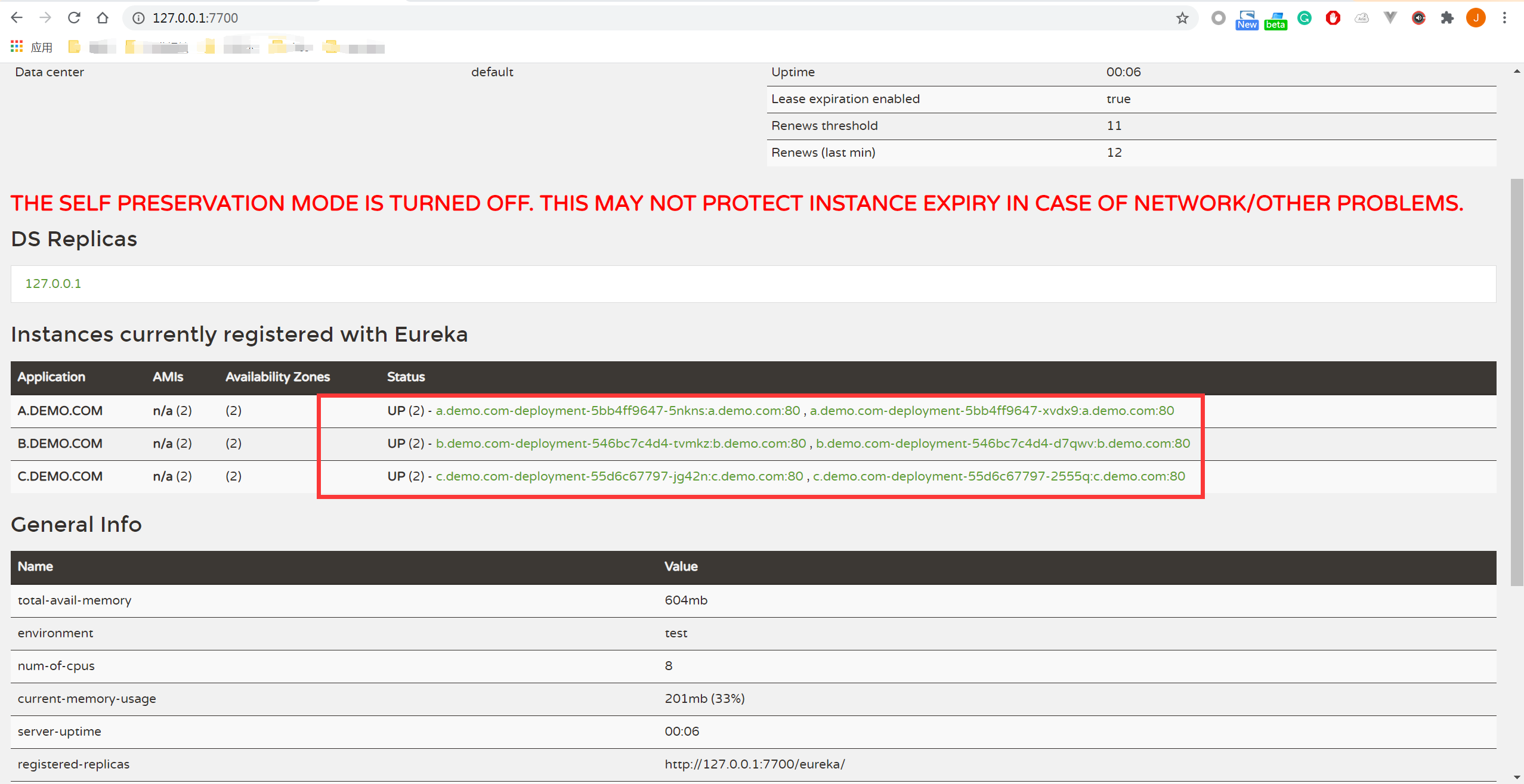
首先我们可以打开dashboard 从中查到eureka.服务器的具体ip, 然后访问eurka 服务。
查看注册中心
在页面中你可以发现,在Kubernetes集群里,我们启动了3个eureka服务,它们相互注册,组成了一个高可用集群。
其次,我们在Grafana 中导入 jvm 的监控项目
这样Grafana可以帮助我们把 各个Java服务的具体状态做一个收集,完成我们需要的监控。
前端验证
此时 我们打开 http://www.demo.com 的网页。
我们可以点击页面上的 get 请求按键,模拟发出请求,随后我们就会发现页面里显示出的信息在不断变化。
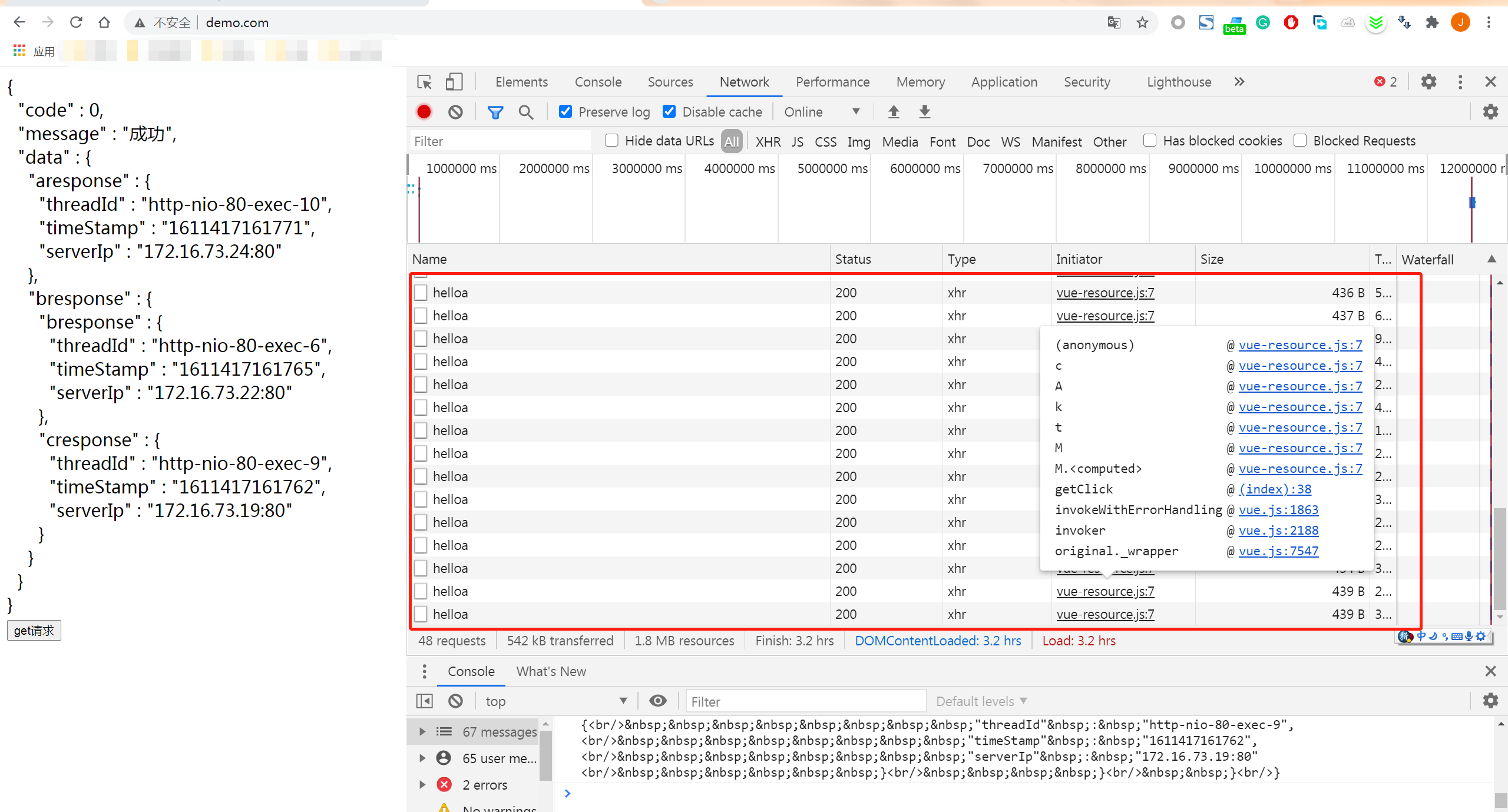
在页面显示的内容里,我们可以清楚地发现,我们的消息在不同实例里处理,如果有一个实例出现了故障是不会影响我们现在的业务的。
好了开始验证整个系统。
模拟验证
使用一个简单的脚本 模拟每3秒从前端访问一次后端。
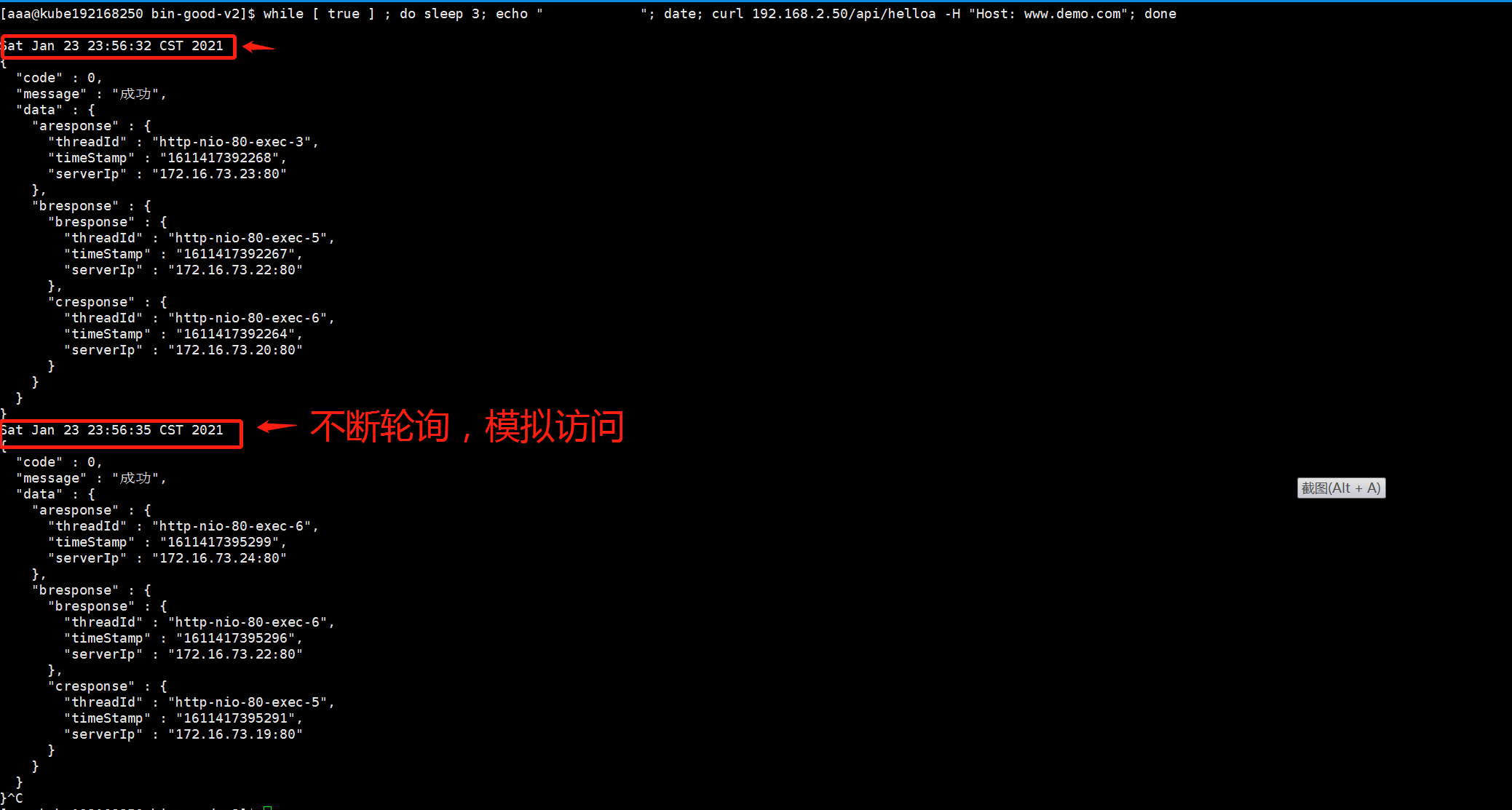
调用关系验证
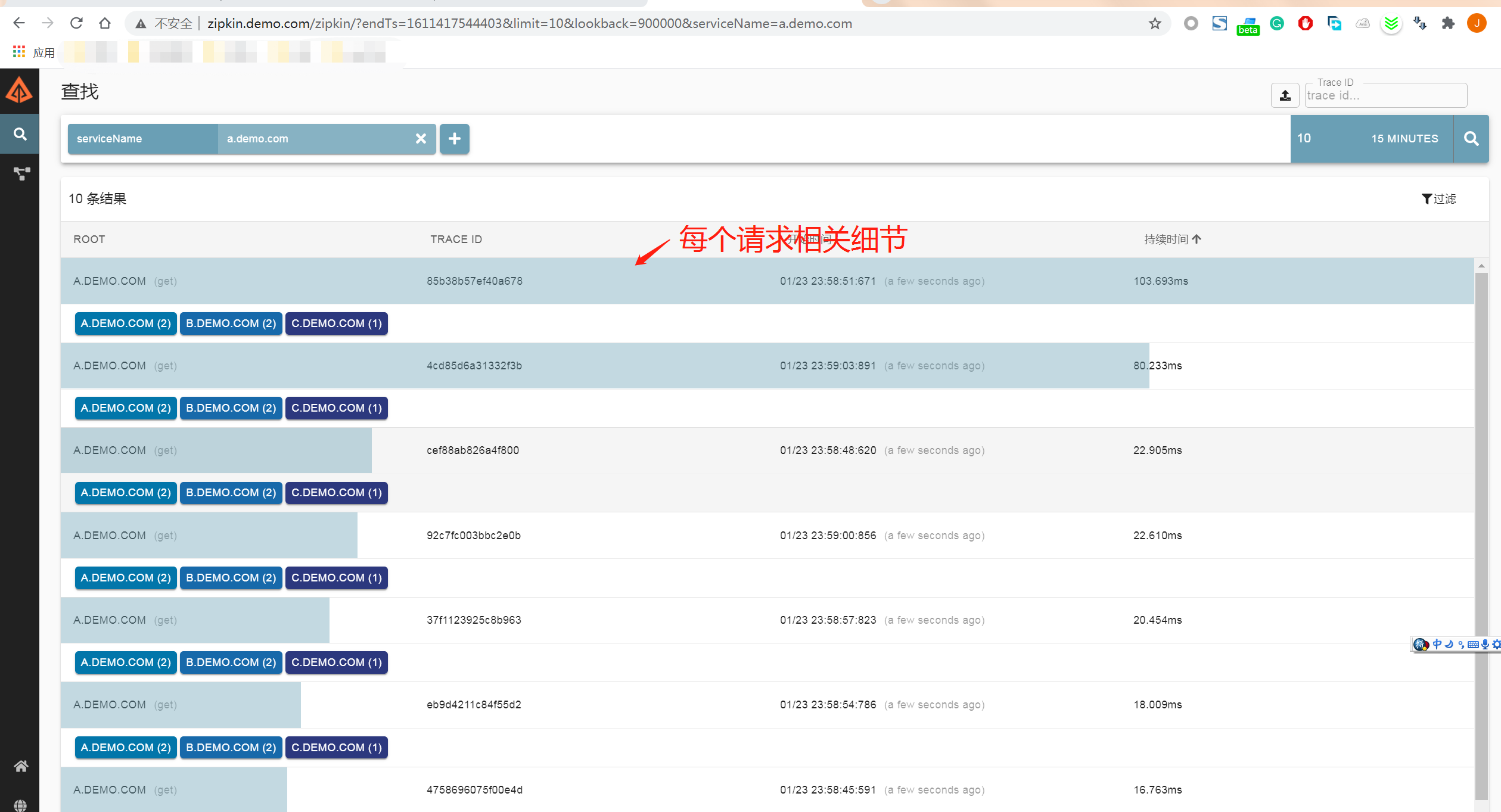
首先打开zipkin zipkin.demo.com
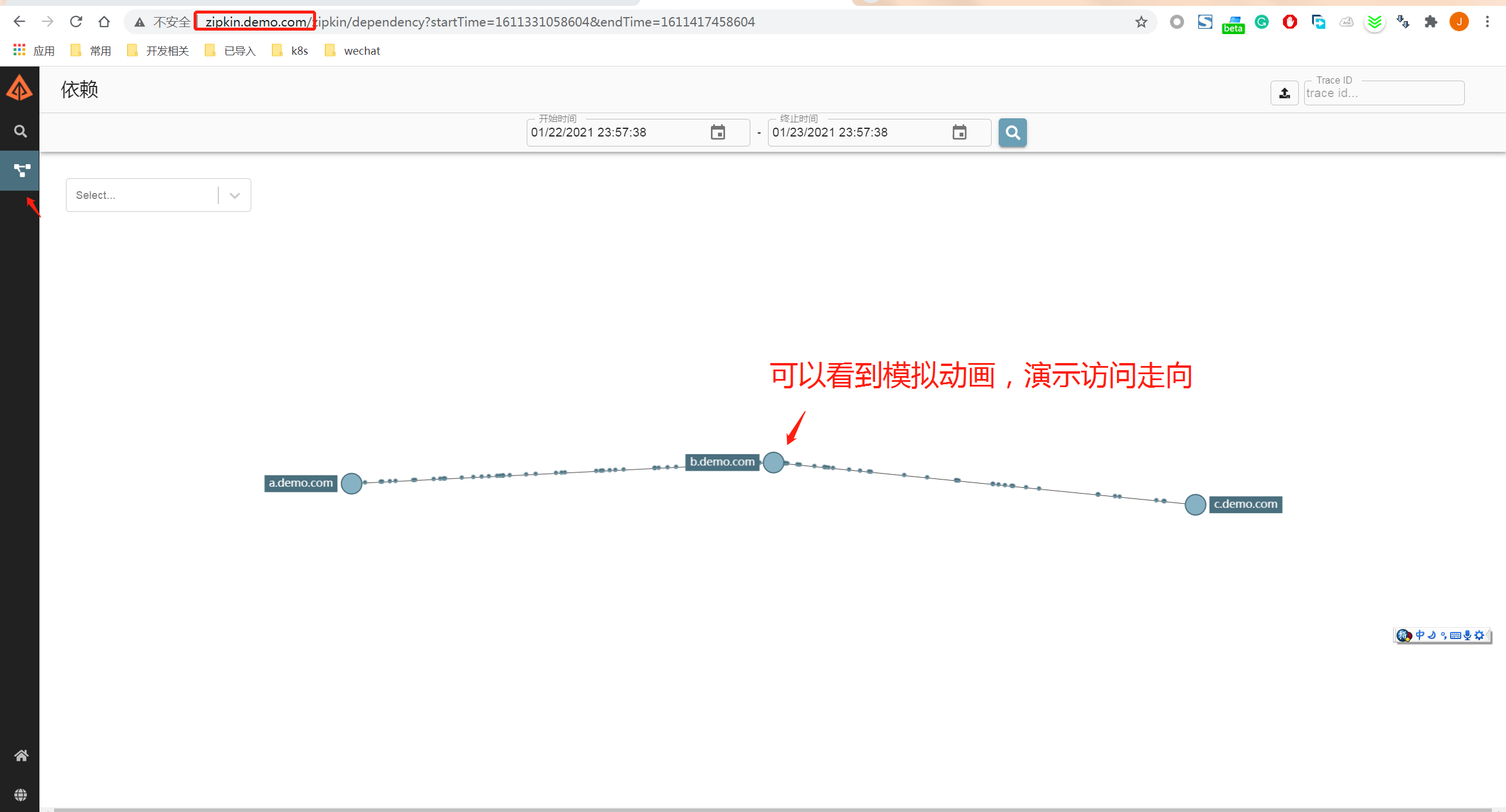
点击具体的请求,可以查看到每次请求在内部的细节。
限流 熔断验证
其次 打开 sentinel 站点,这个站点可以监控,也可以对微服务进行限流,限速,熔断等操作。(密码口令都是 sentinel)

进入控制台后,我们可以发现所有的服务已经自动被发现,并存在于左边的菜单。

分别点开 a b c 3个服务,可以看到规律的周期访问,和我们的脚本的测试速度是一致的。
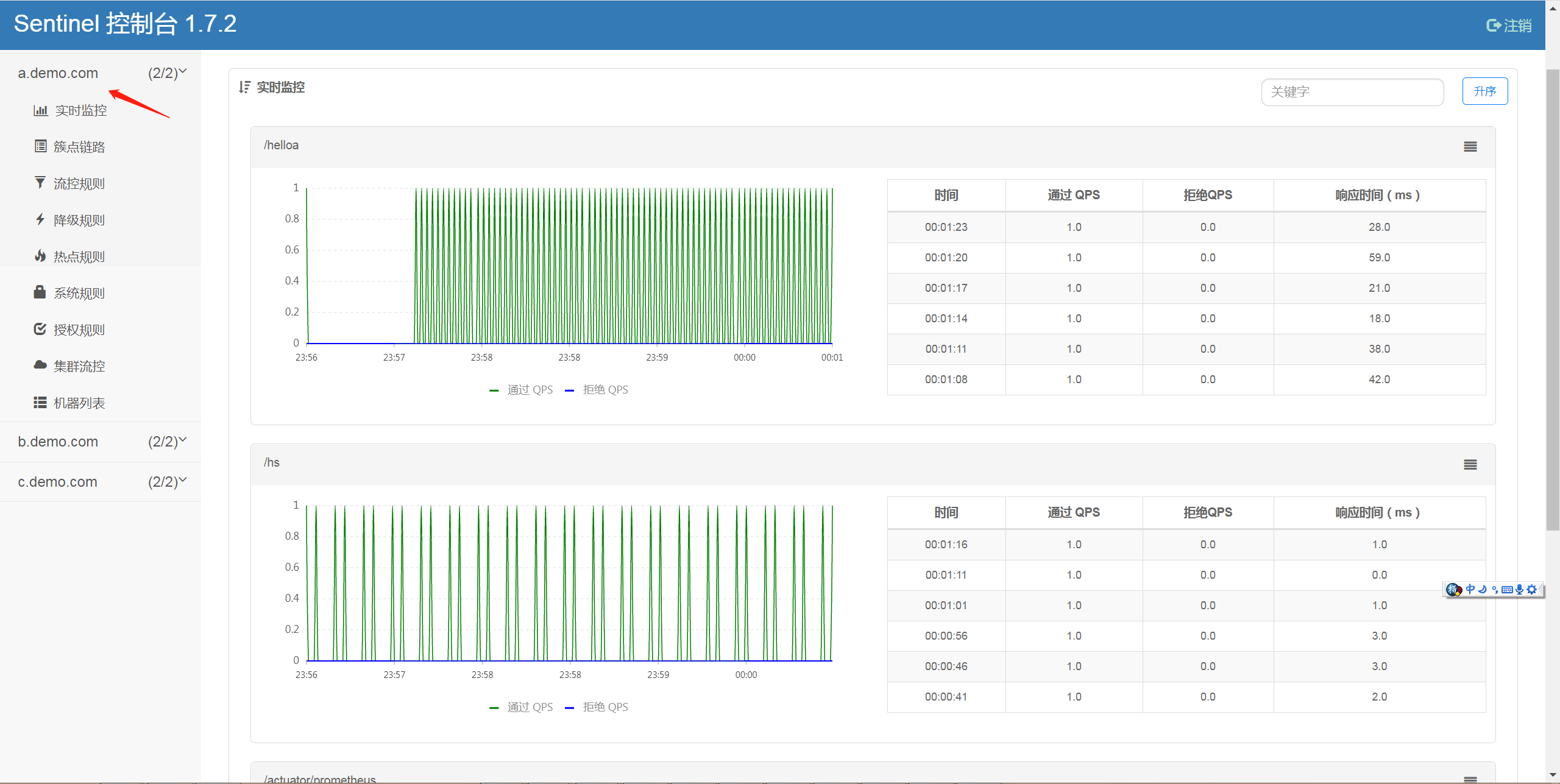
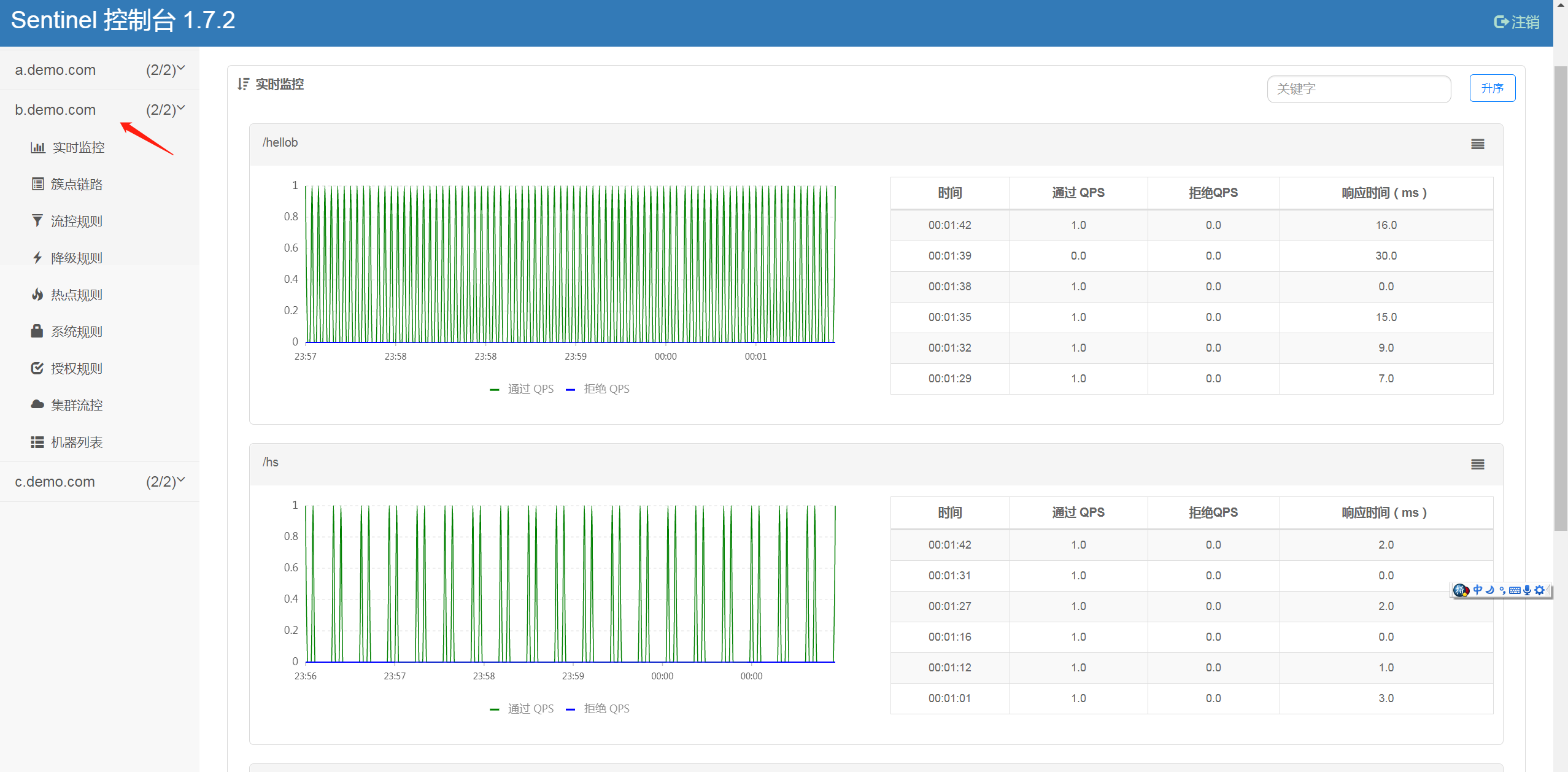
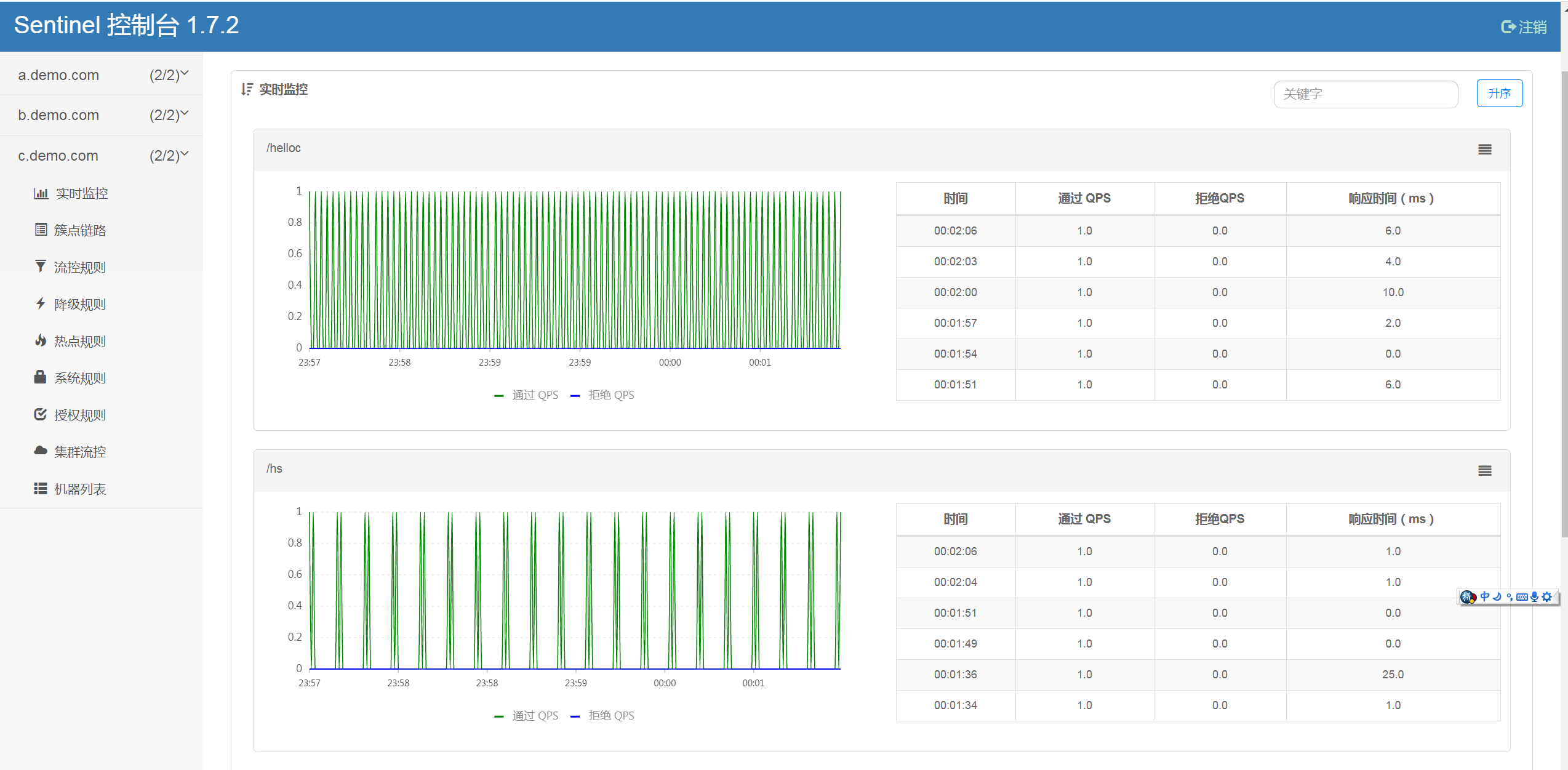
Sentinel 里面内含强大的监控,流控 降级等功能,具体的使用,可以慢慢学习,相信你一定会受益良多。
应用状态验证
打开Grafana的监控页,你可以查看所有应用的状态,包括heap 大小,启动时间,错误数目 等等。
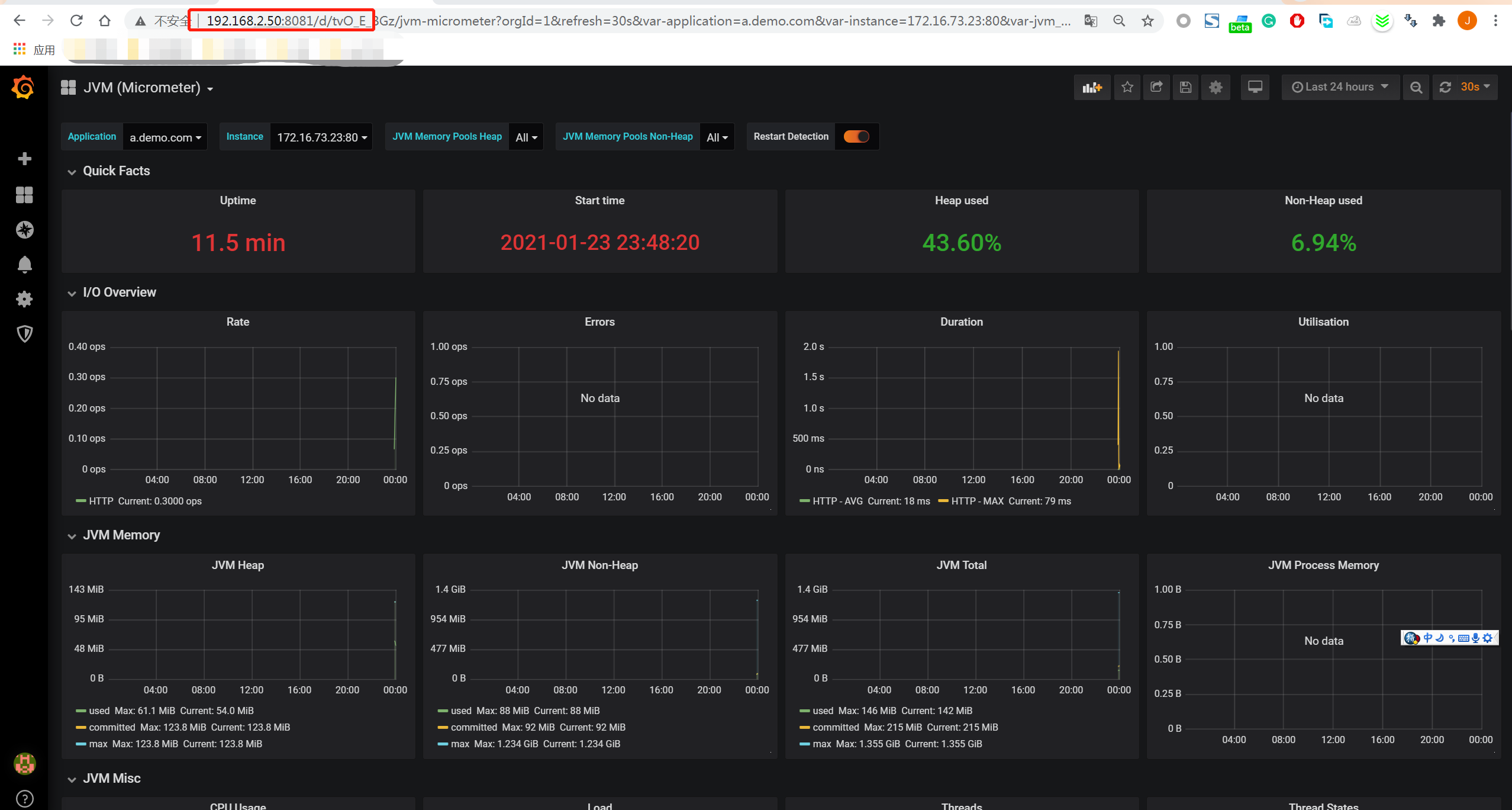
通过这张图你可以了解每个应用本身的状态,使用了多少内存,响应的代码是多少,jvm 使用情况。相信此时 你已经对各个组件的情况,监控都有了一个全面了解。一个基于Kubernetes的微服务架构已经开始工作了。
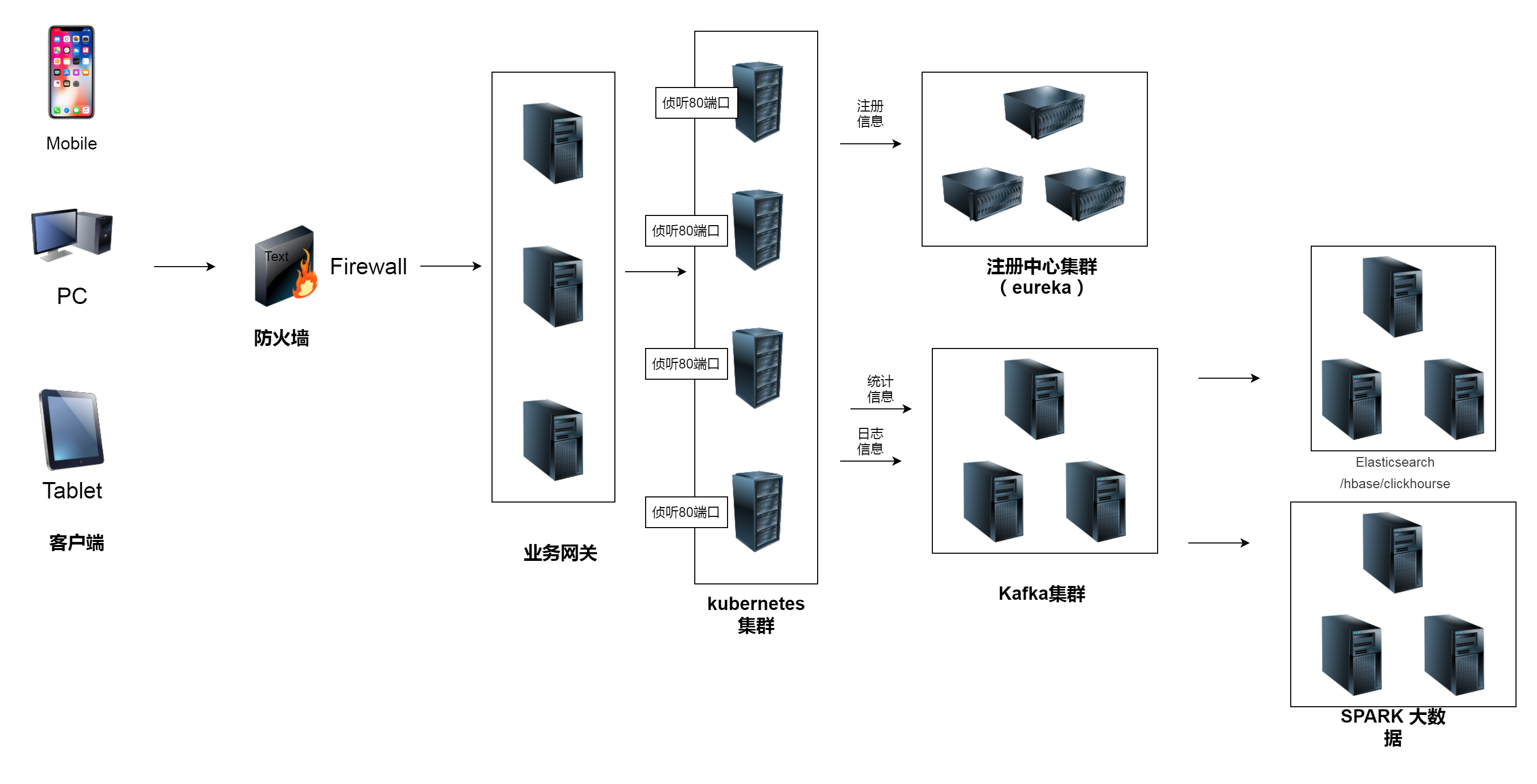
最后送一张常用的系统架构图,希望大家能通过本文对高可用微服务如何架设Kubernetes上有一个基本的了解,将本文讨论的东西用于实践。谢谢!