wren
 wren copied to clipboard
wren copied to clipboard
Do not lookup for allocator/finalizer every time we allocate/deallocate a foreign class
Lookup is expensive: it implies hash table lookup. Although an optimizing compiler can fold the hash of "<allocate>" and "<finalize>" (and thus avoid recomputing it every time), the process is still more expensive than we want, especially since that every foreign class allocation (not just declaration) does that, and also GC for every foreign class, which may delay GC that in turn blocks code from executing, which can, for example, trigger a FPS dropping in a game.
The way we avoid it is by adding the "<allocate>" and "<finalize>" strings to the symbols table, before anything else. This way, due to the nature of the symbol table that increments each symbol by one, we can know what are the values of those symbols; and thus, when we need to access them, we just address at the known symbol.
This has the disadvantage of adding two entries to the methods table of each class, but considering that:
- We already have pretty high number of wasted entries, with direct proportion to the number of classes and methods (the more methods you have the more wasted entries you have per class, the more classes you have the more wasted entries you have in total).
- Each entry is just the size of two pointers (16 bytes on 64-bit systems, 8 bytes on 32 bit systems) include padding, and
- The speed we gain from that (again, for every allocation/deallocation of a foreign class),
I think this is a worthwhile trade-off.
I would promote the ASSERT when registering the well-known values to a stronger error in case we run out of memory or what ever when not in debug mode. Since these registration should be done once at creation of the VM, it should have 0 impact if we are slower and safer. Did you consider putting symbols in a table ? It would automate things a little bit more (a little bit overkill for 2 symbols, but can be abused, to ensure the layout of the method indexes to help with caching most used symbols at the begin of the table).
I would promote the ASSERT when registering the well-known values to a stronger error in case we run out of memory or what ever when not in debug mode. Since these registration should be done once at creation of the VM, it should have 0 impact if we are slower and safer.
I considered that, but decided that I'll follow the line of the rest of the code, where we ignore out of memory run. I don't see reasons to embed assertions. The reason for ASSERT() is not to protect from something unknown, but from future possible change that will either register another symbols before or change how symbols are generated.
Did you consider putting symbols in a table ? It would automate things a little bit more (a little bit overkill for 2 symbols, but can be abused, to ensure the layout of the method indexes to help with caching most used symbols at the begin of the table).
I don't understand, which table are you talking about? By the way, I have more predefined symbols for another features (esp. reverse operators).
Something like:
static void ensureSpecialSymbols(WrenVM* vm) {
static const char *symbols [] = {
"<allocate>",
"<finalize>",
}
for (size_t i = 0; i < sizeof(symbols); ++i) {
const char *symbol = symbols[i];
int symbol = wrenSymbolTableEnsure(vm, &vm->methodNames, symbol, strlen(symbol));
ASSERT(symbol == i, "Definition of predefined symbols went wrong.");
}
}
For 2 items, I agree, but that list can be extended for easily guaranteed more entries positions. Anyway it is a minor issue.
No difference was observed.
Edit: The impact on performance should be very small, because this is just some more CPU cycles every foreign class construction.
I did a little bit of measuring and compared creation of a foreign, a class, and a list for interest sake. The right hand side is with this patch applied, left is before. Still a synthetic benchmark, but interesting still, e.g seems to typically scale linearly across the extra 0.
misleading results, see the comment below.
var sum_f = 0
var sum_v = 0
var sum_l = 0
var runs = 1000
for(r in 0 ... runs) {
var count = 10
var start = IO.timestamp()
for(i in 0 ... count) {
var f = F.new()
}
sum_f = sum_f + IO.timestamp()-start
start = IO.timestamp()
for(i in 0 ... count) {
var v = V.new()
}
sum_v = sum_v + IO.timestamp()-start
start = IO.timestamp()
for(i in 0 ... count) {
var l = [0,0,0,0]
}
sum_l = sum_l + IO.timestamp()-start
}
System.print("foreign average %(1000 * (sum_f/runs))ms")
System.print("class average %(1000 * (sum_v/runs))ms")
System.print("list average %(1000 * (sum_l/runs))ms")
The changes in list creation are negligible.
The changes in foreign instantiation are quite impressive, and understandable.
The interesting part is the changes in normal class instantiation: it does seem to be quite big difference, not something I can describe by benchmark environment, but I don't understand their source. I'll take another look.
BTW, why is the extension .lua?
I'm doing another run as well, as always there will be a lot of variation between runs, but it's fairly consistent in terms of outcomes. lua extension highlights numbers, no other reason.
I think it's possible I ran the before with different number of iterations, so the averages aren't matching. hence redoing it.
~~I can optimize this a little bit more by starting the search for a method from index 2, skipping the initializer and finalizer we never lookup.~~
Edit: My bad, this will only affect compilation times and not worth it.
note that the expectation is that list and class shouldn't change much (minor variations expected). The previous stats are the wrong comparisons. here's the correct one:
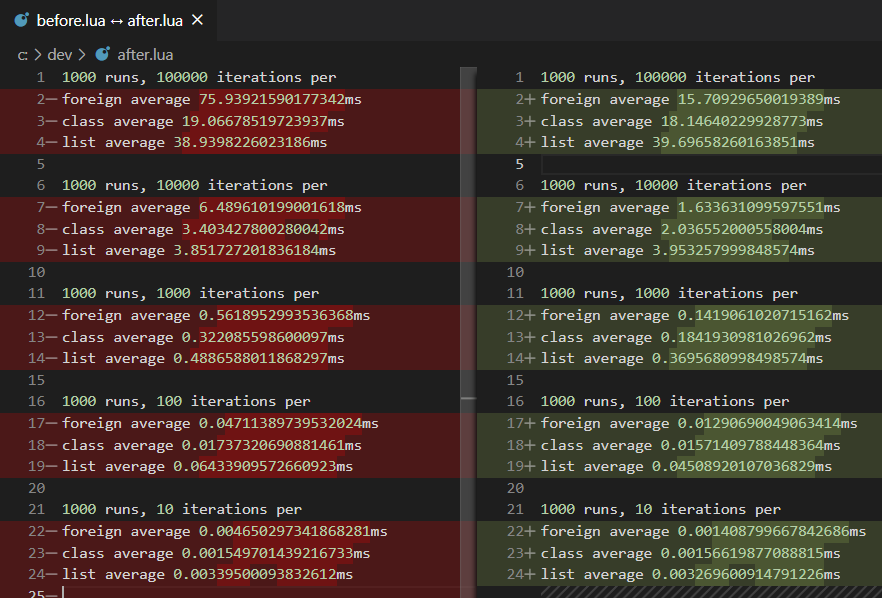
I applied this commit to my current project (which has LOTS of foreign allocator/finalizer hits), and it sped up gc runs from 12ms to under 1ms. Pure gold for my use case. Thank you Chayim!