req
 req copied to clipboard
req copied to clipboard
Response streaming
Hi @wojtekmach,
Is streaming support something you'd consider as part of the API for Req? e.g. something like this:
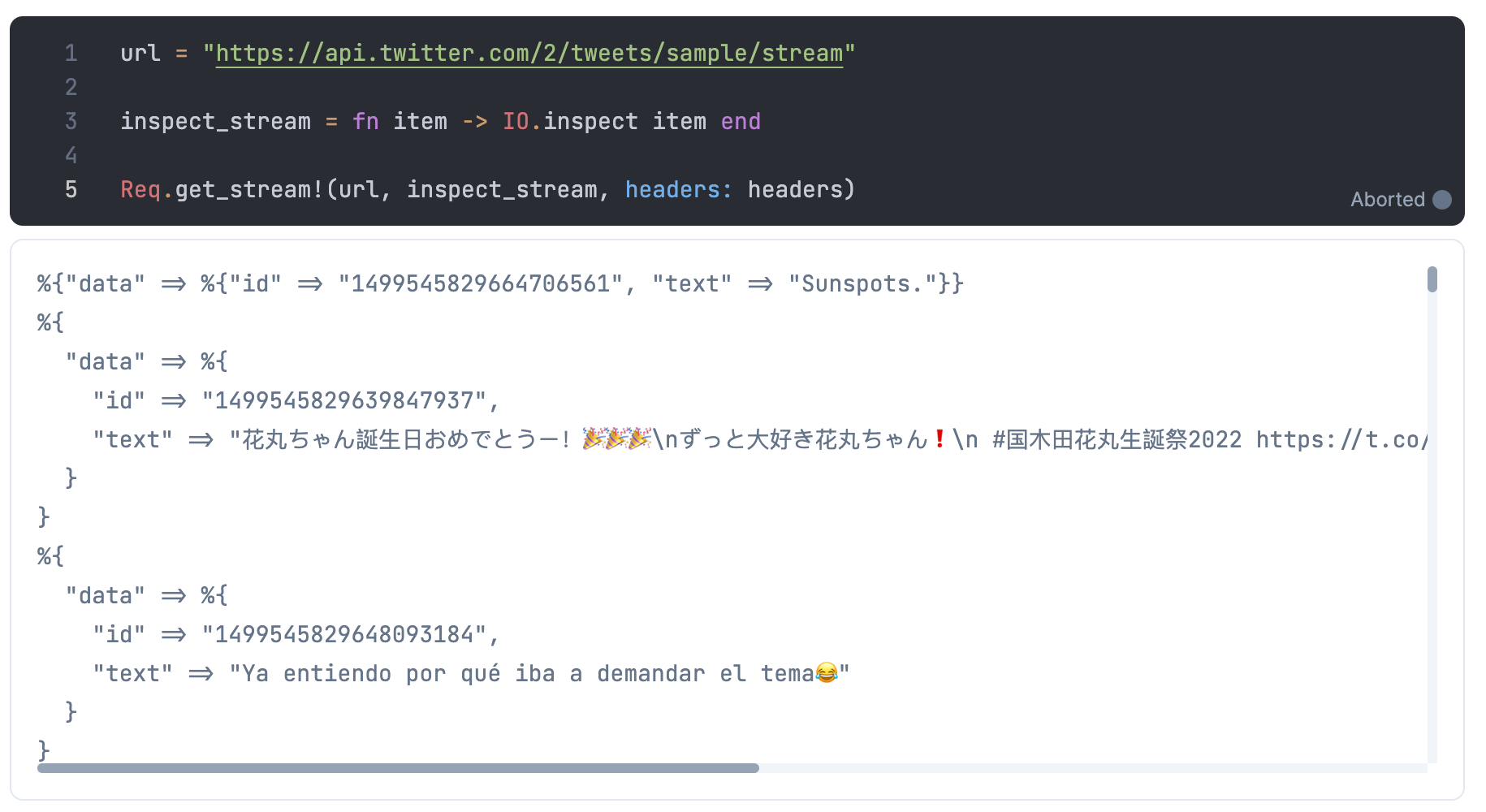
url = "https://api.twitter.com/2/tweets/sample/stream"
inspect_stream = fn item -> IO.inspect item end
Req.get_stream!(url, inspect_stream, headers: headers)
I noticed you had an empty issue here but wasn't sure it was the same thing.
Yes, both request and response streaming is something I'm definitely interested in. I'm not sure about the user-facing API though. What you have is an interesting idea how this could be done. But then the other big problem is how to actually implement it. :) Could all response steps receive a chunk or the step need to somehow opt-in to supporting streaming? Do we have separate streaming steps? Stuff like that.
As a client, I would expect to receive an elixir %Stream{} from a get_stream! call.
That would allow us to pipe to Stream functions to manipulate the stream.
Here is something I worked on a long time ago as a proof of concept.
Yeah, I think that'd be the ideal API. Unfortunately I don't think it's currently possible to achieve with Finch.stream.
As a client, I would expect to receive an elixir
%Stream{}from aget_stream!call. That would allow us to pipe toStreamfunctions to manipulate the stream. Here is something I worked on a long time ago as a proof of concept.
I think this would be ideal too!
I went the lazy approach in my PoC by passing a function to consume the streamed response (I guess mimicking stream(req, name, acc, fun, opts \\ []) from the underpinning library / Finch) as I had initially thought it wouldn't be possible to return the stream, but like your PoC @alexandremcosta!
More to ponder 🤔
Yeah, I think that'd be the ideal API. Unfortunately I don't think it's currently possible to achieve with Finch.stream.
as I had initially thought it wouldn't be possible to return the stream, but like your PoC @alexandremcosta!
This is possible. The snippet outlines the idea: another process calls Finch.stream and sends each chunk back.
defmodule FinchStream do
def request(req, name, opts \\ []) do
Stream.resource(
fn -> start_fun(req, name, opts) end,
&next_fun/1,
&after_fun/1
)
end
defp start_fun(req, name, opts) do
me = self()
ref = make_ref()
task =
Task.async(fn ->
fun = fn chunk, _acc -> send(me, {:chunk, chunk, ref}) end
Finch.stream(req, name, nil, fun, opts)
send(me, {:done, ref})
end)
{ref, task}
end
defp next_fun({ref, task}) do
receive do
{:chunk, chunk, ^ref} -> {[chunk], {ref, task}}
{:done, ^ref} -> {:halt, {ref, task}}
end
end
defp after_fun({_ref, task}) do
Task.shutdown(task)
end
end
Finch.start_link(name: MyFinch)
Finch.build(:get, "https://hex.pm")
|> FinchStream.request(MyFinch)
|> Stream.drop_while(fn {type, _data} -> type != :data end)
|> Stream.each(fn {:data, data} -> IO.inspect(data, label: "\nChunk:\n") end)
|> Stream.run()
If the caller doesn't process the whole stream, for example calls Stream.take_while/2, this code will leave messages on the caller mailbox.
To prevent this problem, after_fun should manually shutdown the task (and maybe flush known messages?)
edit: updated the code above...
The problem with this is that data is copied between processes, which is inefficient. If we had a way to not copy, that would be more performant.
Yes, exactly. Forgetting about Finch for a second, I believe we could have a stream of chunks where each chunk was generated by calling Mint.HTTP.recv. If that's viable, either Finch would have an option to return such Stream or it would expose to us a way to build it ourselves, expose the underlying Mint.Conn. cc @sneako
I was wondering if Req supported streaming, and here comes this discussion :smile: thanks!
To prevent this problem, after_fun should manually shutdown the task (and maybe flush known messages?)
This is one part I'm concerned about indeed. It shows up (although with HTTPoison) in this article by @alvises (code at https://github.com/poeticoding/httpstream_articles) which features :hackney.stop_async(resp.id).
As a user (of Req or other clients) I would be concerned about leaks when using streaming.
Really curious to see where this will go ultimately.
Maybe this will be helpful, I have a piece of code I use to stream large CSV files (gigabytes) from external HTTP endpoint, this is the client I wrote that wraps Finch. There is some cleanup needed and it is operating on lines of data, as it deals with CSV files, so this is pretty specific to my use case, but it allows you to stream_url/1 that produces Elixir Stream that can be consumed just like a stream from a file.
The other thing it does is allowing to peek at the first line, that's probably not helpful in this context but was for me. Can be cleaned up.
This could serve either as an inspiration if this is the right approach to the problem, for someone to port it here, or I could even work on this some time over next couple weeks if you like the solution.
Gist: https://gist.github.com/hubertlepicki/7be1d5c1f396c7508b153a4a39a542ef
In particular, creating Stream: https://gist.github.com/hubertlepicki/7be1d5c1f396c7508b153a4a39a542ef#file-http_streamer-ex-L19
To add more "prior art" to the discussion, I've also implemented a wrapper on top of Finch to stream response, but in this case without Stream.resource, that we are using to compute checksums of remote HTTP resources:
- https://github.com/etalab/transport-site/blob/master/apps/shared/lib/http_stream_v2.ex
- https://github.com/etalab/transport-site/blob/master/apps/shared/test/http_stream_v2_test.exs
Thanks @hubertlepicki. I believe something somewhat similar was mentioned earlier and the concern is extra messaging will make it not as efficient as possible.
Maybe we simply cannot generate such stream in an efficient way and what we're left with is callback-based API. Though req maybe can add some niceties, at the very least consume the status and the headers and wrap them in a response struct:
fun = fn data, response ->
IO.inspect data
response
end
response = Req.get!(url: "https://httpbin.org/stream/10", stream: fun)
response.body #=> "" (because we're not accumulating it in fun)
another reason to have a response struct with status and headers is that is enough for some steps like follow_redirects and retry and I'd really like to be able to somehow still use them. Obviously it won't work on steps that operate on the response body like decompress_body and decode_body and I'm honestly not sure what to do about them. Perhaps a response step can also receive and return:
fn request, {chunk, response} ->
{request, {chunk, response}}
end
but now every response step needs to handle this which I'm not sure about.
@wojtekmach what sort of inefficiency you have in mind ref. this solution? There's some overhead for message passing but that's not the bottleneck either for me or probably even for cases like writing the file in chunks to disk... I mean, the problem streaming solves is different than lack of performance - I can't load the whole file to memory, not even for a moment, because the files are larger than the memory I have allocated for the whole VM xD. This has to be reasonably performant IMHO.
But anyway, a solution that does it either quicker or with less overhead than two processes would be nice - and maybe there is a way but that is above my paygrade.
My concern is data copying on message passing. Maybe it is not a big deal and if someone needs absolutely best performance they would drop down to Finch or Mint anyway.
This is a good point. I'm again slightly out of my depths, but I assumed the binaries are not copied between processes, but a reference is passed, so as long as we're sending an actual binary (and not struct) from one process to another, and the binary is larger than 64 bytes, we're not actually duplicating the binary, as it sits on a dedicated binary heap. We probably don't want to concatenate the binaries for no reason, or wrap them in structs etc.
I wonder if someone smarter than me in terms of knowing ins and outs of BEAM could confirm - anyone you know of we can ask?
https://stackoverflow.com/questions/47595304/big-binary-data-share-between-processes
https://github.com/erlang/otp/blob/master/erts/emulator/internal_doc/GarbageCollection.md#binary-heap
Here's another idea, instead of returning a stream as response body and possibly having a contract for chunk-aware response steps, let's do something simpler.
We add a stream: fn chunk, {request, response} option and we use it in the Finch step for :data chunks. This means in the Finch step we'd process the entire stream and have a Req.Response and we'd run it through response steps. This means we couldn't abstract, say, streaming CSV decoding in a decode_body/1 step and we'd have to do it ourselves in the given :stream function, but that's ok.
(EDIT: previously I thought about the following but I think above is even simpler and possibly more reliable)
~We consume the :status and the :headers chunks and build a response with these and body set to "" and run the response steps. This way we'd still have things like follow redirects, retries, etc. Once we get :data chunks we run them against the given stream function.~
Here's an example:
Mix.install([
{:req, github: "wojtekmach/req", branch: "wm-stream"}
])
fun = fn chunk, acc ->
IO.inspect(Jason.decode!(chunk)["id"], label: :chunk)
acc
end
Req.get!("https://httpbin.org/redirect-to?url=/stream/3", stream: fun).body
#=> ""
# Outputs:
# 12:06:24.459 [debug] follow_redirects: redirecting to /stream/3
# chunk: 0
# chunk: 1
# chunk: 2
Here is another similar example where we append chunks to the response body: https://github.com/wojtekmach/req/compare/main..wm-stream#diff-dc476e4c9226d38862002c18df4835a1d51d98448df84548cd4e144fae0ec2e9
Thoughts?
It's possible to turn the response into a Enumerable usable with Stream with that option, right?
I think that would be possible outside of Req using process messaging described in comments above.
the binary is larger than 64 bytes, we're not actually duplicating the binary, as it sits on a dedicated binary heap
Erlang guide about this. Also, nice answer by Robert Virding on elixir forum.
@wojtekmach I like the simplicity, but it doesn't add much to what Finch already does. If the caller needs the full body, why he is streaming? He can just call Req.get/1.
The good side of having a Stream is you can pipe it to other modules, and decouple the logic to receive the stream from the module that forwards the stream to somewhere else. For example, to manipulate with Stream functions from other libs like CSV, or ExAws.
If the caller needs the full body, why he is streaming? He can just call Req.get/1.
Not sure I understand your point. Can you elaborate? Did you mean that what i said about using the stream function to append chunks to response body is a bad example? If so, agreed! I just wanted to highlight the approach offers some, even if limited, way of keeping track of data.
I think I am going to go with the approach outlined above. I’d love to see a Req plugin that keeps response body a stream, see how the implementation ends up looking. I think the plug-in would need to replace most response steps with stream aware variants.
I think that would be possible outside of Req using process messaging described in comments above.
OK, well first of all any kind of streaming is better than nothing 🙂 For my use cases, I would prefer being able to do something like this:
Req.stream!("https://httpbin.org/redirect-to?url=/stream/3", type: get)
|> parse_json_object()
|> store_json_object_in_db()
which is simpler than having a different process, and it's possible to turn this approach into the separate-process approach, but the other way around is difficult. Spear has this and is also based on Mint: https://github.com/NFIBrokerage/spear/#usage. Afaik it doesn't have an additional process to accomplish this. But I'm not sure if Finch can do it as well.
Hi all! I wanted to bump this conversation now that there's a plugin mechanism for issuing requests with Finch.stream/5.
I wanted to make sure I'm on the same page as everyone who has contributed to the discussion so far:
- Using the new
:finch_requestoption, it's possible for a plugin to expose the response body as a stream. This requires process messaging however, which isn't optimal. - Exposing the body as a stream without process messaging would require some additional API in Finch that allows us to "manually receive". FWIW, @sneako has indicated that he's open to proposals.
- There's an open question of how/whether to apply response steps to streaming responses. One option that @wojtekmach mentioned is that the streaming plugin could/should just reimplement certain steps. There are also other steps that only really make sense in a streaming context, like parsing server-sent events.
Curious to hear if anyone's thoughts on this have crystalized in the last months!
Hey all, Finch is getting another way of response streaming that Req can use!
See https://github.com/sneako/finch/pull/228 for more information. Let's continue Req aspects of that discussion here:
That said… I think there’s a way for Req to take this into consideration to allow processing in response steps. (Not doing so would be, imo, a big missed opportunity for Req!)
At the moment we have these built-in response steps: decode_body, decompress_body, follow_redirects, handle_http_errors, output, and retry.
For follow_redirects, handle_http_errors and retry all we need is the :status bit.
Automatically streaming to output file, via output step, sounds very appealing.
Now, there's decompress_body and decode_body. We can implement decompress_body using :zlib.deflateInit + :zlib.deflateEnd, that is we transform the stream to emit decompressed chunks. But then with decode_body, say we decode JSON or CSV. We are not guaranteed the chunk we got is valid. FWIW, NimbleCSV has parse_stream (and even a to_line_stream). For JSON, I suppose people would consume ndjson etc actually but not sure how well specified that is, in the sense whether servers actually set proper content-type, etc. (And then we'd have to implement the to_line_stream equivalent which I'm not particularly looking forward to. 😅 )
Is decode_body something Req should handle out of the box or best left to the user? I think the latter.
In other words, perhaps Req just consumes initial bits, :status and :headers, and builds a response out of that which allows us to handle redirects and retries. But leaves everything else for the user. In other words:
Enum.each(Req.get!(url, stream: true).body, fn
{:data, data} ->
IO.inspect(data)
{:headers, headers} ->
IO.inspect(headers)
end)
WDYT?
I've only done about 20 minutes of research, but it looks to me like trailing headers are pretty uncommon. Spitballing a bit here:
# With stream: true, assume no trailing headers. If they're encountered
# at the end of the request, log a warning. I think this is the behavior
# that most people will expect and prob works for 99% of use cases.
Enum.each(Req.get!(url, stream: true).body, fn data ->
IO.inspect(data)
end)
# With stream: :raw, contains both :data and :trailing_headers.
# IMO it's worth disambiguating since all :headers at the start of
# the response will be consumed by Req in the Response struct.
Enum.each(Req.get!(url, stream: :raw).body, fn
{:data, data} ->
IO.inspect(data)
{:trailing_headers, headers} ->
IO.inspect(headers)
end)
# Alternative to stream: :raw is to use the existing :raw option
Enum.each(Req.get!(url, stream: true, raw: true).body, fn
{:data, data} ->
IO.inspect(data)
{:trailing_headers, headers} ->
IO.inspect(headers)
end)
# If you're consuming well-formatted ndjson, you can easily do this:
Req.get!(url, stream: true).body
|> Stream.map(&Jason.decode/1)
|> Enum.each(&IO.inspect/1)
In the future, after some stream-handling patterns arise, Req could potentially introduce a :decode_stream step and option that defaults to false, but that, when true, can automatically decode various formats based on headers.
# If you're consuming well-formatted ndjson, you can easily do this: Req.get!(url, stream: true).body |> Stream.map(&Jason.decode/1) |> Enum.each(&IO.inspect/1)
right, I think this is the code people expect to be able to write.
I think the :stream and :raw combination is interesting but if we don't do anything in decompress_body and decode_body we might as well say that setting :stream implies setting raw: true and I think that'd be pretty reasonable. I need to read up on them more but yeah if trailing headers are very uncommon, maybe we add a trailing_headers: :log (default) | :ignore | fun(header, value).
I think the :stream and :raw combination is interesting but if we don't do anything in decompress_body and decode_body we might as well say that setting :stream implies setting raw: true and I think that'd be pretty reasonable.
Would setting raw: false do anything in this hypothetical?
It would certainly be nice to have automatic decompression. If the Transfer-Encoding is chunked, I think there are some well-defined rules for how encoding should work per-chunk, which should be per-:data message.
raw: false would let these response steps work on the response body and these steps would either a) crash, b) as a convention leave it unchanged (which is a decent option imho) or c) work on the stream. Which is probably doable for decompress_body but I don't think it is for decode_body in all cases. For example:
$ curl -i https://httpbin.org/stream/2
HTTP/2 200
date: Mon, 05 Jun 2023 14:21:14 GMT
content-type: application/json
server: gunicorn/19.9.0
access-control-allow-origin: *
access-control-allow-credentials: true
{"url": "https://httpbin.org/stream/2", "args": {}, "headers": {"Host": "httpbin.org", "X-Amzn-Trace-Id": "Root=1-647def51-73f7fb5973e9c9d8795f696d", "User-Agent": "curl/7.88.1", "Accept": "*/*"}, "origin": "89.73.45.237", "id": 0}
{"url": "https://httpbin.org/stream/2", "args": {}, "headers": {"Host": "httpbin.org", "X-Amzn-Trace-Id": "Root=1-647def51-73f7fb5973e9c9d8795f696d", "User-Agent": "curl/7.88.1", "Accept": "*/*"}, "origin": "89.73.45.237", "id": 1
the server says it is application/json but it is not valid JSON. I'd rather not deal with this. That is, go with the snippet you proposed, people decode JSON chunks themselves.
c) work on the stream. Which is probably doable for decompress_body but I don't think it is for decode_body in all cases.
Definitely agreed on this point.
I'd suggest that initial streaming support should include some handling for trailing headers and some handling for decompression, and leave the rest up to plugins/custom steps.