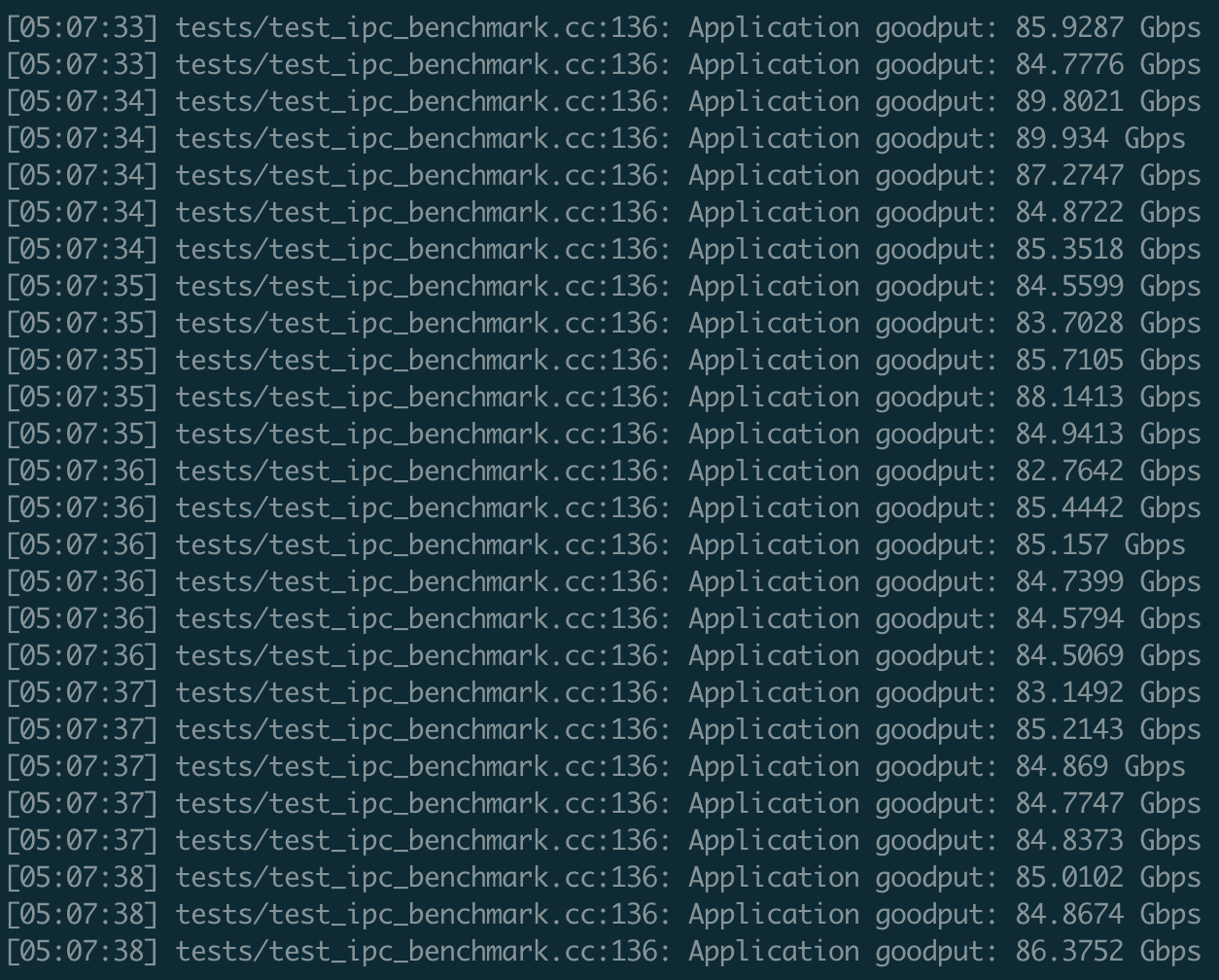
The performance of many execute times are different
Phenomenon
Thanks for your excellent works! Recently I ran example pytorch/benchmark_byteps.py with RDMA distributed traning based on https://github.com/bytedance/byteps/blob/master/docs/step-by-step-tutorial.md and found a strange phenomenon, which is the speed perfomance with many re-execute training shell are different in the same envrionment. For example, I run the local mode of 2worker+2server (two machine, each one have a worker and a server):
the result of first time:
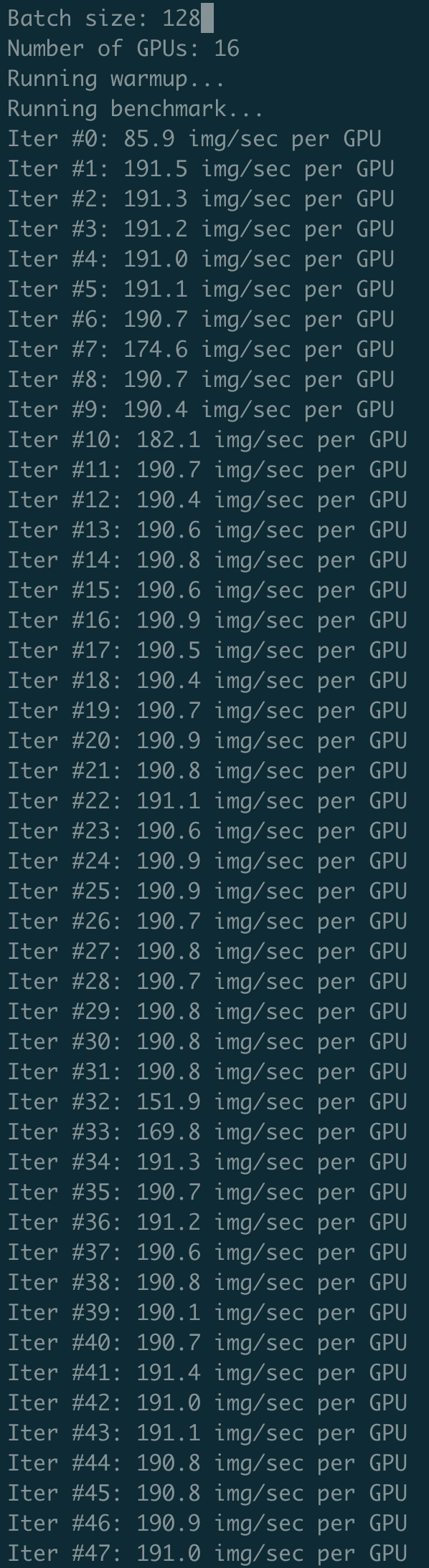
Then using ctrl+c to stop running, killing all python3 process by command ps -ef|grep python3|grep -v grep|awk '{print$2}'|xargs kill -9 and then re-executing the same training bash, the performance are different:
the result of second time:
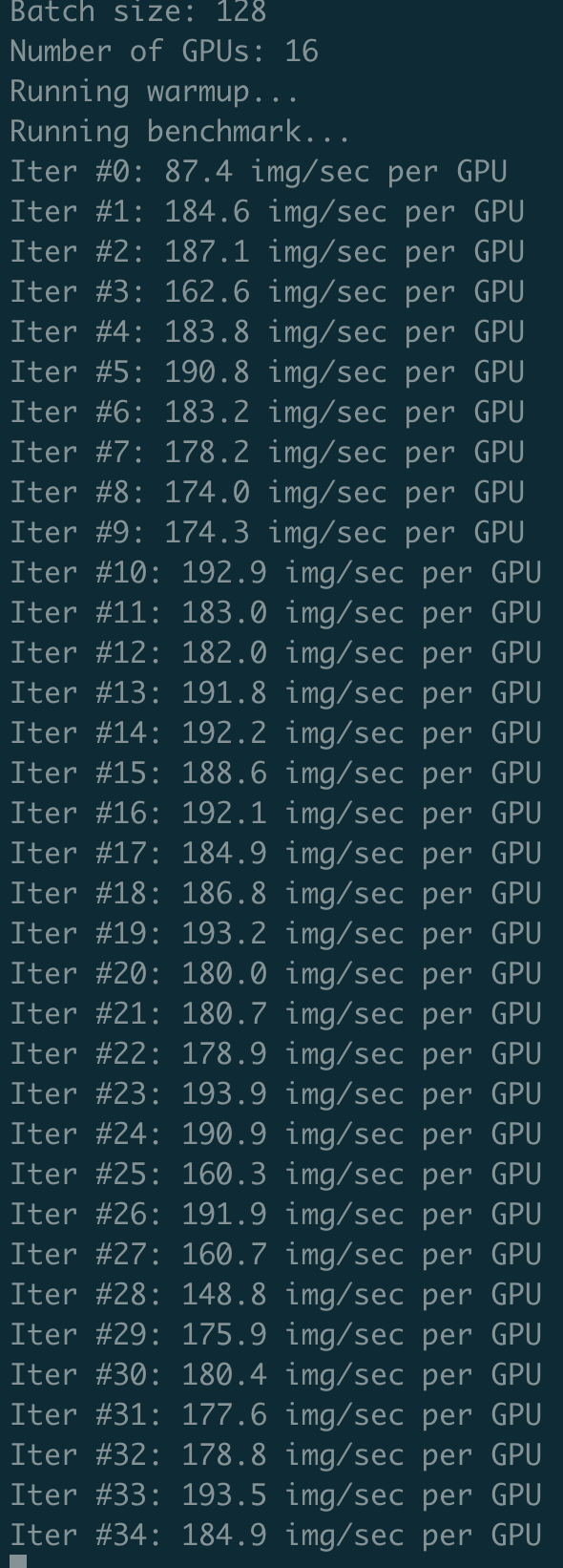
Again, using ctrl+c to stop running, killing all python3 process by command ps -ef|grep python3|grep -v grep|awk '{print$2}'|xargs kill -9 and then re-executing the same training bash, the performance becomes normal amazingly :
the result of the third time

These three experiments are running in the two same machines.
Environment (please complete the following information):
- OS: centos 7.4
- byteps version: 0.2.5
- CUDA and NCCL version: 11.0 and cuda 2.4.7
- Framework (TF, PyTorch, MXNet): Pytorch 1.4.0
- Model: VGG 19
- batch size: 128
The executing shell and docker are the same as https://github.com/bytedance/byteps/blob/master/docs/step-by-step-tutorial.md
Can you verify your RDMA performance using this benchmark? https://github.com/bytedance/ps-lite#2-benchmark-with-ipc-support
Using it to test, it is normal, otherwise I cannot get the stable result of the first and third times.