gradient computation has been modified by an inplace operation
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor [1, 1, 1, 7]], which is output 0 of AsStridedBackward0, is at version 2; expected version 1 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck
The problems seems lie in the function: class CausalConv1d(nn.Conv1d): def init(self, *args, **kwargs): super().init(*args, **kwargs) self.causal_padding = self.dilation[0] * (self.kernel_size[0] - 1)
def forward(self, x):
return self._conv_forward(F.pad(x, [self.causal_padding, 0]), self.weight, self.bias)
First train the discriminator then train the generator will solve this problem, but I am sure whether this will affect the training accuracy. I have read many GAN implementations, and there is a generator first version as well as a discriminator first version, so I am not sure. But I will let the network run and see what happens.
Can you get a good result?
I haven't started training yet, but I will update my results here as soon as I did it.
Hi, Thanks for your issue! I encountered this issue with inplace operation on other parts of the code. Some other might need a fix for that. Regarding the training orders of the components, I don't think there is any sort of consensus.
Hi, Thanks for your issue! I encountered this issue with inplace operation on other parts of the code. Some other might need a fix for that. Regarding the training orders of the components, I don't think there is any sort of consensus.
Thanks! I will pull my solution for the issues if it helps.
@wesbz @liuyoude One problem I found is that the loss of generator is significantly larger than the discriminator, for example: 6199809.67 vs 2.35. This might cause the non-convergence of the model?
Hi, To the best of my knowledge, since you have 2 losses and 2 optimizers, the differences in gradients' amplitudes shouldn't tell you much about the model's convergence. But one should always challenge his/her beliefs. What would you suggest? clipping the gradients?
@wesbz Yeah, I agree with what you said, sorry I rush to the conclusion. I am training the network now, I can see the loss of discriminator and generator are decreasing, but it's still so slow. I will update here once I found something, thanks again!
@wesbz @liuyoude One problem I found is that the loss of generator is significantly larger than the discriminator, for example: 6199809.67 vs 2.35. This might cause the non-convergence of the model?
yeah, the spectral reconstruction loss of the paper refers to GED loss(https://github.com/google-research/google-research/tree/68c738421186ce85339bfee16bf3ca2ea3ec16e4/ged_tts), I try to run it and the result is small. But the details of the code is different from in paper.
@wesbz @liuyoude Here are my loss curves:
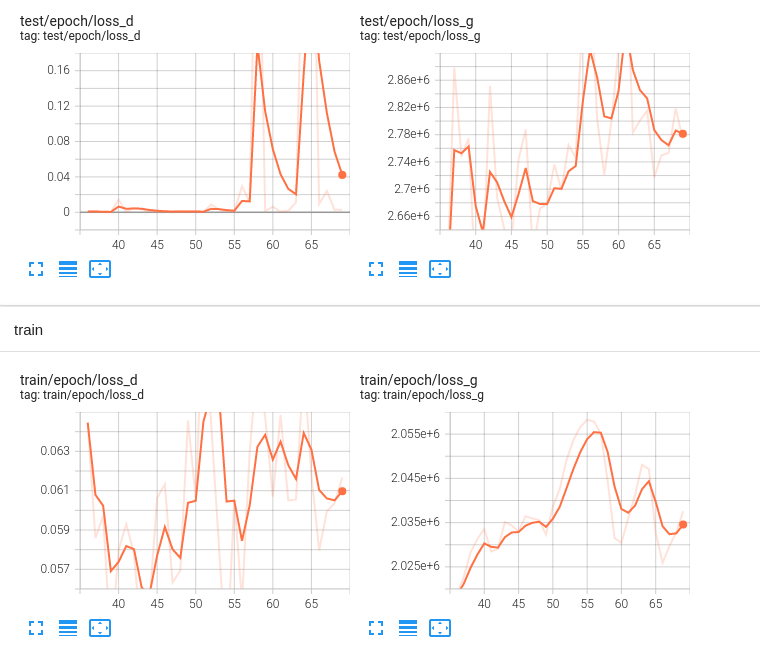 Any suggestions on why it didn't converge?
The superparameters are the same with paper implementations.
Any suggestions on why it didn't converge?
The superparameters are the same with paper implementations.
@MasterEndless any advances in convergence? I have the exact issue. I am training with LibriSpeech data, 3s normalized clips.
I found the implementation of generator loss is different from what the original paper says, and after modifying, I push the model for training, but still the generator is not converged yet...
@MasterEndless did you find a solution for convergence? Meta recently released their neural codec code but I got the same problem from their model also. The problem is with the convergence of the loss. I have tried with MSE loss of waveform, spectral loss as specified, and l1 and l2 loss of the waveform but all of them did result from a convergence of the loss.
@wesbz are you planning to work on the convergence of the model or did you find anything that may help us?
@liuyoude did you also find solution to spectral reconstruction loss???